 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotEQ: Transitioning from Passive Intelligence to Active Intelligence in Embodied AI
May 07, 2026Embodied AI is a prominent research topic in both academia and industry. Current research centers on completing tasks based on explicit user instructions. However, for robots to integrate into human society, they must understand which actions are permissible and which are prohibited, even without explicit commands. We refer to the user-guided AI as passive intelligence and the unguided AI as active intelligence. This paper introduces RobotEQ, the first benchmark for active intelligence, aiming to assess whether existing models can comprehend and adhere to social norms in embodied scenarios. First, we construct RobotEQ-Data, a dataset consisting of 1,900 egocentric images, spanning 10 representative embodied categories and 56 subcategories. Through extensive manual annotation, we provide 5,353 action judgment questions and 1,286 spatial grounding questions, specifying appropriate robot actions across diverse scenarios. Furthermore, we establish RobotEQ-Bench to evaluate the performance of state-of-the-art models on this task. Experimental results show that current models still fall short in achieving reliable active intelligence, particularly in spatial grounding. Meanwhile, we observe that leveraging RAG techniques to incorporate external social norm knowledge bases can generally enhance performance. This work can facilitate the transition of robotics from user-guided passive manipulation to active social compliance.
Unveiling Deep Semantic Uncertainty Perception for Language-Anchored Multi-modal Vision-Brain Alignment
Nov 06, 2025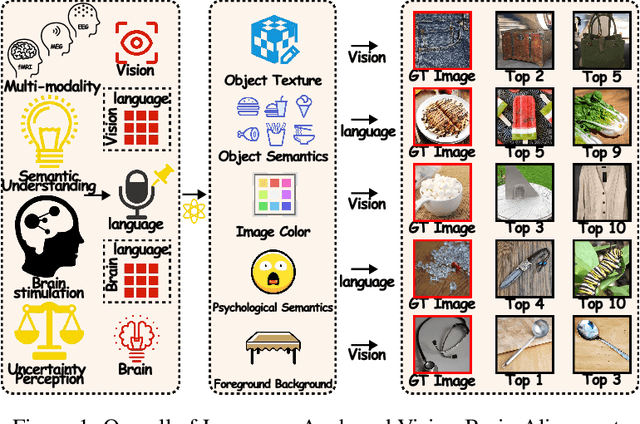
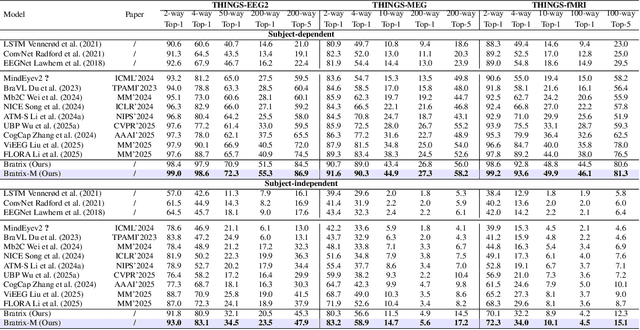
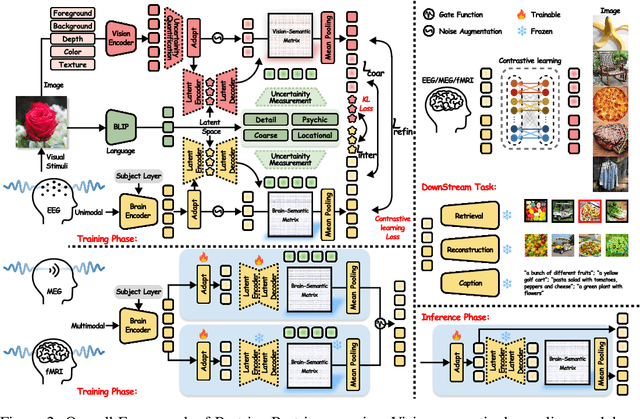
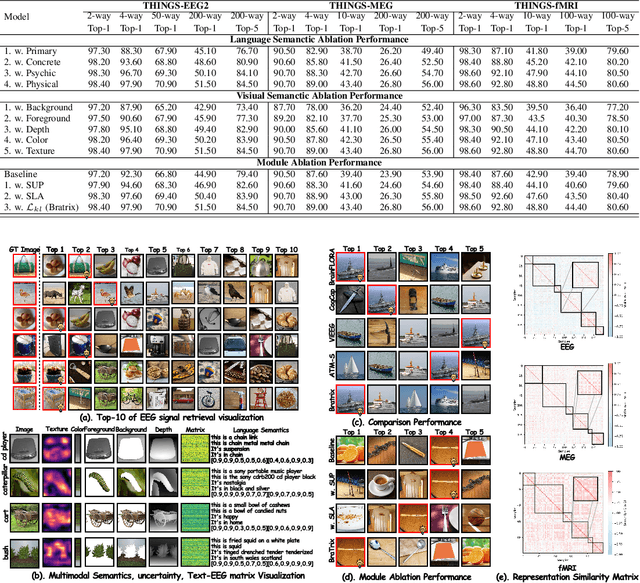
Unveiling visual semantics from neural signals such as EEG, MEG, and fMRI remains a fundamental challenge due to subject variability and the entangled nature of visual features. Existing approaches primarily align neural activity directly with visual embeddings, but visual-only representations often fail to capture latent semantic dimensions, limiting interpretability and deep robustness. To address these limitations, we propose Bratrix, the first end-to-end framework to achieve multimodal Language-Anchored Vision-Brain alignment. Bratrix decouples visual stimuli into hierarchical visual and linguistic semantic components, and projects both visual and brain representations into a shared latent space, enabling the formation of aligned visual-language and brain-language embeddings. To emulate human-like perceptual reliability and handle noisy neural signals, Bratrix incorporates a novel uncertainty perception module that applies uncertainty-aware weighting during alignment. By leveraging learnable language-anchored semantic matrices to enhance cross-modal correlations and employing a two-stage training strategy of single-modality pretraining followed by multimodal fine-tuning, Bratrix-M improves alignment precision. Extensive experiments on EEG, MEG, and fMRI benchmarks demonstrate that Bratrix improves retrieval, reconstruction, and captioning performance compared to state-of-the-art methods, specifically surpassing 14.3% in 200-way EEG retrieval task. Code and model are available.
STREAMINGGS: Voxel-Based Streaming 3D Gaussian Splatting with Memory Optimization and Architectural Support
Jun 09, 2025



3D Gaussian Splatting (3DGS) has gained popularity for its efficiency and sparse Gaussian-based representation. However, 3DGS struggles to meet the real-time requirement of 90 frames per second (FPS) on resource-constrained mobile devices, achieving only 2 to 9 FPS.Existing accelerators focus on compute efficiency but overlook memory efficiency, leading to redundant DRAM traffic. We introduce STREAMINGGS, a fully streaming 3DGS algorithm-architecture co-design that achieves fine-grained pipelining and reduces DRAM traffic by transforming from a tile-centric rendering to a memory-centric rendering. Results show that our design achieves up to 45.7 $\times$ speedup and 62.9 $\times$ energy savings over mobile Ampere GPUs.
ClusterKV: Manipulating LLM KV Cache in Semantic Space for Recallable Compression
Dec 04, 2024



Large Language Models (LLMs) have been widely deployed in a variety of applications, and the context length is rapidly increasing to handle tasks such as long-document QA and complex logical reasoning. However, long context poses significant challenges for inference efficiency, including high memory costs of key-value (KV) cache and increased latency due to extensive memory accesses. Recent works have proposed compressing KV cache to approximate computation, but these methods either evict tokens permanently, never recalling them for later inference, or recall previous tokens at the granularity of pages divided by textual positions. Both approaches degrade the model accuracy and output quality. To achieve efficient and accurate recallable KV cache compression, we introduce ClusterKV, which recalls tokens at the granularity of semantic clusters. We design and implement efficient algorithms and systems for clustering, selection, indexing and caching. Experiment results show that ClusterKV attains negligible accuracy loss across various tasks with 32k context lengths, using only a 1k to 2k KV cache budget, and achieves up to a 2$\times$ speedup in latency and a 2.5$\times$ improvement in decoding throughput. Compared to SoTA recallable KV compression methods, ClusterKV demonstrates higher model accuracy and output quality, while maintaining or exceeding inference efficiency.