 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Resampling with Learnable Heat Diffusion
Nov 21, 2024Generative diffusion models have shown empirical successes in point cloud resampling, generating a denser and more uniform distribution of points from sparse or noisy 3D point clouds by progressively refining noise into structure. However, existing diffusion models employ manually predefined schemes, which often fail to recover the underlying point cloud structure due to the rigid and disruptive nature of the geometric degradation. To address this issue, we propose a novel learnable heat diffusion framework for point cloud resampling, which directly parameterizes the marginal distribution for the forward process by learning the adaptive heat diffusion schedules and local filtering scales of the time-varying heat kernel, and consequently, generates an adaptive conditional prior for the reverse process. Unlike previous diffusion models with a fixed prior, the adaptive conditional prior selectively preserves geometric features of the point cloud by minimizing a refined variational lower bound, guiding the points to evolve towards the underlying surface during the reverse process. Extensive experimental results demonstrate that the proposed point cloud resampling achieves state-of-the-art performance in representative reconstruction tasks including point cloud denoising and upsampling.
Point Cloud Denoising With Fine-Granularity Dynamic Graph Convolutional Networks
Nov 21, 2024Due to limitations in acquisition equipment, noise perturbations often corrupt 3-D point clouds, hindering down-stream tasks such as surface reconstruction, rendering, and further processing. Existing 3-D point cloud denoising methods typically fail to reliably fit the underlying continuous surface, resulting in a degradation of reconstruction performance. This paper introduces fine-granularity dynamic graph convolutional networks called GD-GCN, a novel approach to denoising in 3-D point clouds. The GD-GCN employs micro-step temporal graph convolution (MST-GConv) to perform feature learning in a gradual manner. Compared with the conventional GCN, which commonly uses discrete integer-step graph convolution, this modification introduces a more adaptable and nuanced approach to feature learning within graph convolution networks. It more accurately depicts the process of fitting the point cloud with noise to the underlying surface by and the learning process for MST-GConv acts like a changing system and is managed through a type of neural network known as neural Partial Differential Equations (PDEs). This means it can adapt and improve over time. GD-GCN approximates the Riemannian metric, calculating distances between points along a low-dimensional manifold. This capability allows it to understand the local geometric structure and effectively capture diverse relationships between points from different geometric regions through geometric graph construction based on Riemannian distances. Additionally, GD-GCN incorporates robust graph spectral filters based on the Bernstein polynomial approximation, which modulate eigenvalues for complex and arbitrary spectral responses, providing theoretical guarantees for BIBO stability. Symmetric channel mixing matrices further enhance filter flexibility by enabling channel-level scaling and shifting in the spectral domain.
ColorEdit: Training-free Image-Guided Color editing with diffusion model
Nov 15, 2024



Text-to-image (T2I) diffusion models, with their impressive generative capabilities, have been adopted for image editing tasks, demonstrating remarkable efficacy. However, due to attention leakage and collision between the cross-attention map of the object and the new color attribute from the text prompt, text-guided image editing methods may fail to change the color of an object, resulting in a misalignment between the resulting image and the text prompt. In this paper, we conduct an in-depth analysis on the process of text-guided image synthesizing and what semantic information different cross-attention blocks have learned. We observe that the visual representation of an object is determined in the up-block of the diffusion model in the early stage of the denoising process, and color adjustment can be achieved through value matrices alignment in the cross-attention layer. Based on our findings, we propose a straightforward, yet stable, and effective image-guided method to modify the color of an object without requiring any additional fine-tuning or training. Lastly, we present a benchmark dataset called COLORBENCH, the first benchmark to evaluate the performance of color change methods. Extensive experiments validate the effectiveness of our method in object-level color editing and surpass the performance of popular text-guided image editing approaches in both synthesized and real images.
VCBench: A Controllable Benchmark for Symbolic and Abstract Challenges in Video Cognition
Nov 14, 2024



Recent advancements in Large Video-Language Models (LVLMs) have driven the development of benchmarks designed to assess cognitive abilities in video-based tasks. However, most existing benchmarks heavily rely on web-collected videos paired with human annotations or model-generated questions, which limit control over the video content and fall short in evaluating advanced cognitive abilities involving symbolic elements and abstract concepts. To address these limitations, we introduce VCBench, a controllable benchmark to assess LVLMs' cognitive abilities, involving symbolic and abstract concepts at varying difficulty levels. By generating video data with the Python-based engine, VCBench allows for precise control over the video content, creating dynamic, task-oriented videos that feature complex scenes and abstract concepts. Each task pairs with tailored question templates that target specific cognitive challenges, providing a rigorous evaluation test. Our evaluation reveals that even state-of-the-art (SOTA) models, such as Qwen2-VL-72B, struggle with simple video cognition tasks involving abstract concepts, with performance sharply dropping by 19% as video complexity rises. These findings reveal the current limitations of LVLMs in advanced cognitive tasks and highlight the critical role of VCBench in driving research toward more robust LVLMs for complex video cognition challenges.
Optimizing Instruction Synthesis: Effective Exploration of Evolutionary Space with Tree Search
Oct 14, 2024



Instruction tuning is a crucial technique for aligning language models with humans' actual goals in the real world. Extensive research has highlighted the quality of instruction data is essential for the success of this alignment. However, creating high-quality data manually is labor-intensive and time-consuming, which leads researchers to explore using LLMs to synthesize data. Recent studies have focused on using a stronger LLM to iteratively enhance existing instruction data, showing promising results. Nevertheless, previous work often lacks control over the evolution direction, resulting in high uncertainty in the data synthesis process and low-quality instructions. In this paper, we introduce a general and scalable framework, IDEA-MCTS (Instruction Data Enhancement using Monte Carlo Tree Search), a scalable framework for efficiently synthesizing instructions. With tree search and evaluation models, it can efficiently guide each instruction to evolve into a high-quality form, aiding in instruction fine-tuning. Experimental results show that IDEA-MCTS significantly enhances the seed instruction data, raising the average evaluation scores of quality, diversity, and complexity from 2.19 to 3.81. Furthermore, in open-domain benchmarks, experimental results show that IDEA-MCTS improves the accuracy of real-world instruction-following skills in LLMs by an average of 5\% in low-resource settings.
Image Compression for Machine and Human Vision with Spatial-Frequency Adaptation
Jul 13, 2024



Image compression for machine and human vision (ICMH) has gained increasing attention in recent years. Existing ICMH methods are limited by high training and storage overheads due to heavy design of task-specific networks. To address this issue, in this paper, we develop a novel lightweight adapter-based tuning framework for ICMH, named Adapt-ICMH, that better balances task performance and bitrates with reduced overheads. We propose a spatial-frequency modulation adapter (SFMA) that simultaneously eliminates non-semantic redundancy with a spatial modulation adapter, and enhances task-relevant frequency components and suppresses task-irrelevant frequency components with a frequency modulation adapter. The proposed adapter is plug-and-play and compatible with almost all existing learned image compression models without compromising the performance of pre-trained models. Experiments demonstrate that Adapt-ICMH consistently outperforms existing ICMH frameworks on various machine vision tasks with fewer fine-tuned parameters and reduced computational complexity. Code will be released at https://github.com/qingshi9974/ECCV2024-AdpatICMH .
CTRL: Continuous-Time Representation Learning on Temporal Heterogeneous Information Network
May 11, 2024


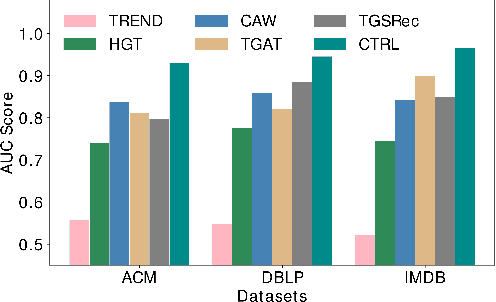
Inductive representation learning on temporal heterogeneous graphs is crucial for scalable deep learning on heterogeneous information networks (HINs) which are time-varying, such as citation networks. However, most existing approaches are not inductive and thus cannot handle new nodes or edges. Moreover, previous temporal graph embedding methods are often trained with the temporal link prediction task to simulate the link formation process of temporal graphs, while ignoring the evolution of high-order topological structures on temporal graphs. To fill these gaps, we propose a Continuous-Time Representation Learning (CTRL) model on temporal HINs. To preserve heterogeneous node features and temporal structures, CTRL integrates three parts in a single layer, they are 1) a \emph{heterogeneous attention} unit that measures the semantic correlation between nodes, 2) a \emph{edge-based Hawkes process} to capture temporal influence between heterogeneous nodes, and 3) \emph{dynamic centrality} that indicates the dynamic importance of a node. We train the CTRL model with a future event (a subgraph) prediction task to capture the evolution of the high-order network structure. Extensive experiments have been conducted on three benchmark datasets. The results demonstrate that our model significantly boosts performance and outperforms various state-of-the-art approaches. Ablation studies are conducted to demonstrate the effectiveness of the model design.
Improving Diffusion Models for Inverse Problems Using Optimal Posterior Covariance
Feb 03, 2024



Recent diffusion models provide a promising zero-shot solution to noisy linear inverse problems without retraining for specific inverse problems. In this paper, we propose the first unified interpretation for existing zero-shot methods from the perspective of approximating the conditional posterior mean for the reverse diffusion process of conditional sampling. We reveal that recent methods are equivalent to making isotropic Gaussian approximations to intractable posterior distributions over clean images given diffused noisy images, with the only difference in the handcrafted design of isotropic posterior covariances. Inspired by this finding, we propose a general plug-and-play posterior covariance optimization based on maximum likelihood estimation to improve recent methods. To achieve optimal posterior covariance without retraining, we provide general solutions based on two approaches specifically designed to leverage pre-trained models with and without reverse covariances. Experimental results demonstrate that the proposed methods significantly enhance the overall performance or robustness to hyperparameters of recent methods. Code is available at https://github.com/xypeng9903/k-diffusion-inverse-problems
scBiGNN: Bilevel Graph Representation Learning for Cell Type Classification from Single-cell RNA Sequencing Data
Dec 16, 2023Single-cell RNA sequencing (scRNA-seq) technology provides high-throughput gene expression data to study the cellular heterogeneity and dynamics of complex organisms. Graph neural networks (GNNs) have been widely used for automatic cell type classification, which is a fundamental problem to solve in scRNA-seq analysis. However, existing methods do not sufficiently exploit both gene-gene and cell-cell relationships, and thus the true potential of GNNs is not realized. In this work, we propose a bilevel graph representation learning method, named scBiGNN, to simultaneously mine the relationships at both gene and cell levels for more accurate single-cell classification. Specifically, scBiGNN comprises two GNN modules to identify cell types. A gene-level GNN is established to adaptively learn gene-gene interactions and cell representations via the self-attention mechanism, and a cell-level GNN builds on the cell-cell graph that is constructed from the cell representations generated by the gene-level GNN. To tackle the scalability issue for processing a large number of cells, scBiGNN adopts an Expectation Maximization (EM) framework in which the two modules are alternately trained via the E-step and M-step to learn from each other. Through this interaction, the gene- and cell-level structural information is integrated to gradually enhance the classification performance of both GNN modules. Experiments on benchmark datasets demonstrate that our scBiGNN outperforms a variety of existing methods for cell type classification from scRNA-seq data.
AiluRus: A Scalable ViT Framework for Dense Prediction
Nov 02, 2023Vision transformers (ViTs) have emerged as a prevalent architecture for vision tasks owing to their impressive performance. However, when it comes to handling long token sequences, especially in dense prediction tasks that require high-resolution input, the complexity of ViTs increases significantly. Notably, dense prediction tasks, such as semantic segmentation or object detection, emphasize more on the contours or shapes of objects, while the texture inside objects is less informative. Motivated by this observation, we propose to apply adaptive resolution for different regions in the image according to their importance. Specifically, at the intermediate layer of the ViT, we utilize a spatial-aware density-based clustering algorithm to select representative tokens from the token sequence. Once the representative tokens are determined, we proceed to merge other tokens into their closest representative token. Consequently, semantic similar tokens are merged together to form low-resolution regions, while semantic irrelevant tokens are preserved independently as high-resolution regions. This strategy effectively reduces the number of tokens, allowing subsequent layers to handle a reduced token sequence and achieve acceleration. We evaluate our proposed method on three different datasets and observe promising performance. For example, the "Segmenter ViT-L" model can be accelerated by 48% FPS without fine-tuning, while maintaining the performance. Additionally, our method can be applied to accelerate fine-tuning as well. Experimental results demonstrate that we can save 52% training time while accelerating 2.46 times FPS with only a 0.09% performance drop. The code is available at https://github.com/caddyless/ailurus/tree/main.