 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineViT: Progressively Unlocking Fine-Grained Perception with Dense Recaptions
Mar 18, 2026While Multimodal Large Language Models (MLLMs) have experienced rapid advancements, their visual encoders frequently remain a performance bottleneck. Conventional CLIP-based encoders struggle with dense spatial tasks due to the loss of visual details caused by low-resolution pretraining and the reliance on noisy, coarse web-crawled image-text pairs. To overcome these limitations, we introduce FineViT, a novel vision encoder specifically designed to unlock fine-grained perception. By replacing coarse web data with dense recaptions, we systematically mitigate information loss through a progressive training paradigm.: first, the encoder is trained from scratch at a high native resolution on billions of global recaptioned image-text pairs, establishing a robust, detail rich semantic foundation. Subsequently, we further enhance its local perception through LLM alignment, utilizing our curated FineCap-450M dataset that comprises over $450$ million high quality local captions. Extensive experiments validate the effectiveness of the progressive strategy. FineViT achieves state-of-the-art zero-shot recognition and retrieval performance, especially in long-context retrieval, and consistently outperforms multimodal visual encoders such as SigLIP2 and Qwen-ViT when integrated into MLLMs. We hope FineViT could serve as a powerful new baseline for fine-grained visual perception.
Low-Rank and Sparse Model Merging for Multi-Lingual Speech Recognition and Translation
Feb 26, 2025Language diversity presents a significant challenge in speech-to-text (S2T) tasks, such as automatic speech recognition and translation. Traditional multi-task training approaches aim to address this by jointly optimizing multiple speech recognition and translation tasks across various languages. While models like Whisper, built on these strategies, demonstrate strong performance, they still face issues of high computational cost, language interference, suboptimal training configurations, and limited extensibility. To overcome these challenges, we introduce LoRS-Merging (low-rank and sparse model merging), a novel technique designed to efficiently integrate models trained on different languages or tasks while preserving performance and reducing computational overhead. LoRS-Merging combines low-rank and sparse pruning to retain essential structures while eliminating redundant parameters, mitigating language and task interference, and enhancing extensibility. Experimental results across a range of languages demonstrate that LoRS-Merging reduces the word error rate by 10% and improves BLEU scores by 4% compared to conventional multi-lingual multi-task training baselines. Our findings suggest that model merging, particularly LoRS-Merging, is a scalable and effective complement to traditional multi-lingual training strategies for S2T applications.
Whisper-PMFA: Partial Multi-Scale Feature Aggregation for Speaker Verification using Whisper Models
Aug 28, 2024



In this paper, Whisper, a large-scale pre-trained model for automatic speech recognition, is proposed to apply to speaker verification. A partial multi-scale feature aggregation (PMFA) approach is proposed based on a subset of Whisper encoder blocks to derive highly discriminative speaker embeddings.Experimental results demonstrate that using the middle to later blocks of the Whisper encoder keeps more speaker information. On the VoxCeleb1 and CN-Celeb1 datasets, our system achieves 1.42% and 8.23% equal error rates (EERs) respectively, receiving 0.58% and 1.81% absolute EER reductions over the ECAPA-TDNN baseline, and 0.46% and 0.97% over the ResNet34 baseline. Furthermore, our results indicate that using Whisper models trained on multilingual data can effectively enhance the model's robustness across languages. Finally, the low-rank adaptation approach is evaluated, which reduces the trainable model parameters by approximately 45 times while only slightly increasing EER by 0.2%.
A Joint Noise Disentanglement and Adversarial Training Framework for Robust Speaker Verification
Aug 22, 2024



Automatic Speaker Verification (ASV) suffers from performance degradation in noisy conditions. To address this issue, we propose a novel adversarial learning framework that incorporates noise-disentanglement to establish a noise-independent speaker invariant embedding space. Specifically, the disentanglement module includes two encoders for separating speaker related and irrelevant information, respectively. The reconstruction module serves as a regularization term to constrain the noise. A feature-robust loss is also used to supervise the speaker encoder to learn noise-independent speaker embeddings without losing speaker information. In addition, adversarial training is introduced to discourage the speaker encoder from encoding acoustic condition information for achieving a speaker-invariant embedding space. Experiments on VoxCeleb1 indicate that the proposed method improves the performance of the speaker verification system under both clean and noisy conditions.
Speaker Adaptation for Quantised End-to-End ASR Models
Aug 07, 2024

End-to-end models have shown superior performance for automatic speech recognition (ASR). However, such models are often very large in size and thus challenging to deploy on resource-constrained edge devices. While quantisation can reduce model sizes, it can lead to increased word error rates (WERs). Although improved quantisation methods were proposed to address the issue of performance degradation, the fact that quantised models deployed on edge devices often target only on a small group of users is under-explored. To this end, we propose personalisation for quantised models (P4Q), a novel strategy that uses speaker adaptation (SA) to improve quantised end-to-end ASR models by fitting them to the characteristics of the target speakers. In this paper, we study the P4Q strategy based on Whisper and Conformer attention-based encoder-decoder (AED) end-to-end ASR models, which leverages a 4-bit block-wise NormalFloat4 (NF4) approach for quantisation and the low-rank adaptation (LoRA) approach for SA. Experimental results on the LibriSpeech and the TED-LIUM 3 corpora show that, with a 7-time reduction in model size and 1% extra speaker-specific parameters, 15.1% and 23.3% relative WER reductions were achieved on quantised Whisper and Conformer AED models respectively, comparing to the full precision models.
SAML: Speaker Adaptive Mixture of LoRA Experts for End-to-End ASR
Jun 28, 2024



Mixture-of-experts (MoE) models have achieved excellent results in many tasks. However, conventional MoE models are often very large, making them challenging to deploy on resource-constrained edge devices. In this paper, we propose a novel speaker adaptive mixture of LoRA experts (SAML) approach, which uses low-rank adaptation (LoRA) modules as experts to reduce the number of trainable parameters in MoE. Specifically, SAML is applied to the quantised and personalised end-to-end automatic speech recognition models, which combines test-time speaker adaptation to improve the performance of heavily compressed models in speaker-specific scenarios. Experiments have been performed on the LibriSpeech and the TED-LIUM 3 corpora. Remarkably, with a 7x reduction in model size, 29.1% and 31.1% relative word error rate reductions were achieved on the quantised Whisper model and Conformer-based attention-based encoder-decoder ASR model respectively, comparing to the original full precision models.
Enhancing Quantised End-to-End ASR Models via Personalisation
Sep 17, 2023Recent end-to-end automatic speech recognition (ASR) models have become increasingly larger, making them particularly challenging to be deployed on resource-constrained devices. Model quantisation is an effective solution that sometimes causes the word error rate (WER) to increase. In this paper, a novel strategy of personalisation for a quantised model (PQM) is proposed, which combines speaker adaptive training (SAT) with model quantisation to improve the performance of heavily compressed models. Specifically, PQM uses a 4-bit NormalFloat Quantisation (NF4) approach for model quantisation and low-rank adaptation (LoRA) for SAT. Experiments have been performed on the LibriSpeech and the TED-LIUM 3 corpora. Remarkably, with a 7x reduction in model size and 1% additional speaker-specific parameters, 15.1% and 23.3% relative WER reductions were achieved on quantised Whisper and Conformer-based attention-based encoder-decoder ASR models respectively, comparing to the original full precision models.
Hierarchical Spherical CNNs with Lifting-based Adaptive Wavelets for Pooling and Unpooling
May 31, 2022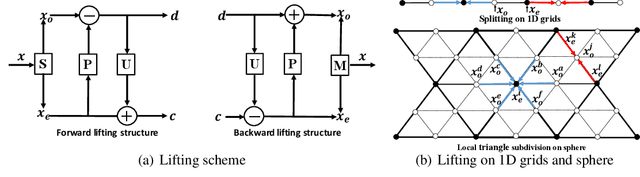
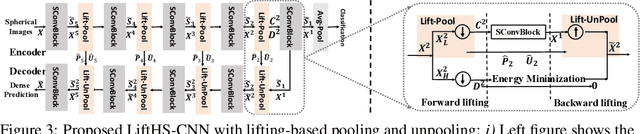


Pooling and unpooling are two essential operations in constructing hierarchical spherical convolutional neural networks (HS-CNNs) for comprehensive feature learning in the spherical domain. Most existing models employ downsampling-based pooling, which will inevitably incur information loss and cannot adapt to different spherical signals and tasks. Besides, the preserved information after pooling cannot be well restored by the subsequent unpooling to characterize the desirable features for a task. In this paper, we propose a novel framework of HS-CNNs with a lifting structure to learn adaptive spherical wavelets for pooling and unpooling, dubbed LiftHS-CNN, which ensures a more efficient hierarchical feature learning for both image- and pixel-level tasks. Specifically, adaptive spherical wavelets are learned with a lifting structure that consists of trainable lifting operators (i.e., update and predict operators). With this learnable lifting structure, we can adaptively partition a signal into two sub-bands containing low- and high-frequency components, respectively, and thus generate a better down-scaled representation for pooling by preserving more information in the low-frequency sub-band. The update and predict operators are parameterized with graph-based attention to jointly consider the signal's characteristics and the underlying geometries. We further show that particular properties are promised by the learned wavelets, ensuring the spatial-frequency localization for better exploiting the signal's correlation in both spatial and frequency domains. We then propose an unpooling operation that is invertible to the lifting-based pooling, where an inverse wavelet transform is performed by using the learned lifting operators to restore an up-scaled representation. Extensive empirical evaluations on various spherical domain tasks validate the superiority of the proposed LiftHS-CNN.
LiftPool: Lifting-based Graph Pooling for Hierarchical Graph Representation Learning
Apr 27, 2022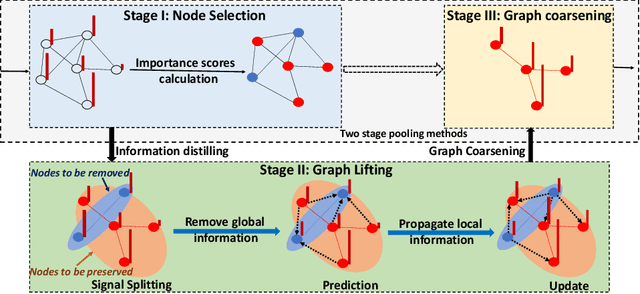
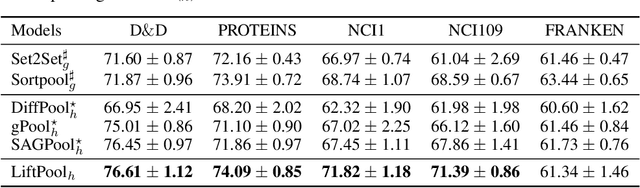
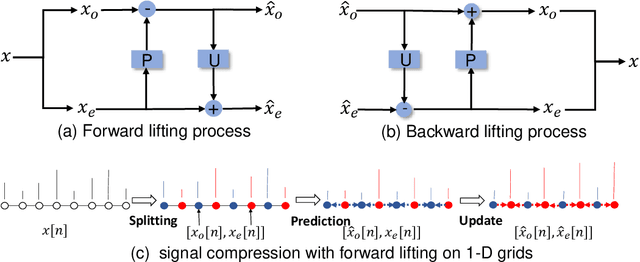
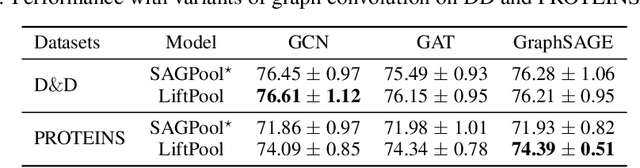
Graph pooling has been increasingly considered for graph neural networks (GNNs) to facilitate hierarchical graph representation learning. Existing graph pooling methods commonly consist of two stages, i.e., selecting the top-ranked nodes and removing the rest nodes to construct a coarsened graph representation. However, local structural information of the removed nodes would be inevitably dropped in these methods, due to the inherent coupling of nodes (location) and their features (signals). In this paper, we propose an enhanced three-stage method via lifting, named LiftPool, to improve hierarchical graph representation by maximally preserving the local structural information in graph pooling. LiftPool introduces an additional stage of graph lifting before graph coarsening to preserve the local information of the removed nodes and decouple the processes of node removing and feature reduction. Specifically, for each node to be removed, its local information is obtained by subtracting the global information aggregated from its neighboring preserved nodes. Subsequently, this local information is aligned and propagated to the preserved nodes to alleviate information loss in graph coarsening. Furthermore, we demonstrate that the proposed LiftPool is localized and permutation-invariant. The proposed graph lifting structure is general to be integrated with existing downsampling-based graph pooling methods. Evaluations on benchmark graph datasets show that LiftPool substantially outperforms the state-of-the-art graph pooling methods in the task of graph classification.
Learning from Multiple Noisy Augmented Data Sets for Better Cross-Lingual Spoken Language Understanding
Sep 03, 2021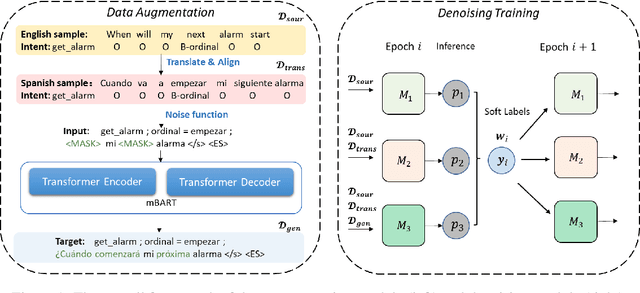
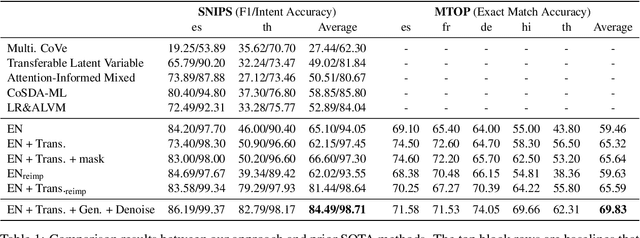
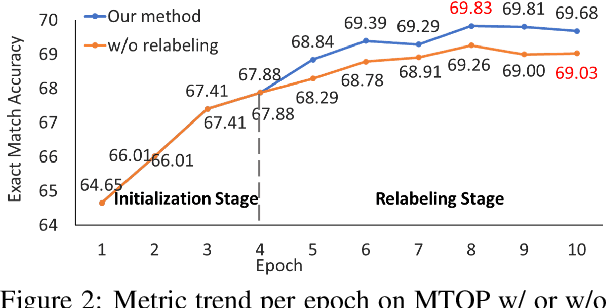
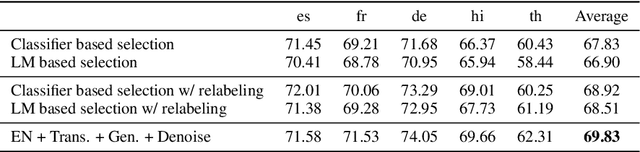
Lack of training data presents a grand challenge to scaling out spoken language understanding (SLU) to low-resource languages. Although various data augmentation approaches have been proposed to synthesize training data in low-resource target languages, the augmented data sets are often noisy, and thus impede the performance of SLU models. In this paper we focus on mitigating noise in augmented data. We develop a denoising training approach. Multiple models are trained with data produced by various augmented methods. Those models provide supervision signals to each other. The experimental results show that our method outperforms the existing state of the art by 3.05 and 4.24 percentage points on two benchmark datasets, respectively. The code will be made open sourced on github.