 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoFM: Foundation Model for Generalizable Echocardiogram Analysis
Oct 30, 2024



Foundation models have recently gained significant attention because of their generalizability and adaptability across multiple tasks and data distributions. Although medical foundation models have emerged, solutions for cardiac imaging, especially echocardiography videos, are still unexplored. In this paper, we introduce EchoFM, a foundation model specifically designed to represent and analyze echocardiography videos. In EchoFM, we propose a self-supervised learning framework that captures both spatial and temporal variability patterns through a spatio-temporal consistent masking strategy and periodic-driven contrastive learning. This framework can effectively capture the spatio-temporal dynamics of echocardiography and learn the representative video features without any labels. We pre-train our model on an extensive dataset comprising over 290,000 echocardiography videos covering 26 scan views across different imaging modes, with up to 20 million frames of images. The pre-trained EchoFM can then be easily adapted and fine-tuned for a variety of downstream tasks, serving as a robust backbone model. Our evaluation was systemically designed for four downstream tasks after the echocardiography examination routine. Experiment results show that EchoFM surpasses state-of-the-art methods, including specialized echocardiography methods, self-supervised pre-training models, and general-purposed pre-trained foundation models, across all downstream tasks.
Retrieval Instead of Fine-tuning: A Retrieval-based Parameter Ensemble for Zero-shot Learning
Oct 13, 2024



Foundation models have become a cornerstone in deep learning, with techniques like Low-Rank Adaptation (LoRA) offering efficient fine-tuning of large models. Similarly, methods such as Retrieval-Augmented Generation (RAG), which leverage vectorized databases, have further improved model performance by grounding outputs in external information. While these approaches have demonstrated notable success, they often require extensive training or labeled data, which can limit their adaptability in resource-constrained environments. To address these challenges, we introduce Retrieval-based Parameter Ensemble (RPE), a new method that creates a vectorized database of LoRAs, enabling efficient retrieval and application of model adaptations to new tasks. RPE minimizes the need for extensive training and eliminates the requirement for labeled data, making it particularly effective for zero-shot learning. Additionally, RPE is well-suited for privacy-sensitive domains like healthcare, as it modifies model parameters without accessing raw data. When applied to tasks such as medical report generation and image segmentation, RPE not only proved effective but also surpassed supervised fine-tuning methods in certain cases, highlighting its potential to enhance both computational efficiency and privacy in deep learning applications.
A Novel Approach to Malicious Code Detection Using CNN-BiLSTM and Feature Fusion
Oct 12, 2024With the rapid advancement of Internet technology, the threat of malware to computer systems and network security has intensified. Malware affects individual privacy and security and poses risks to critical infrastructures of enterprises and nations. The increasing quantity and complexity of malware, along with its concealment and diversity, challenge traditional detection techniques. Static detection methods struggle against variants and packed malware, while dynamic methods face high costs and risks that limit their application. Consequently, there is an urgent need for novel and efficient malware detection techniques to improve accuracy and robustness. This study first employs the minhash algorithm to convert binary files of malware into grayscale images, followed by the extraction of global and local texture features using GIST and LBP algorithms. Additionally, the study utilizes IDA Pro to decompile and extract opcode sequences, applying N-gram and tf-idf algorithms for feature vectorization. The fusion of these features enables the model to comprehensively capture the behavioral characteristics of malware. In terms of model construction, a CNN-BiLSTM fusion model is designed to simultaneously process image features and opcode sequences, enhancing classification performance. Experimental validation on multiple public datasets demonstrates that the proposed method significantly outperforms traditional detection techniques in terms of accuracy, recall, and F1 score, particularly in detecting variants and obfuscated malware with greater stability. The research presented in this paper offers new insights into the development of malware detection technologies, validating the effectiveness of feature and model fusion, and holds promising application prospects.
Prim2Room: Layout-Controllable Room Mesh Generation from Primitives
Sep 09, 2024We propose Prim2Room, a novel framework for controllable room mesh generation leveraging 2D layout conditions and 3D primitive retrieval to facilitate precise 3D layout specification. Diverging from existing methods that lack control and precision, our approach allows for detailed customization of room-scale environments. To overcome the limitations of previous methods, we introduce an adaptive viewpoint selection algorithm that allows the system to generate the furniture texture and geometry from more favorable views than predefined camera trajectories. Additionally, we employ non-rigid depth registration to ensure alignment between generated objects and their corresponding primitive while allowing for shape variations to maintain diversity. Our method not only enhances the accuracy and aesthetic appeal of generated 3D scenes but also provides a user-friendly platform for detailed room design.
Low-Bitwidth Floating Point Quantization for Efficient High-Quality Diffusion Models
Aug 13, 2024



Diffusion models are emerging models that generate images by iteratively denoising random Gaussian noise using deep neural networks. These models typically exhibit high computational and memory demands, necessitating effective post-training quantization for high-performance inference. Recent works propose low-bitwidth (e.g., 8-bit or 4-bit) quantization for diffusion models, however 4-bit integer quantization typically results in low-quality images. We observe that on several widely used hardware platforms, there is little or no difference in compute capability between floating-point and integer arithmetic operations of the same bitwidth (e.g., 8-bit or 4-bit). Therefore, we propose an effective floating-point quantization method for diffusion models that provides better image quality compared to integer quantization methods. We employ a floating-point quantization method that was effective for other processing tasks, specifically computer vision and natural language tasks, and tailor it for diffusion models by integrating weight rounding learning during the mapping of the full-precision values to the quantized values in the quantization process. We comprehensively study integer and floating-point quantization methods in state-of-the-art diffusion models. Our floating-point quantization method not only generates higher-quality images than that of integer quantization methods, but also shows no noticeable degradation compared to full-precision models (32-bit floating-point), when both weights and activations are quantized to 8-bit floating-point values, while has minimal degradation with 4-bit weights and 8-bit activations.
FM-OSD: Foundation Model-Enabled One-Shot Detection of Anatomical Landmarks
Jul 07, 2024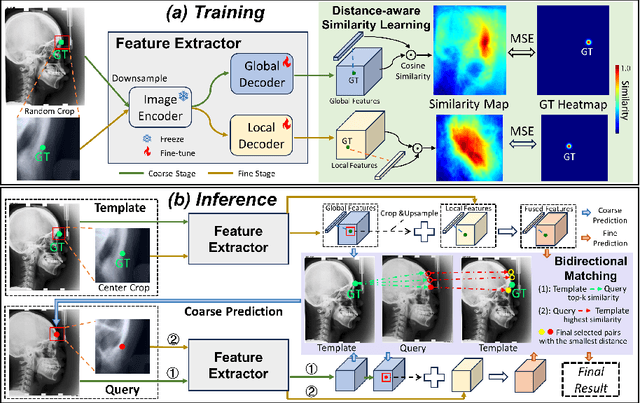


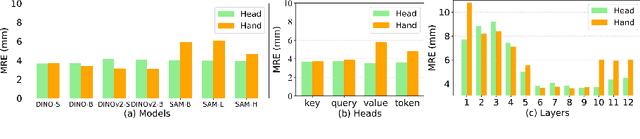
One-shot detection of anatomical landmarks is gaining significant attention for its efficiency in using minimal labeled data to produce promising results. However, the success of current methods heavily relies on the employment of extensive unlabeled data to pre-train an effective feature extractor, which limits their applicability in scenarios where a substantial amount of unlabeled data is unavailable. In this paper, we propose the first foundation model-enabled one-shot landmark detection (FM-OSD) framework for accurate landmark detection in medical images by utilizing solely a single template image without any additional unlabeled data. Specifically, we use the frozen image encoder of visual foundation models as the feature extractor, and introduce dual-branch global and local feature decoders to increase the resolution of extracted features in a coarse to fine manner. The introduced feature decoders are efficiently trained with a distance-aware similarity learning loss to incorporate domain knowledge from the single template image. Moreover, a novel bidirectional matching strategy is developed to improve both robustness and accuracy of landmark detection in the case of scattered similarity map obtained by foundation models. We validate our method on two public anatomical landmark detection datasets. By using solely a single template image, our method demonstrates significant superiority over strong state-of-the-art one-shot landmark detection methods.
Cross Prompting Consistency with Segment Anything Model for Semi-supervised Medical Image Segmentation
Jul 07, 2024



Semi-supervised learning (SSL) has achieved notable progress in medical image segmentation. To achieve effective SSL, a model needs to be able to efficiently learn from limited labeled data and effectively exploiting knowledge from abundant unlabeled data. Recent developments in visual foundation models, such as the Segment Anything Model (SAM), have demonstrated remarkable adaptability with improved sample efficiency. To harness the power of foundation models for application in SSL, we propose a cross prompting consistency method with segment anything model (CPC-SAM) for semi-supervised medical image segmentation. Our method employs SAM's unique prompt design and innovates a cross-prompting strategy within a dual-branch framework to automatically generate prompts and supervisions across two decoder branches, enabling effectively learning from both scarce labeled and valuable unlabeled data. We further design a novel prompt consistency regularization, to reduce the prompt position sensitivity and to enhance the output invariance under different prompts. We validate our method on two medical image segmentation tasks. The extensive experiments with different labeled-data ratios and modalities demonstrate the superiority of our proposed method over the state-of-the-art SSL methods, with more than 9% Dice improvement on the breast cancer segmentation task.
Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024



The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.
Text-to-Image Rectified Flow as Plug-and-Play Priors
Jun 05, 2024



Large-scale diffusion models have achieved remarkable performance in generative tasks. Beyond their initial training applications, these models have proven their ability to function as versatile plug-and-play priors. For instance, 2D diffusion models can serve as loss functions to optimize 3D implicit models. Rectified flow, a novel class of generative models, enforces a linear progression from the source to the target distribution and has demonstrated superior performance across various domains. Compared to diffusion-based methods, rectified flow approaches surpass in terms of generation quality and efficiency, requiring fewer inference steps. In this work, we present theoretical and experimental evidence demonstrating that rectified flow based methods offer similar functionalities to diffusion models - they can also serve as effective priors. Besides the generative capabilities of diffusion priors, motivated by the unique time-symmetry properties of rectified flow models, a variant of our method can additionally perform image inversion. Experimentally, our rectified flow-based priors outperform their diffusion counterparts - the SDS and VSD losses - in text-to-3D generation. Our method also displays competitive performance in image inversion and editing.
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Jun 04, 2024



Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.