 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisplacement Is Not Direction: Evaluating Fidelity Metrics for Quantized LLM Deployment
Jun 17, 2026Fidelity metrics, such as per-token KL divergence (KLD) against a high-precision reference, are often used in practice as low-cost proxies for benchmark quality. We test this practice on a 28-quant cohort of Qwen3.6-35B-A3B and a 41-quant cohort of Devstral-Small-2-24B, evaluated across a suite of downstream benchmarks. We find that KLD is strongly correlated with benchmark score over the full cohort ($ρ=-0.72$ on Qwen and $ρ=-0.86$ on Devstral, both with $p<0.001$). However, this relationship collapses to non-significance in the near-baseline silent zone ($ρ=+0.00$ on Qwen and $ρ=-0.24$, $p=0.36$, on Devstral). This collapse persists across 14 measurement variants, including different KLD aggregations, perplexity formulations, top-1 agreement, calibration corpora, and context lengths. At the per-prompt level, KLD has only weak failure-prediction power on code, with failed-vs-passed geometric-mean ratios in $[1.08,1.22]$ across five models on LiveCodeBench, and fails as a cross-model router, achieving only $42.3\%-49.4\%$ accuracy on disagreement prompts. We trace the collapse to a structural decomposition: KLD primarily measures the volume of disagreement with the reference, with silent-zone composite $ρ=+0.94$ ($p<0.001$) on Qwen and $+0.55$ ($p=0.03$) on Devstral, while its relationship to the direction of those disagreements is weak and task-conditional.
Low-Bitwidth Floating Point Quantization for Efficient High-Quality Diffusion Models
Aug 13, 2024



Diffusion models are emerging models that generate images by iteratively denoising random Gaussian noise using deep neural networks. These models typically exhibit high computational and memory demands, necessitating effective post-training quantization for high-performance inference. Recent works propose low-bitwidth (e.g., 8-bit or 4-bit) quantization for diffusion models, however 4-bit integer quantization typically results in low-quality images. We observe that on several widely used hardware platforms, there is little or no difference in compute capability between floating-point and integer arithmetic operations of the same bitwidth (e.g., 8-bit or 4-bit). Therefore, we propose an effective floating-point quantization method for diffusion models that provides better image quality compared to integer quantization methods. We employ a floating-point quantization method that was effective for other processing tasks, specifically computer vision and natural language tasks, and tailor it for diffusion models by integrating weight rounding learning during the mapping of the full-precision values to the quantized values in the quantization process. We comprehensively study integer and floating-point quantization methods in state-of-the-art diffusion models. Our floating-point quantization method not only generates higher-quality images than that of integer quantization methods, but also shows no noticeable degradation compared to full-precision models (32-bit floating-point), when both weights and activations are quantized to 8-bit floating-point values, while has minimal degradation with 4-bit weights and 8-bit activations.
Schrödinger's FP: Dynamic Adaptation of Floating-Point Containers for Deep Learning Training
Apr 28, 2022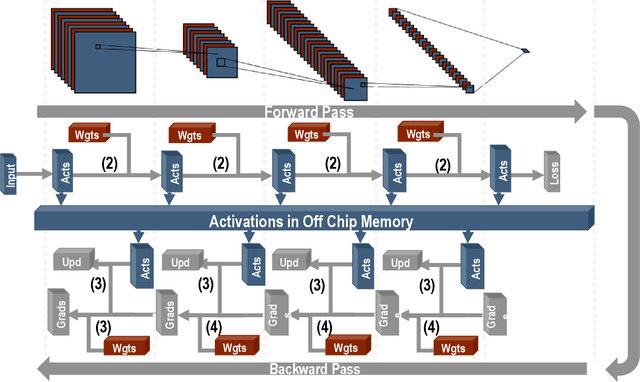
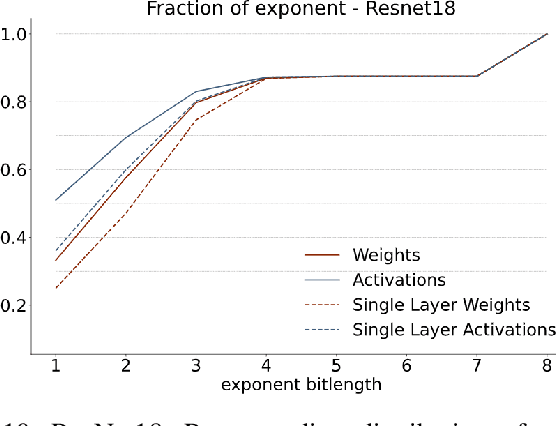
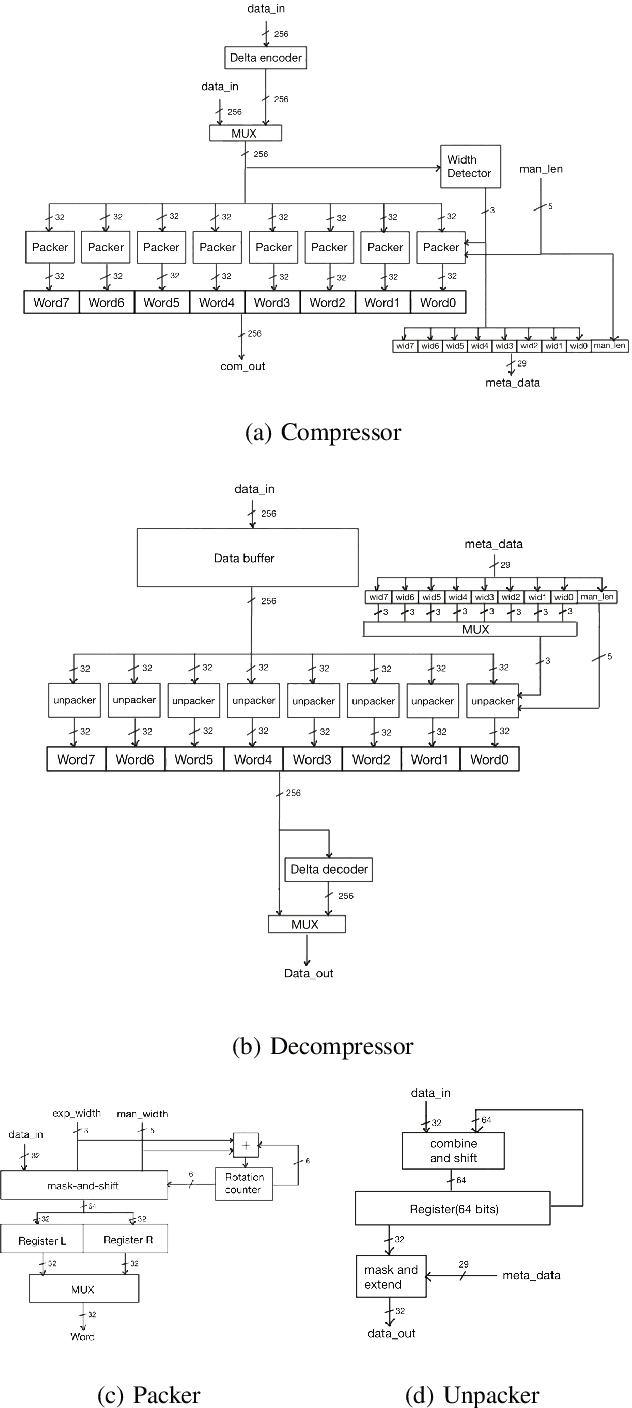
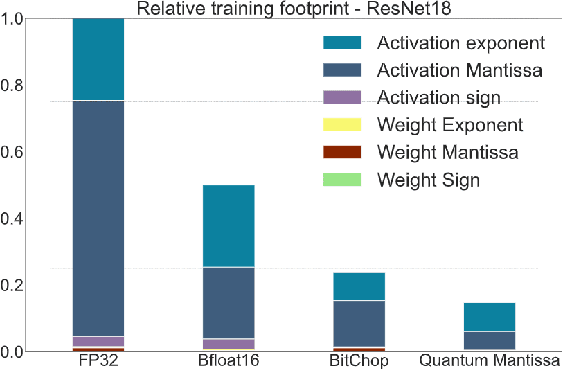
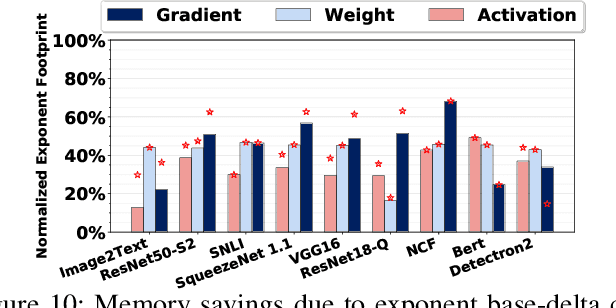
We introduce a software-hardware co-design approach to reduce memory traffic and footprint during training with BFloat16 or FP32 boosting energy efficiency and execution time performance. We introduce methods to dynamically adjust the size and format of the floating-point containers used to store activations and weights during training. The different value distributions lead us to different approaches for exponents and mantissas. Gecko exploits the favourable exponent distribution with a loss-less delta encoding approach to reduce the total exponent footprint by up to $58\%$ in comparison to a 32 bit floating point baseline. To content with the noisy mantissa distributions, we present two lossy methods to eliminate as many as possible least significant bits while not affecting accuracy. Quantum Mantissa, is a machine learning-first mantissa compression method that taps on training's gradient descent algorithm to also learn minimal mantissa bitlengths on a per-layer granularity, and obtain up to $92\%$ reduction in total mantissa footprint. Alternatively, BitChop observes changes in the loss function during training to adjust mantissa bit-length network-wide yielding a reduction of $81\%$ in footprint. Schr\"{o}dinger's FP implements hardware encoders/decoders that guided by Gecko/Quantum Mantissa or Gecko/BitChop transparently encode/decode values when transferring to/from off-chip memory boosting energy efficiency and reducing execution time.
Mokey: Enabling Narrow Fixed-Point Inference for Out-of-the-Box Floating-Point Transformer Models
Mar 23, 2022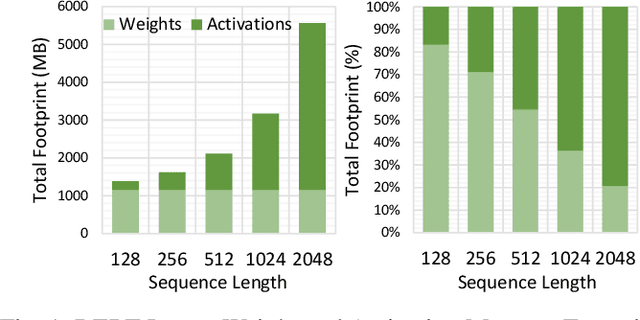
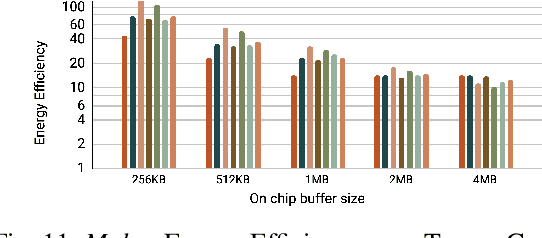
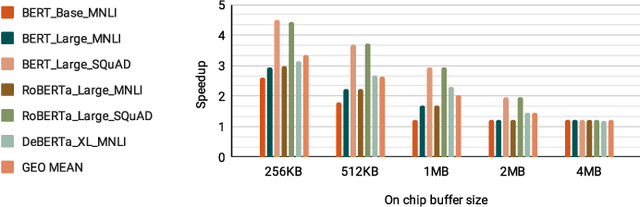
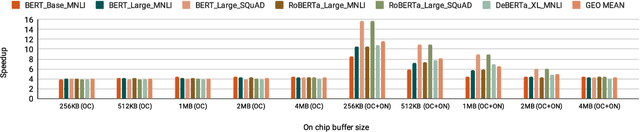
Increasingly larger and better Transformer models keep advancing state-of-the-art accuracy and capability for Natural Language Processing applications. These models demand more computational power, storage, and energy. Mokey reduces the footprint of state-of-the-art 32-bit or 16-bit floating-point transformer models by quantizing all values to 4-bit indexes into dictionaries of representative 16-bit fixed-point centroids. Mokey does not need fine-tuning, an essential feature as often the training resources or datasets are not available to many. Exploiting the range of values that naturally occur in transformer models, Mokey selects centroid values to also fit an exponential curve. This unique feature enables Mokey to replace the bulk of the original multiply-accumulate operations with narrow 3b fixed-point additions resulting in an area- and energy-efficient hardware accelerator design. Over a set of state-of-the-art transformer models, the Mokey accelerator delivers an order of magnitude improvements in energy efficiency over a Tensor Cores-based accelerator while improving performance by at least $4\times$ and as much as $15\times$ depending on the model and on-chip buffering capacity. Optionally, Mokey can be used as a memory compression assist for any other accelerator, transparently stashing wide floating-point or fixed-point activations or weights into narrow 4-bit indexes. Mokey proves superior to prior state-of-the-art quantization methods for Transformers.
APack: Off-Chip, Lossless Data Compression for Efficient Deep Learning Inference
Jan 21, 2022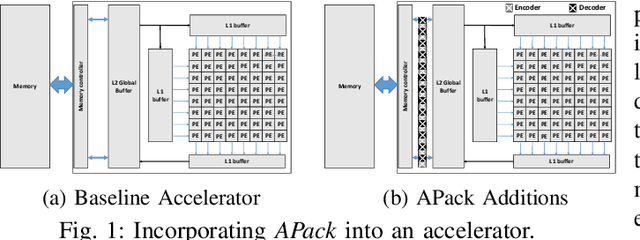
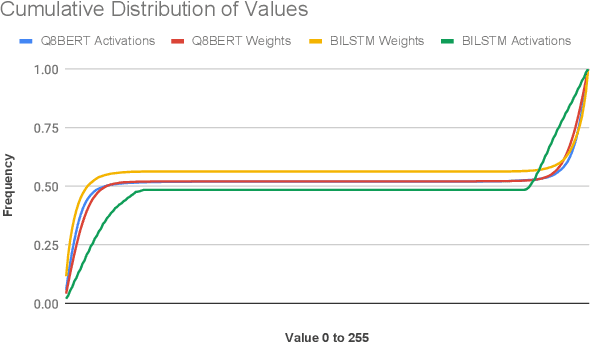
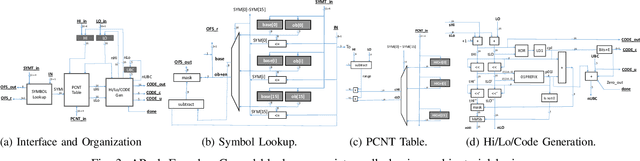
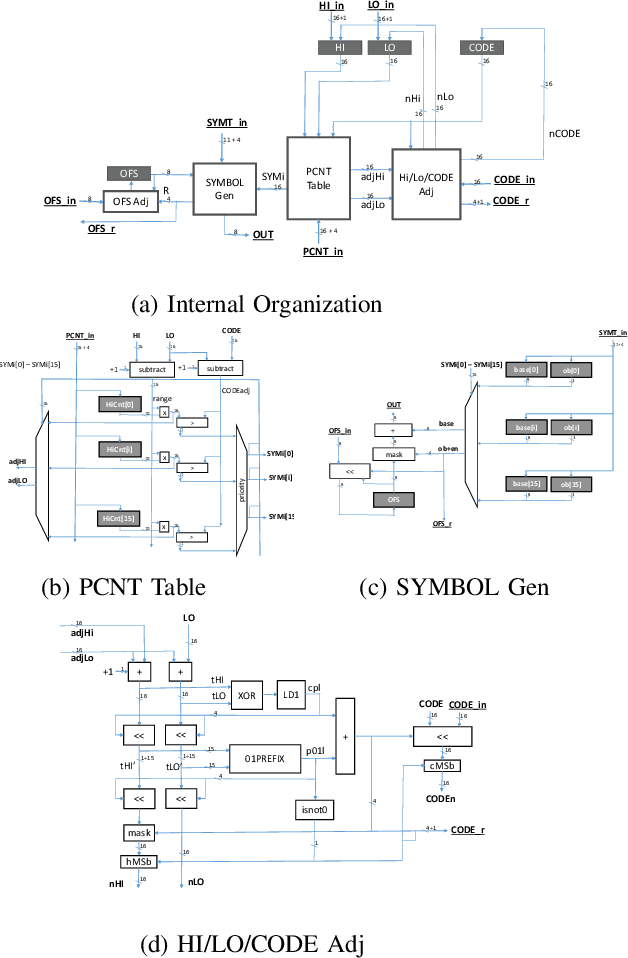
Data accesses between on- and off-chip memories account for a large fraction of overall energy consumption during inference with deep learning networks. We present APack, a simple and effective, lossless, off-chip memory compression technique for fixed-point quantized models. APack reduces data widths by exploiting the non-uniform value distribution in deep learning applications. APack can be used to increase the effective memory capacity, to reduce off-chip traffic, and/or to achieve the desired performance/energy targets while using smaller off-chip memories. APack builds upon arithmetic coding, encoding each value as an arithmetically coded variable length prefix, plus an offset. To maximize compression ratio a heuristic software algorithm partitions the value space into groups each sharing a common prefix. APack exploits memory access parallelism by using several, pipelined encoder/decoder units in parallel and keeps up with the high data bandwidth demands of deep learning. APack can be used with any machine learning accelerator. In the demonstrated configuration, APack is placed just before the off-chip memory controller so that he rest of the on-chip memory and compute units thus see the original data stream. We implemented the APack compressor and decompressor in Verilog and in a 65nm tech node demonstrating its performance and energy efficiency. Indicatively, APack reduces data footprint of weights and activations to 60% and 48% respectively on average over a wide set of 8-bit quantized models. It naturally adapts and compresses models that use even more aggressive quantization methods. When integrated with a Tensorcore-based accelerator, APack boosts the speedup and energy efficiency to 1.44X and 1.37X respectively.
FPRaker: A Processing Element For Accelerating Neural Network Training
Oct 15, 2020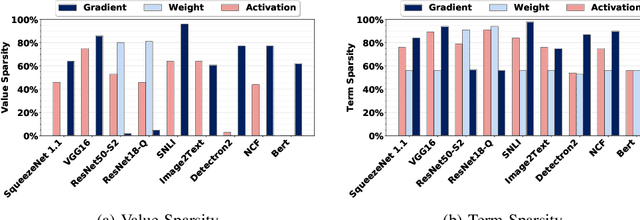
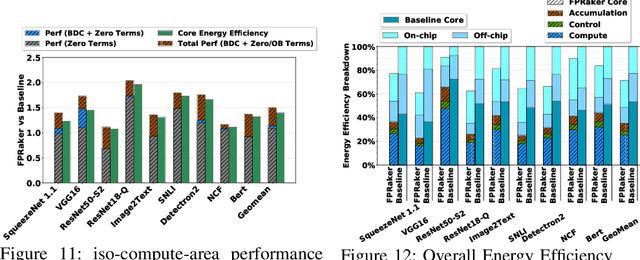
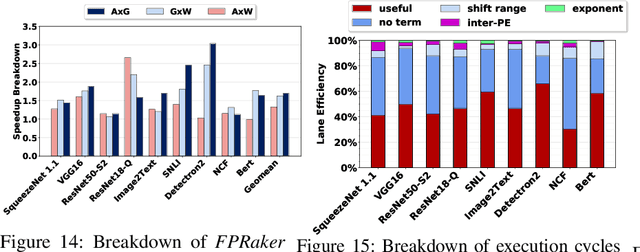
We present FPRaker, a processing element for composing training accelerators. FPRaker processes several floating-point multiply-accumulation operations concurrently and accumulates their result into a higher precision accumulator. FPRaker boosts performance and energy efficiency during training by taking advantage of the values that naturally appear during training. Specifically, it processes the significand of the operands of each multiply-accumulate as a series of signed powers of two. The conversion to this form is done on-the-fly. This exposes ineffectual work that can be skipped: values when encoded have few terms and some of them can be discarded as they would fall outside the range of the accumulator given the limited precision of floating-point. We demonstrate that FPRaker can be used to compose an accelerator for training and that it can improve performance and energy efficiency compared to using conventional floating-point units under ISO-compute area constraints. We also demonstrate that FPRaker delivers additional benefits when training incorporates pruning and quantization. Finally, we show that FPRaker naturally amplifies performance with training methods that use a different precision per layer.
TensorDash: Exploiting Sparsity to Accelerate Deep Neural Network Training and Inference
Sep 01, 2020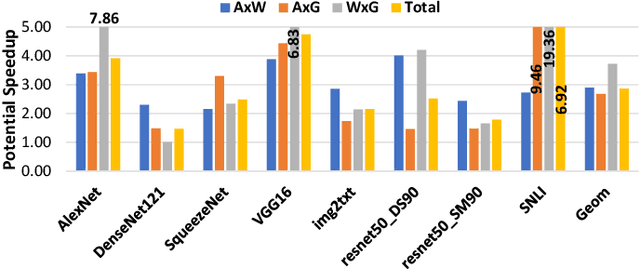
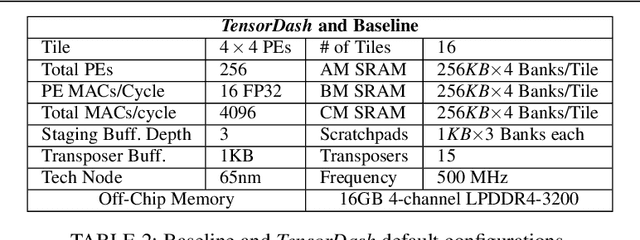
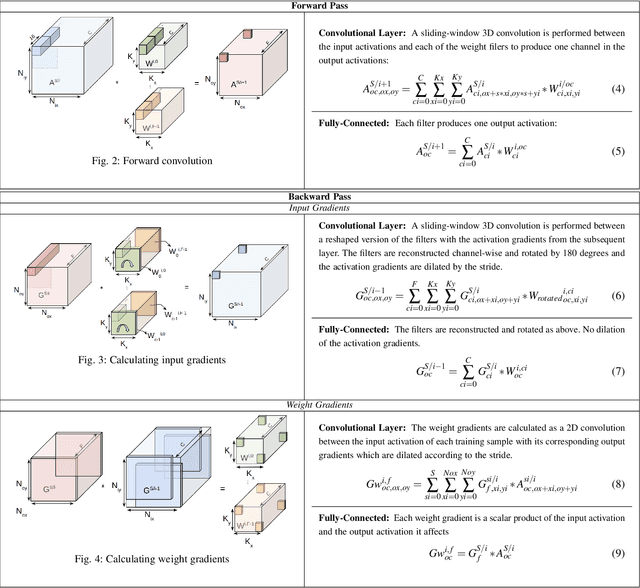
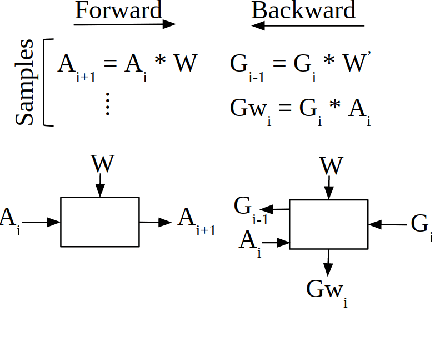
TensorDash is a hardware level technique for enabling data-parallel MAC units to take advantage of sparsity in their input operand streams. When used to compose a hardware accelerator for deep learning, TensorDash can speedup the training process while also increasing energy efficiency. TensorDash combines a low-cost, sparse input operand interconnect comprising an 8-input multiplexer per multiplier input, with an area-efficient hardware scheduler. While the interconnect allows a very limited set of movements per operand, the scheduler can effectively extract sparsity when it is present in the activations, weights or gradients of neural networks. Over a wide set of models covering various applications, TensorDash accelerates the training process by $1.95{\times}$ while being $1.89\times$ more energy-efficient, $1.6\times$ more energy efficient when taking on-chip and off-chip memory accesses into account. While TensorDash works with any datatype, we demonstrate it with both single-precision floating-point units and bfloat16.
GOBO: Quantizing Attention-Based NLP Models for Low Latency and Energy Efficient Inference
May 08, 2020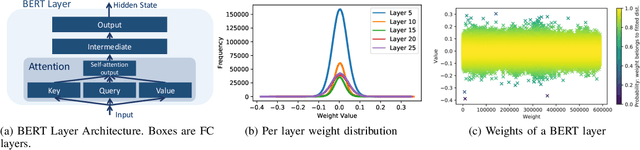
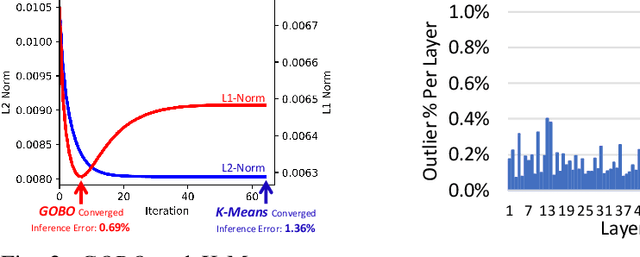
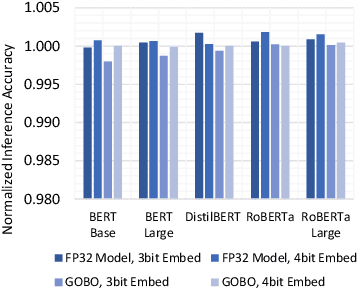
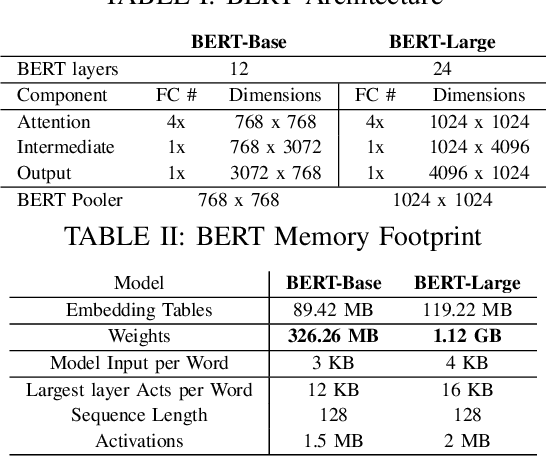
Attention-based models have demonstrated remarkable success in various natural language understanding tasks. However, efficient execution remains a challenge for these models which are memory-bound due to their massive number of parameters. We present a model quantization technique that compresses the vast majority (typically 99.9%) of the 32-bit floating-point parameters of state-of-the-art BERT models and its variants to 3 bits while maintaining their accuracy. Unlike other quantization methods, our technique does not require fine-tuning nor retraining to compensate for the quantization error.
BitPruning: Learning Bitlengths for Aggressive and Accurate Quantization
Feb 08, 2020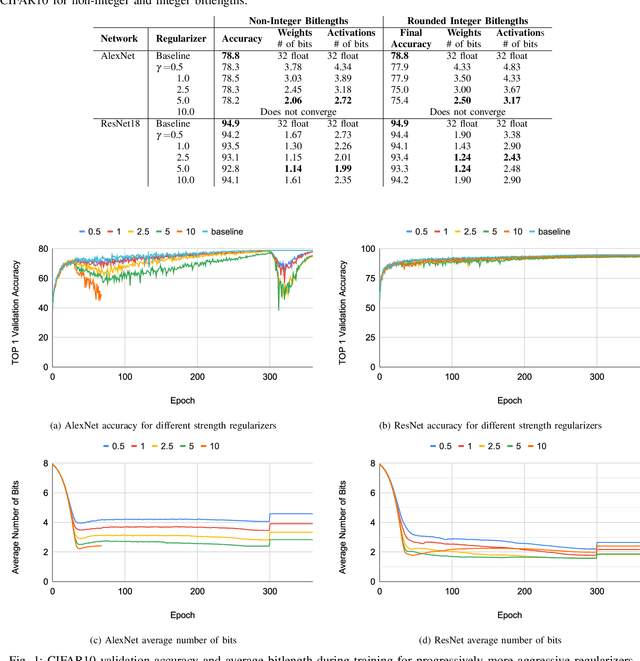

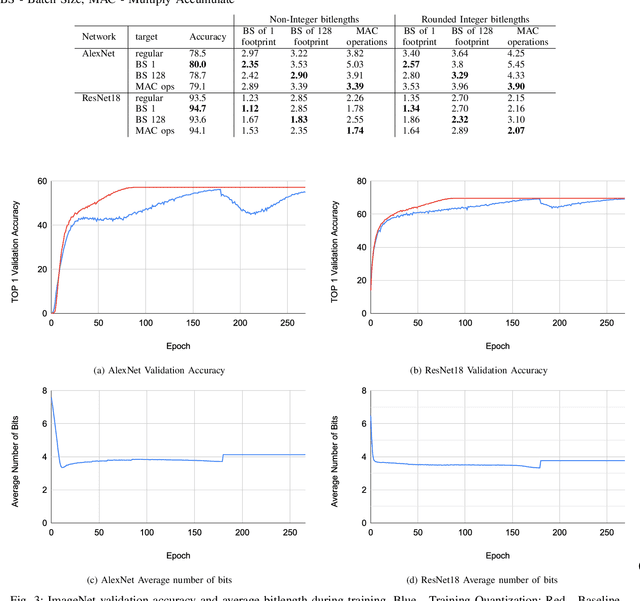
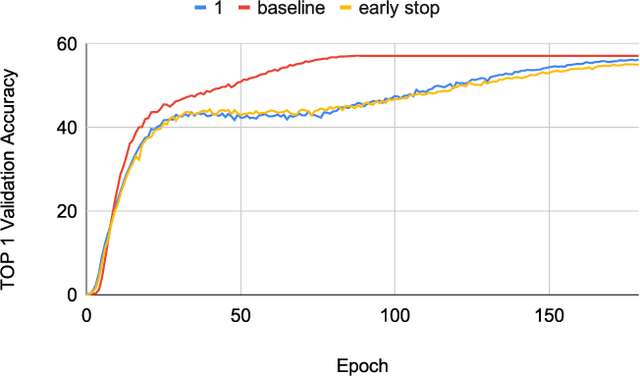
Neural networks have demonstrably achieved state-of-the art accuracy using low-bitlength integer quantization, yielding both execution time and energy benefits on existing hardware designs that support short bitlengths. However, the question of finding the minimum bitlength for a desired accuracy remains open. We introduce a training method for minimizing inference bitlength at any granularity while maintaining accuracy. Furthermore, we propose a regularizer that penalizes large bitlength representations throughout the architecture and show how it can be modified to minimize other quantifiable criteria, such as number of operations or memory footprint. We demonstrate that our method learns thrifty representations while maintaining accuracy. With ImageNet, the method produces an average per layer bitlength of 4.13 and 3.76 bits on AlexNet and ResNet18 respectively, remaining within 2.0% and 0.5% of the baseline TOP-1 accuracy.
Training CNNs faster with Dynamic Input and Kernel Downsampling
Oct 15, 2019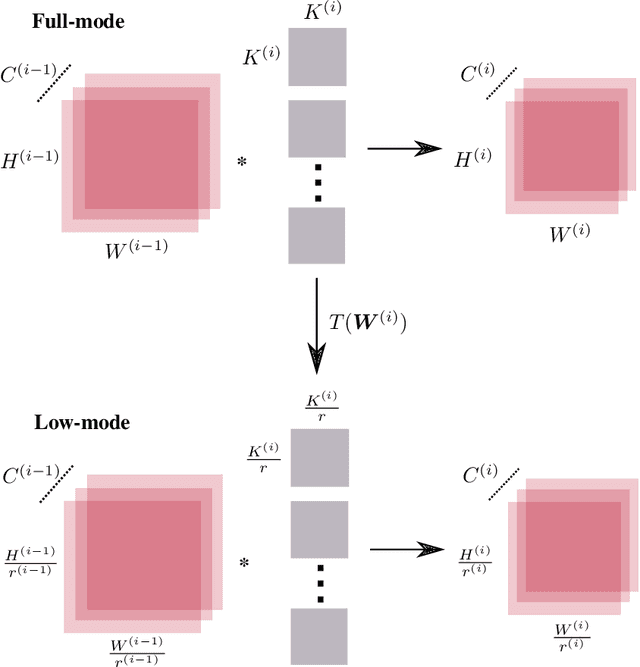

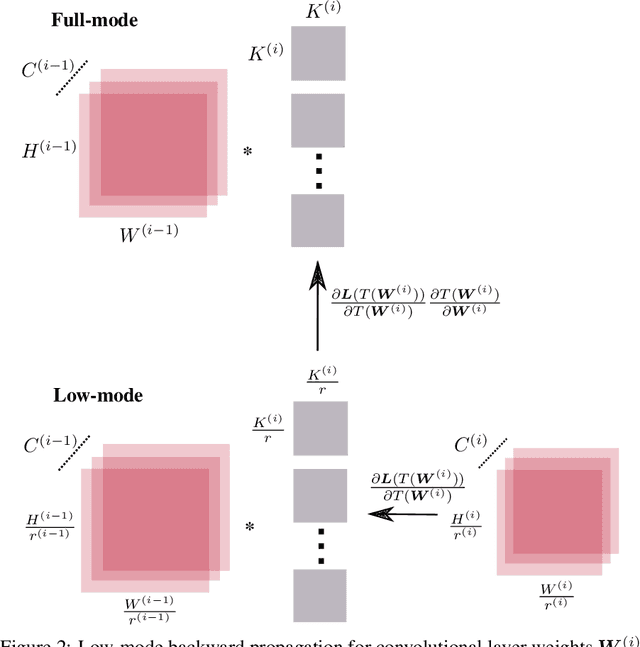
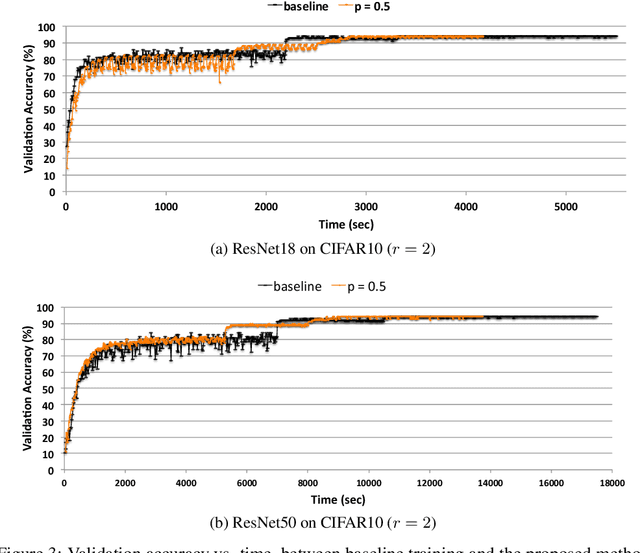
We reduce training time in convolutional networks (CNNs) with a method that, for some of the mini-batches: a) scales down the resolution of input images via downsampling, and b) reduces the forward pass operations via pooling on the convolution filters. Training is performed in an interleaved fashion; some batches undergo the regular forward and backpropagation passes with original network parameters, whereas others undergo a forward pass with pooled filters and downsampled inputs. Since pooling is differentiable, the gradients of the pooled filters propagate to the original network parameters for a standard parameter update. The latter phase requires fewer floating point operations and less storage due to the reduced spatial dimensions in feature maps and filters. The key idea is that this phase leads to smaller and approximate updates and thus slower learning, but at significantly reduced cost, followed by passes that use the original network parameters as a refinement stage. Deciding how often and for which batches the downsmapling occurs can be done either stochastically or deterministically, and can be defined as a training hyperparameter itself. Experiments on residual architectures show that we can achieve up to 23% reduction in training time with minimal loss in validation accuracy.