 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Characterization of Thin Film MoS$_2$ Using Generative Models
May 29, 2025



The growth and characterization of materials using empirical optimization typically requires a significant amount of expert time, experience, and resources. Several complementary characterization methods are routinely performed to determine the quality and properties of a grown sample. Machine learning (ML) can support the conventional approaches by using historical data to guide and provide speed and efficiency to the growth and characterization of materials. Specifically, ML can provide quantitative information from characterization data that is typically obtained from a different modality. In this study, we have investigated the feasibility of projecting the quantitative metric from microscopy measurements, such as atomic force microscopy (AFM), using data obtained from spectroscopy measurements, like Raman spectroscopy. Generative models were also trained to generate the full and specific features of the Raman and photoluminescence spectra from each other and the AFM images of the thin film MoS$_2$. The results are promising and have provided a foundational guide for the use of ML for the cross-modal characterization of materials for their accelerated, efficient, and cost-effective discovery.
DarkDiff: Advancing Low-Light Raw Enhancement by Retasking Diffusion Models for Camera ISP
May 29, 2025High-quality photography in extreme low-light conditions is challenging but impactful for digital cameras. With advanced computing hardware, traditional camera image signal processor (ISP) algorithms are gradually being replaced by efficient deep networks that enhance noisy raw images more intelligently. However, existing regression-based models often minimize pixel errors and result in oversmoothing of low-light photos or deep shadows. Recent work has attempted to address this limitation by training a diffusion model from scratch, yet those models still struggle to recover sharp image details and accurate colors. We introduce a novel framework to enhance low-light raw images by retasking pre-trained generative diffusion models with the camera ISP. Extensive experiments demonstrate that our method outperforms the state-of-the-art in perceptual quality across three challenging low-light raw image benchmarks.
DA-VPT: Semantic-Guided Visual Prompt Tuning for Vision Transformers
May 29, 2025Visual Prompt Tuning (VPT) has become a promising solution for Parameter-Efficient Fine-Tuning (PEFT) approach for Vision Transformer (ViT) models by partially fine-tuning learnable tokens while keeping most model parameters frozen. Recent research has explored modifying the connection structures of the prompts. However, the fundamental correlation and distribution between the prompts and image tokens remain unexplored. In this paper, we leverage metric learning techniques to investigate how the distribution of prompts affects fine-tuning performance. Specifically, we propose a novel framework, Distribution Aware Visual Prompt Tuning (DA-VPT), to guide the distributions of the prompts by learning the distance metric from their class-related semantic data. Our method demonstrates that the prompts can serve as an effective bridge to share semantic information between image patches and the class token. We extensively evaluated our approach on popular benchmarks in both recognition and segmentation tasks. The results demonstrate that our approach enables more effective and efficient fine-tuning of ViT models by leveraging semantic information to guide the learning of the prompts, leading to improved performance on various downstream vision tasks.
SoloSpeech: Enhancing Intelligibility and Quality in Target Speech Extraction through a Cascaded Generative Pipeline
May 25, 2025Target Speech Extraction (TSE) aims to isolate a target speaker's voice from a mixture of multiple speakers by leveraging speaker-specific cues, typically provided as auxiliary audio (a.k.a. cue audio). Although recent advancements in TSE have primarily employed discriminative models that offer high perceptual quality, these models often introduce unwanted artifacts, reduce naturalness, and are sensitive to discrepancies between training and testing environments. On the other hand, generative models for TSE lag in perceptual quality and intelligibility. To address these challenges, we present SoloSpeech, a novel cascaded generative pipeline that integrates compression, extraction, reconstruction, and correction processes. SoloSpeech features a speaker-embedding-free target extractor that utilizes conditional information from the cue audio's latent space, aligning it with the mixture audio's latent space to prevent mismatches. Evaluated on the widely-used Libri2Mix dataset, SoloSpeech achieves the new state-of-the-art intelligibility and quality in target speech extraction and speech separation tasks while demonstrating exceptional generalization on out-of-domain data and real-world scenarios.
Eye-See-You: Reverse Pass-Through VR and Head Avatars
May 24, 2025Virtual Reality (VR) headsets, while integral to the evolving digital ecosystem, present a critical challenge: the occlusion of users' eyes and portions of their faces, which hinders visual communication and may contribute to social isolation. To address this, we introduce RevAvatar, an innovative framework that leverages AI methodologies to enable reverse pass-through technology, fundamentally transforming VR headset design and interaction paradigms. RevAvatar integrates state-of-the-art generative models and multimodal AI techniques to reconstruct high-fidelity 2D facial images and generate accurate 3D head avatars from partially observed eye and lower-face regions. This framework represents a significant advancement in AI4Tech by enabling seamless interaction between virtual and physical environments, fostering immersive experiences such as VR meetings and social engagements. Additionally, we present VR-Face, a novel dataset comprising 200,000 samples designed to emulate diverse VR-specific conditions, including occlusions, lighting variations, and distortions. By addressing fundamental limitations in current VR systems, RevAvatar exemplifies the transformative synergy between AI and next-generation technologies, offering a robust platform for enhancing human connection and interaction in virtual environments.
Attributing Response to Context: A Jensen-Shannon Divergence Driven Mechanistic Study of Context Attribution in Retrieval-Augmented Generation
May 22, 2025Retrieval-Augmented Generation (RAG) leverages large language models (LLMs) combined with external contexts to enhance the accuracy and reliability of generated responses. However, reliably attributing generated content to specific context segments, context attribution, remains challenging due to the computationally intensive nature of current methods, which often require extensive fine-tuning or human annotation. In this work, we introduce a novel Jensen-Shannon Divergence driven method to Attribute Response to Context (ARC-JSD), enabling efficient and accurate identification of essential context sentences without additional fine-tuning or surrogate modelling. Evaluations on a wide range of RAG benchmarks, such as TyDi QA, Hotpot QA, and Musique, using instruction-tuned LLMs in different scales demonstrate superior accuracy and significant computational efficiency improvements compared to the previous surrogate-based method. Furthermore, our mechanistic analysis reveals specific attention heads and multilayer perceptron (MLP) layers responsible for context attribution, providing valuable insights into the internal workings of RAG models.
Efficient and Direct Duplex Modeling for Speech-to-Speech Language Model
May 21, 2025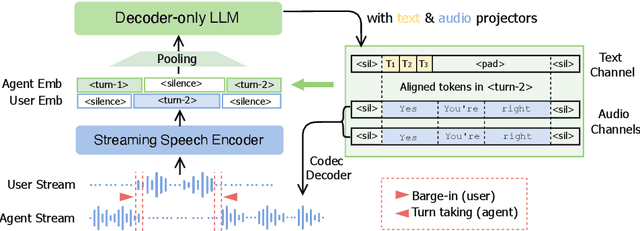
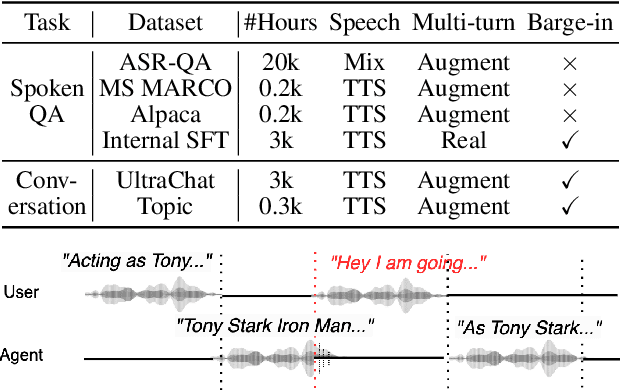
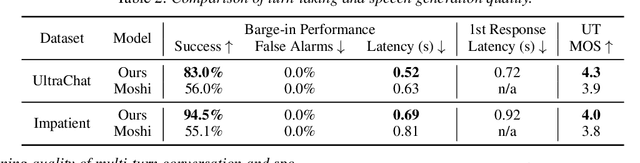
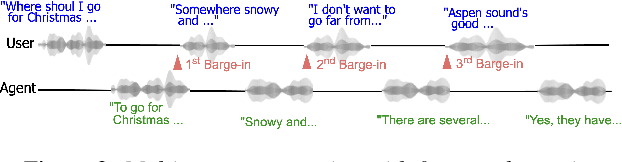
Spoken dialogue is an intuitive form of human-computer interaction, yet current speech language models often remain constrained to turn-based exchanges, lacking real-time adaptability such as user barge-in. We propose a novel duplex speech to speech (S2S) architecture featuring continuous user inputs and codec agent outputs with channel fusion that directly models simultaneous user and agent streams. Using a pretrained streaming encoder for user input enables the first duplex S2S model without requiring speech pretrain. Separate architectures for agent and user modeling facilitate codec fine-tuning for better agent voices and halve the bitrate (0.6 kbps) compared to previous works. Experimental results show that the proposed model outperforms previous duplex models in reasoning, turn-taking, and barge-in abilities. The model requires significantly less speech data, as speech pretrain is skipped, which markedly simplifies the process of building a duplex S2S model from any LLMs. Finally, it is the first openly available duplex S2S model with training and inference code to foster reproducibility.
ViC-Bench: Benchmarking Visual-Interleaved Chain-of-Thought Capability in MLLMs with Free-Style Intermediate State Representations
May 20, 2025



Visual-Interleaved Chain-of-Thought (VI-CoT) enables MLLMs to continually update their understanding and decisions based on step-wise intermediate visual states (IVS), much like a human would, which demonstrates impressive success in various tasks, thereby leading to emerged advancements in related benchmarks. Despite promising progress, current benchmarks provide models with relatively fixed IVS, rather than free-style IVS, whch might forcibly distort the original thinking trajectories, failing to evaluate their intrinsic reasoning capabilities. More importantly, existing benchmarks neglect to systematically explore the impact factors that IVS would impart to untamed reasoning performance. To tackle above gaps, we introduce a specialized benchmark termed ViC-Bench, consisting of four representive tasks: maze navigation, jigsaw puzzle, embodied long-horizon planning, and complex counting, where each task has dedicated free-style IVS generation pipeline supporting function calls. To systematically examine VI-CoT capability, we propose a thorough evaluation suite incorporating a progressive three-stage strategy with targeted new metrics. Besides, we establish Incremental Prompting Information Injection (IPII) strategy to ablatively explore the prompting factors for VI-CoT. We extensively conduct evaluations for 18 advanced MLLMs, revealing key insights into their VI-CoT capability. Our proposed benchmark is publicly open at Huggingface.
Generalizable Multispectral Land Cover Classification via Frequency-Aware Mixture of Low-Rank Token Experts
May 20, 2025We introduce Land-MoE, a novel approach for multispectral land cover classification (MLCC). Spectral shift, which emerges from disparities in sensors and geospatial conditions, poses a significant challenge in this domain. Existing methods predominantly rely on domain adaptation and generalization strategies, often utilizing small-scale models that exhibit limited performance. In contrast, Land-MoE addresses these issues by hierarchically inserting a Frequency-aware Mixture of Low-rank Token Experts, to fine-tune Vision Foundation Models (VFMs) in a parameter-efficient manner. Specifically, Land-MoE comprises two key modules: the mixture of low-rank token experts (MoLTE) and frequency-aware filters (FAF). MoLTE leverages rank-differentiated tokens to generate diverse feature adjustments for individual instances within multispectral images. By dynamically combining learnable low-rank token experts of varying ranks, it enhances the robustness against spectral shifts. Meanwhile, FAF conducts frequency-domain modulation on the refined features. This process enables the model to effectively capture frequency band information that is strongly correlated with semantic essence, while simultaneously suppressing frequency noise irrelevant to the task. Comprehensive experiments on MLCC tasks involving cross-sensor and cross-geospatial setups demonstrate that Land-MoE outperforms existing methods by a large margin. Additionally, the proposed approach has also achieved state-of-the-art performance in domain generalization semantic segmentation tasks of RGB remote sensing images.
GIE-Bench: Towards Grounded Evaluation for Text-Guided Image Editing
May 16, 2025



Editing images using natural language instructions has become a natural and expressive way to modify visual content; yet, evaluating the performance of such models remains challenging. Existing evaluation approaches often rely on image-text similarity metrics like CLIP, which lack precision. In this work, we introduce a new benchmark designed to evaluate text-guided image editing models in a more grounded manner, along two critical dimensions: (i) functional correctness, assessed via automatically generated multiple-choice questions that verify whether the intended change was successfully applied; and (ii) image content preservation, which ensures that non-targeted regions of the image remain visually consistent using an object-aware masking technique and preservation scoring. The benchmark includes over 1000 high-quality editing examples across 20 diverse content categories, each annotated with detailed editing instructions, evaluation questions, and spatial object masks. We conduct a large-scale study comparing GPT-Image-1, the latest flagship in the text-guided image editing space, against several state-of-the-art editing models, and validate our automatic metrics against human ratings. Results show that GPT-Image-1 leads in instruction-following accuracy, but often over-modifies irrelevant image regions, highlighting a key trade-off in the current model behavior. GIE-Bench provides a scalable, reproducible framework for advancing more accurate evaluation of text-guided image editing.