 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Dancer: Expressive Music to Human Dance Video Generation
Feb 24, 2025We present X-Dancer, a novel zero-shot music-driven image animation pipeline that creates diverse and long-range lifelike human dance videos from a single static image. As its core, we introduce a unified transformer-diffusion framework, featuring an autoregressive transformer model that synthesize extended and music-synchronized token sequences for 2D body, head and hands poses, which then guide a diffusion model to produce coherent and realistic dance video frames. Unlike traditional methods that primarily generate human motion in 3D, X-Dancer addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, capturing their nuanced alignment with musical beats through readily available monocular videos. To achieve this, we first build a spatially compositional token representation from 2D human pose labels associated with keypoint confidences, encoding both large articulated body movements (e.g., upper and lower body) and fine-grained motions (e.g., head and hands). We then design a music-to-motion transformer model that autoregressively generates music-aligned dance pose token sequences, incorporating global attention to both musical style and prior motion context. Finally we leverage a diffusion backbone to animate the reference image with these synthesized pose tokens through AdaIN, forming a fully differentiable end-to-end framework. Experimental results demonstrate that X-Dancer is able to produce both diverse and characterized dance videos, substantially outperforming state-of-the-art methods in term of diversity, expressiveness and realism. Code and model will be available for research purposes.
Event Stream-based Visual Object Tracking: HDETrack V2 and A High-Definition Benchmark
Feb 08, 2025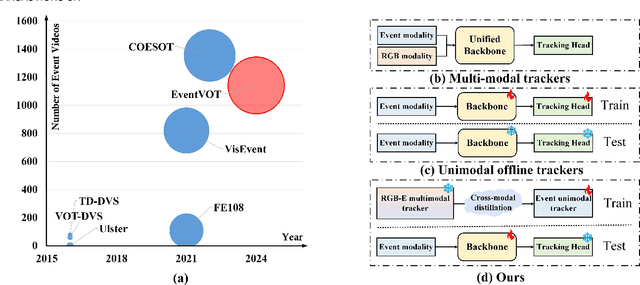

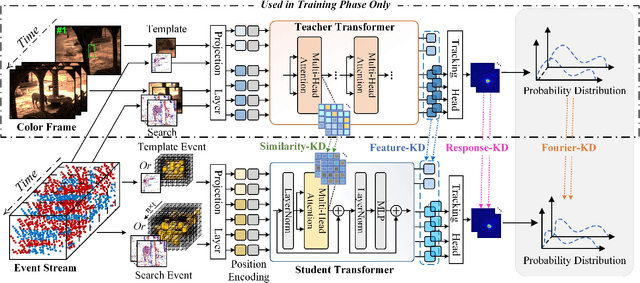

We then introduce a novel hierarchical knowledge distillation strategy that incorporates the similarity matrix, feature representation, and response map-based distillation to guide the learning of the student Transformer network. We also enhance the model's ability to capture temporal dependencies by applying the temporal Fourier transform to establish temporal relationships between video frames. We adapt the network model to specific target objects during testing via a newly proposed test-time tuning strategy to achieve high performance and flexibility in target tracking. Recognizing the limitations of existing event-based tracking datasets, which are predominantly low-resolution, we propose EventVOT, the first large-scale high-resolution event-based tracking dataset. It comprises 1141 videos spanning diverse categories such as pedestrians, vehicles, UAVs, ping pong, etc. Extensive experiments on both low-resolution (FE240hz, VisEvent, FELT), and our newly proposed high-resolution EventVOT dataset fully validated the effectiveness of our proposed method. Both the benchmark dataset and source code have been released on https://github.com/Event-AHU/EventVOT_Benchmark
Boosting Knowledge Graph-based Recommendations through Confidence-Aware Augmentation with Large Language Models
Feb 06, 2025



Knowledge Graph-based recommendations have gained significant attention due to their ability to leverage rich semantic relationships. However, constructing and maintaining Knowledge Graphs (KGs) is resource-intensive, and the accuracy of KGs can suffer from noisy, outdated, or irrelevant triplets. Recent advancements in Large Language Models (LLMs) offer a promising way to improve the quality and relevance of KGs for recommendation tasks. Despite this, integrating LLMs into KG-based systems presents challenges, such as efficiently augmenting KGs, addressing hallucinations, and developing effective joint learning methods. In this paper, we propose the Confidence-aware KG-based Recommendation Framework with LLM Augmentation (CKG-LLMA), a novel framework that combines KGs and LLMs for recommendation task. The framework includes: (1) an LLM-based subgraph augmenter for enriching KGs with high-quality information, (2) a confidence-aware message propagation mechanism to filter noisy triplets, and (3) a dual-view contrastive learning method to integrate user-item interactions and KG data. Additionally, we employ a confidence-aware explanation generation process to guide LLMs in producing realistic explanations for recommendations. Finally, extensive experiments demonstrate the effectiveness of CKG-LLMA across multiple public datasets.
LAYOUTDREAMER: Physics-guided Layout for Text-to-3D Compositional Scene Generation
Feb 04, 2025



Recently, the field of text-guided 3D scene generation has garnered significant attention. High-quality generation that aligns with physical realism and high controllability is crucial for practical 3D scene applications. However, existing methods face fundamental limitations: (i) difficulty capturing complex relationships between multiple objects described in the text, (ii) inability to generate physically plausible scene layouts, and (iii) lack of controllability and extensibility in compositional scenes. In this paper, we introduce LayoutDreamer, a framework that leverages 3D Gaussian Splatting (3DGS) to facilitate high-quality, physically consistent compositional scene generation guided by text. Specifically, given a text prompt, we convert it into a directed scene graph and adaptively adjust the density and layout of the initial compositional 3D Gaussians. Subsequently, dynamic camera adjustments are made based on the training focal point to ensure entity-level generation quality. Finally, by extracting directed dependencies from the scene graph, we tailor physical and layout energy to ensure both realism and flexibility. Comprehensive experiments demonstrate that LayoutDreamer outperforms other compositional scene generation quality and semantic alignment methods. Specifically, it achieves state-of-the-art (SOTA) performance in the multiple objects generation metric of T3Bench.
AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
Feb 03, 2025



Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), often produce out-of-distribution or noisy inputs, leading to misalignment between the modalities. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where scanned document images must be accurately mapped to their textual content. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods. We provide further analysis demonstrating improved vision-text feature alignment and robustness to noise.
PhiP-G: Physics-Guided Text-to-3D Compositional Scene Generation
Feb 02, 2025



Text-to-3D asset generation has achieved significant optimization under the supervision of 2D diffusion priors. However, when dealing with compositional scenes, existing methods encounter several challenges: 1). failure to ensure that composite scene layouts comply with physical laws; 2). difficulty in accurately capturing the assets and relationships described in complex scene descriptions; 3). limited autonomous asset generation capabilities among layout approaches leveraging large language models (LLMs). To avoid these compromises, we propose a novel framework for compositional scene generation, PhiP-G, which seamlessly integrates generation techniques with layout guidance based on a world model. Leveraging LLM-based agents, PhiP-G analyzes the complex scene description to generate a scene graph, and integrating a multimodal 2D generation agent and a 3D Gaussian generation method for targeted assets creation. For the stage of layout, PhiP-G employs a physical pool with adhesion capabilities and a visual supervision agent, forming a world model for layout prediction and planning. Extensive experiments demonstrate that PhiP-G significantly enhances the generation quality and physical rationality of the compositional scenes. Notably, PhiP-G attains state-of-the-art (SOTA) performance in CLIP scores, achieves parity with the leading methods in generation quality as measured by the T$^3$Bench, and improves efficiency by 24x.
VIKSER: Visual Knowledge-Driven Self-Reinforcing Reasoning Framework
Feb 02, 2025



Visual reasoning refers to the task of solving questions about visual information. Current visual reasoning methods typically employ pre-trained vision-language model (VLM) strategies or deep neural network approaches. However, existing efforts are constrained by limited reasoning interpretability, while hindering by the phenomenon of underspecification in the question text. Additionally, the absence of fine-grained visual knowledge limits the precise understanding of subject behavior in visual reasoning tasks. To address these issues, we propose VIKSER (Visual Knowledge-Driven Self-Reinforcing Reasoning Framework). Specifically, VIKSER, trained using knowledge distilled from large language models, extracts fine-grained visual knowledge with the assistance of visual relationship detection techniques. Subsequently, VIKSER utilizes fine-grained visual knowledge to paraphrase the question with underspecification. Additionally, we design a novel prompting method called Chain-of-Evidence (CoE), which leverages the power of ``evidence for reasoning'' to endow VIKSER with interpretable reasoning capabilities. Meanwhile, the integration of self-reflection technology empowers VIKSER with the ability to learn and improve from its mistakes. Experiments conducted on widely used datasets demonstrate that VIKSER achieves new state-of-the-art (SOTA) results in relevant tasks.
MINT: Mitigating Hallucinations in Large Vision-Language Models via Token Reduction
Feb 02, 2025



Hallucination has been a long-standing and inevitable problem that hinders the application of Large Vision-Language Models (LVLMs) in domains that require high reliability. Various methods focus on improvement depending on data annotations or training strategies, yet place less emphasis on LLM's inherent problems. To fill this gap, we delve into the attention mechanism of the decoding process in the LVLM. Intriguingly, our investigation uncovers the prevalent attention redundancy within the hierarchical architecture of the LVLM, manifesting as overextended image processing in deep layers and an overabundance of non-essential image tokens. Stemming from the observation, we thus propose MINT, a novel training-free decoding strategy, MItigating hallucinations via tokeN reducTion. Specifically, we dynamically intensify the LVLM's local perception capability by masking its attention to irrelevant image tokens. In addition, we use contrastive decoding that pushes the model to focus more on those key image regions. Our full method aims to guide the model in concentrating more on key visual elements during generation. Extensive experimental results on several popular public benchmarks show that our approach achieves a 4% improvement in mitigating hallucinations caused by distracted perception compared to original models. Meanwhile, our approach is demonstrated to make the model perceive 5% more visual points even though we reduce a suite of image tokens.
Hierarchical Time-Aware Mixture of Experts for Multi-Modal Sequential Recommendation
Jan 24, 2025Multi-modal sequential recommendation (SR) leverages multi-modal data to learn more comprehensive item features and user preferences than traditional SR methods, which has become a critical topic in both academia and industry. Existing methods typically focus on enhancing multi-modal information utility through adaptive modality fusion to capture the evolving of user preference from user-item interaction sequences. However, most of them overlook the interference caused by redundant interest-irrelevant information contained in rich multi-modal data. Additionally, they primarily rely on implicit temporal information based solely on chronological ordering, neglecting explicit temporal signals that could more effectively represent dynamic user interest over time. To address these limitations, we propose a Hierarchical time-aware Mixture of experts for multi-modal Sequential Recommendation (HM4SR) with a two-level Mixture of Experts (MoE) and a multi-task learning strategy. Specifically, the first MoE, named Interactive MoE, extracts essential user interest-related information from the multi-modal data of each item. Then, the second MoE, termed Temporal MoE, captures user dynamic interests by introducing explicit temporal embeddings from timestamps in modality encoding. To further address data sparsity, we propose three auxiliary supervision tasks: sequence-level category prediction (CP) for item feature understanding, contrastive learning on ID (IDCL) to align sequence context with user interests, and placeholder contrastive learning (PCL) to integrate temporal information with modalities for dynamic interest modeling. Extensive experiments on four public datasets verify the effectiveness of HM4SR compared to several state-of-the-art approaches.
X-Dyna: Expressive Dynamic Human Image Animation
Jan 20, 2025We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.