 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixKD: Towards Efficient Distillation of Large-scale Language Models
Nov 01, 2020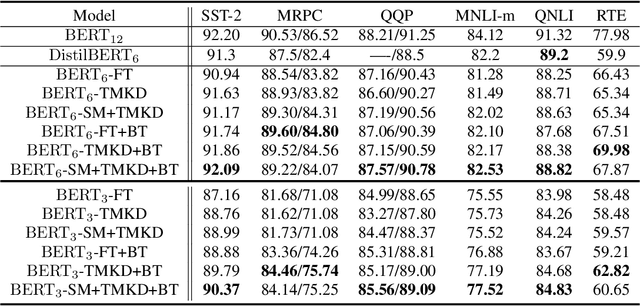
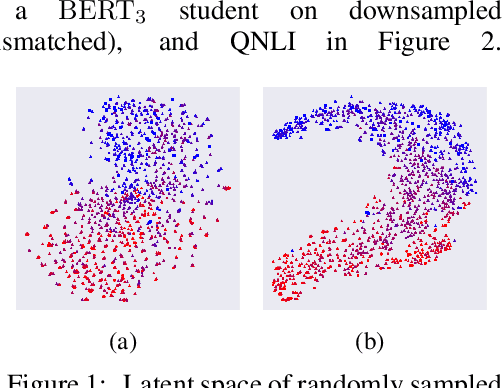
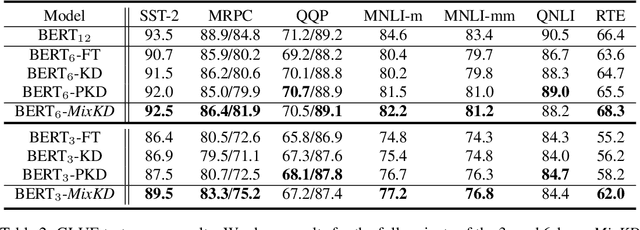
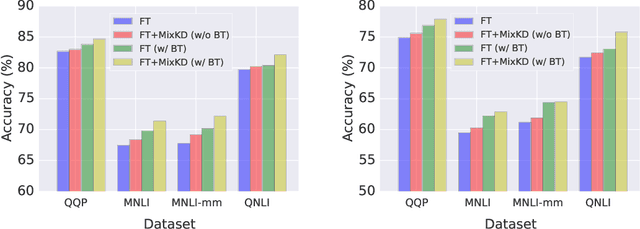
Large-scale language models have recently demonstrated impressive empirical performance. Nevertheless, the improved results are attained at the price of bigger models, more power consumption, and slower inference, which hinder their applicability to low-resource (memory and computation) platforms. Knowledge distillation (KD) has been demonstrated as an effective framework for compressing such big models. However, large-scale neural network systems are prone to memorize training instances, and thus tend to make inconsistent predictions when the data distribution is altered slightly. Moreover, the student model has few opportunities to request useful information from the teacher model when there is limited task-specific data available. To address these issues, we propose MixKD, a data-agnostic distillation framework that leverages mixup, a simple yet efficient data augmentation approach, to endow the resulting model with stronger generalization ability. Concretely, in addition to the original training examples, the student model is encouraged to mimic the teacher's behavior on the linear interpolation of example pairs as well. We prove, from a theoretical perspective, that under reasonable conditions MixKD gives rise to a smaller gap between the generalization error and the empirical error. To verify its effectiveness, we conduct experiments on the GLUE benchmark, where MixKD consistently leads to significant gains over the standard KD training, and outperforms several competitive baselines. Experiments under a limited-data setting and ablation studies further demonstrate the advantages of the proposed approach.
Learning Manifold Implicitly via Explicit Heat-Kernel Learning
Oct 05, 2020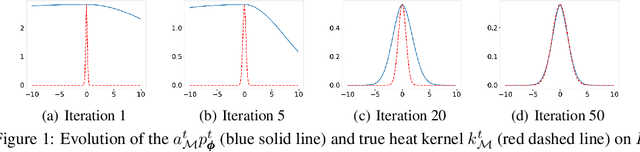

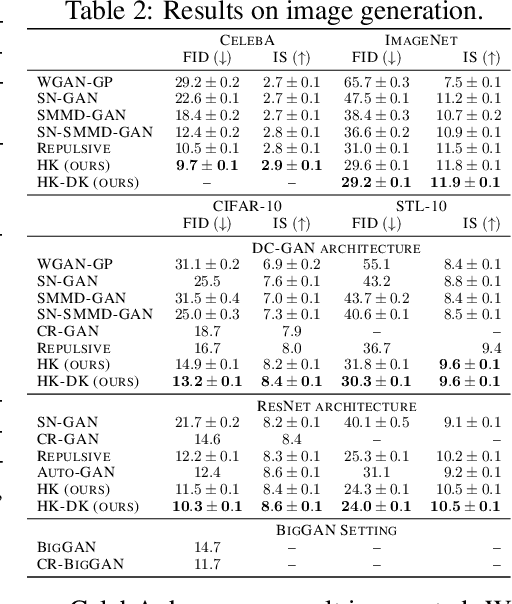

Manifold learning is a fundamental problem in machine learning with numerous applications. Most of the existing methods directly learn the low-dimensional embedding of the data in some high-dimensional space, and usually lack the flexibility of being directly applicable to down-stream applications. In this paper, we propose the concept of implicit manifold learning, where manifold information is implicitly obtained by learning the associated heat kernel. A heat kernel is the solution of the corresponding heat equation, which describes how "heat" transfers on the manifold, thus containing ample geometric information of the manifold. We provide both practical algorithm and theoretical analysis of our framework. The learned heat kernel can be applied to various kernel-based machine learning models, including deep generative models (DGM) for data generation and Stein Variational Gradient Descent for Bayesian inference. Extensive experiments show that our framework can achieve state-of-the-art results compared to existing methods for the two tasks.
Repulsive Attention: Rethinking Multi-head Attention as Bayesian Inference
Sep 20, 2020
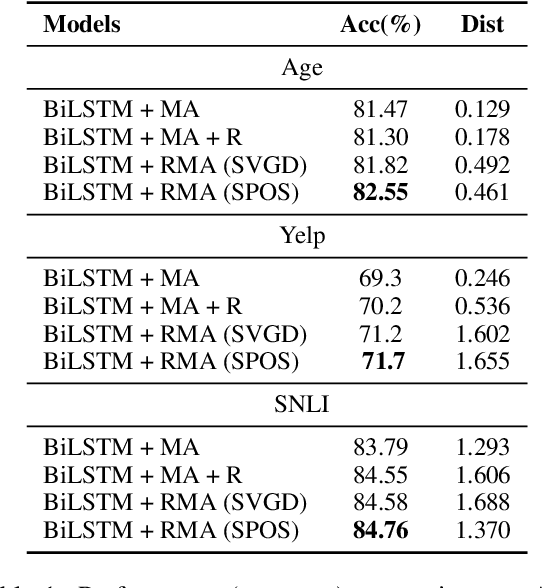
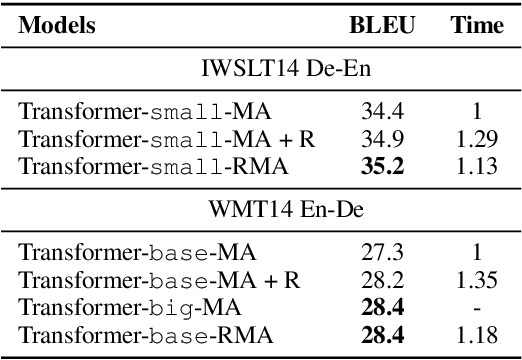
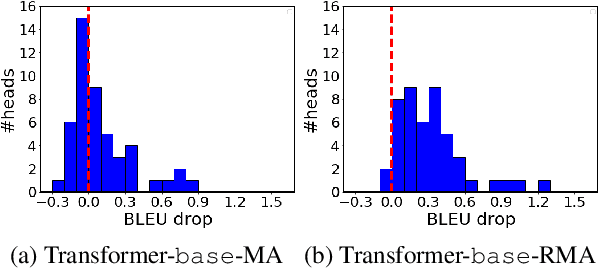
The neural attention mechanism plays an important role in many natural language processing applications. In particular, the use of multi-head attention extends single-head attention by allowing a model to jointly attend information from different perspectives. Without explicit constraining, however, multi-head attention may suffer from attention collapse, an issue that makes different heads extract similar attentive features, thus limiting the model's representation power. In this paper, for the first time, we provide a novel understanding of multi-head attention from a Bayesian perspective. Based on the recently developed particle-optimization sampling techniques, we propose a non-parametric approach that explicitly improves the repulsiveness in multi-head attention and consequently strengthens model's expressiveness. Remarkably, our Bayesian interpretation provides theoretical inspirations on the not-well-understood questions: why and how one uses multi-head attention. Extensive experiments on various attention models and applications demonstrate that the proposed repulsive attention can improve the learned feature diversity, leading to more informative representations with consistent performance improvement on various tasks.
Structure-Aware Human-Action Generation
Jul 16, 2020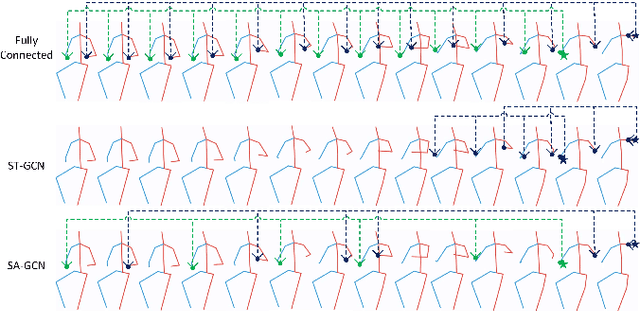
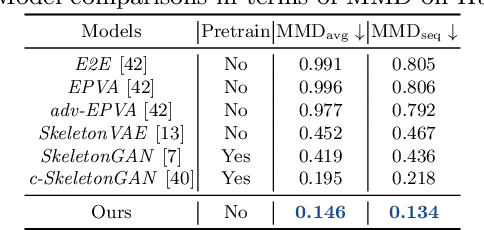
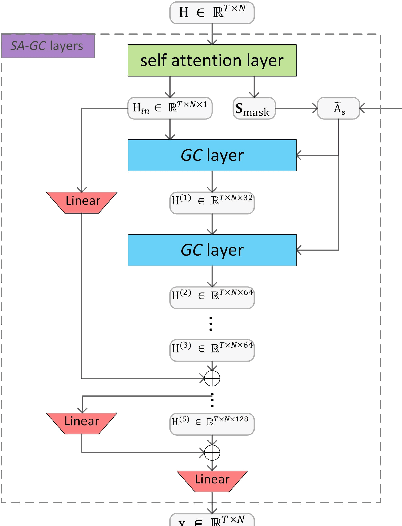
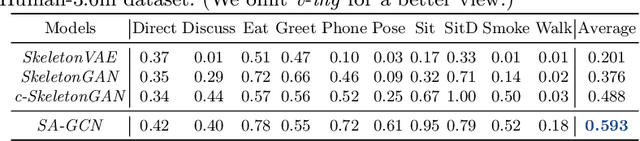
Generating long-range skeleton-based human actions has been a challenging problem since small deviations of one frame can cause a malformed action sequence. Most existing methods borrow ideas from video generation, which naively treat skeleton nodes/joints as pixels of images without considering the rich inter-frame and intra-frame structure information, leading to potential distorted actions. Graph convolutional networks (GCNs) is a promising way to leverage structure information to learn structure representations. However, directly adopting GCNs to tackle such continuous action sequences both in spatial and temporal spaces is challenging as the action graph could be huge. To overcome this issue, we propose a variant of GCNs to leverage the powerful self-attention mechanism to adaptively sparsify a complete action graph in the temporal space. Our method could dynamically attend to important past frames and construct a sparse graph to apply in the GCN framework, well-capturing the structure information in action sequences. Extensive experimental results demonstrate the superiority of our method on two standard human action datasets compared with existing methods.
Generative Semantic Hashing Enhanced via Boltzmann Machines
Jun 16, 2020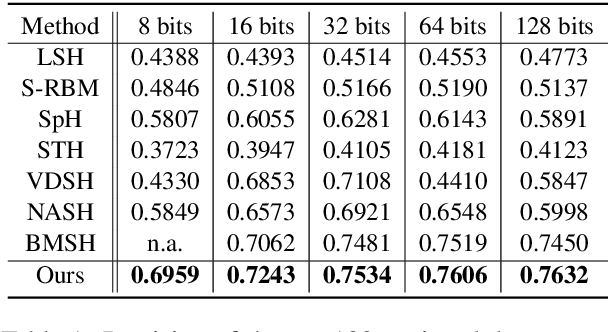
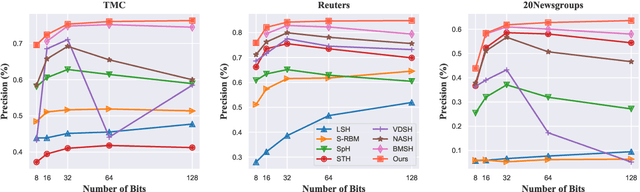
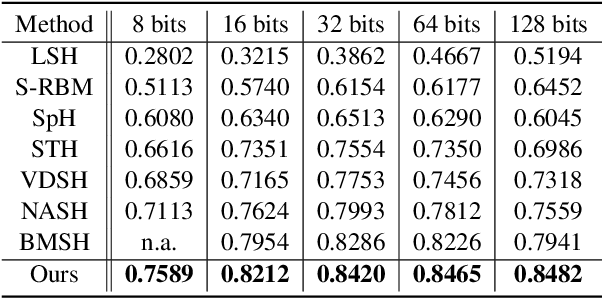

Generative semantic hashing is a promising technique for large-scale information retrieval thanks to its fast retrieval speed and small memory footprint. For the tractability of training, existing generative-hashing methods mostly assume a factorized form for the posterior distribution, enforcing independence among the bits of hash codes. From the perspectives of both model representation and code space size, independence is always not the best assumption. In this paper, to introduce correlations among the bits of hash codes, we propose to employ the distribution of Boltzmann machine as the variational posterior. To address the intractability issue of training, we first develop an approximate method to reparameterize the distribution of a Boltzmann machine by augmenting it as a hierarchical concatenation of a Gaussian-like distribution and a Bernoulli distribution. Based on that, an asymptotically-exact lower bound is further derived for the evidence lower bound (ELBO). With these novel techniques, the entire model can be optimized efficiently. Extensive experimental results demonstrate that by effectively modeling correlations among different bits within a hash code, our model can achieve significant performance gains.
Towards Understanding the Adversarial Vulnerability of Skeleton-based Action Recognition
Jun 06, 2020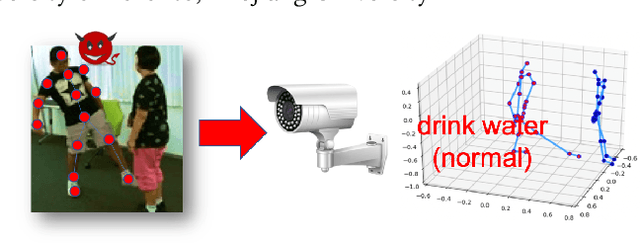
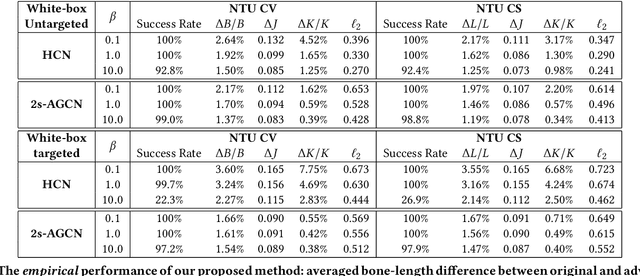
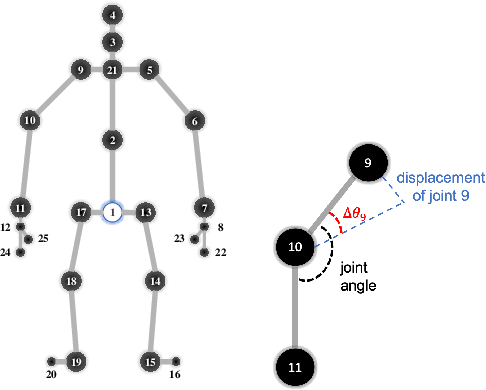
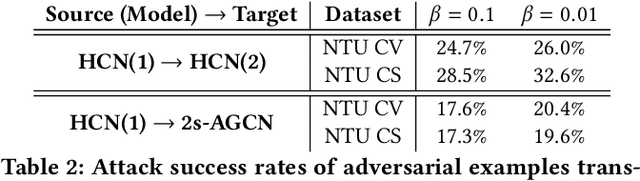
Skeleton-based action recognition has attracted increasing attention due to its strong adaptability to dynamic circumstances and potential for broad applications such as autonomous and anonymous surveillance. With the help of deep learning techniques, it has also witnessed substantial progress and currently achieved around 90\% accuracy in benign environment. On the other hand, research on the vulnerability of skeleton-based action recognition under different adversarial settings remains scant, which may raise security concerns about deploying such techniques into real-world systems. However, filling this research gap is challenging due to the unique physical constraints of skeletons and human actions. In this paper, we attempt to conduct a thorough study towards understanding the adversarial vulnerability of skeleton-based action recognition. We first formulate generation of adversarial skeleton actions as a constrained optimization problem by representing or approximating the physiological and physical constraints with mathematical formulations. Since the primal optimization problem with equality constraints is intractable, we propose to solve it by optimizing its unconstrained dual problem using ADMM. We then specify an efficient plug-in defense, inspired by recent theories and empirical observations, against the adversarial skeleton actions. Extensive evaluations demonstrate the effectiveness of the attack and defense method under different settings.
Graph Neural Networks with Composite Kernels
May 16, 2020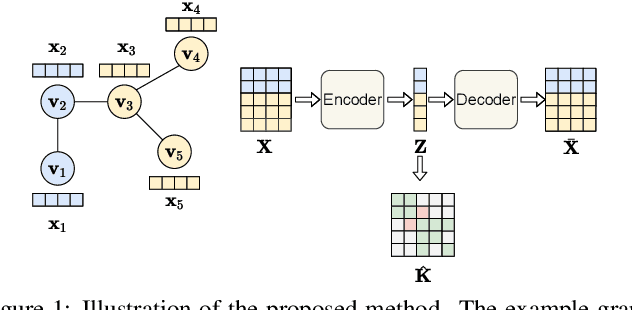
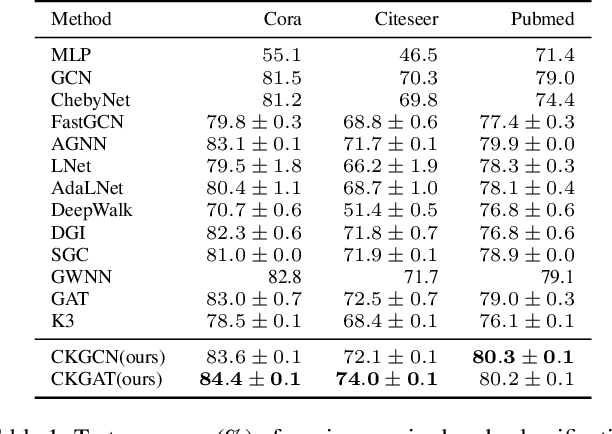
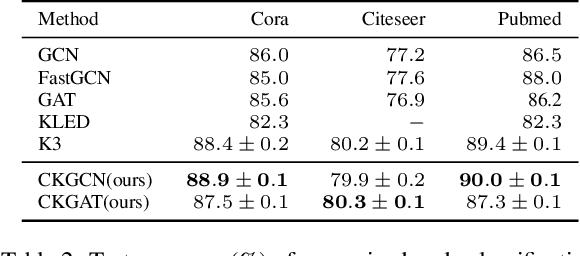

Learning on graph structured data has drawn increasing interest in recent years. Frameworks like Graph Convolutional Networks (GCNs) have demonstrated their ability to capture structural information and obtain good performance in various tasks. In these frameworks, node aggregation schemes are typically used to capture structural information: a node's feature vector is recursively computed by aggregating features of its neighboring nodes. However, most of aggregation schemes treat all connections in a graph equally, ignoring node feature similarities. In this paper, we re-interpret node aggregation from the perspective of kernel weighting, and present a framework to consider feature similarity in an aggregation scheme. Specifically, we show that normalized adjacency matrix is equivalent to a neighbor-based kernel matrix in a Krein Space. We then propose feature aggregation as the composition of the original neighbor-based kernel and a learnable kernel to encode feature similarities in a feature space. We further show how the proposed method can be extended to Graph Attention Network (GAT). Experimental results demonstrate better performance of our proposed framework in several real-world applications.
Reward Constrained Interactive Recommendation with Natural Language Feedback
May 04, 2020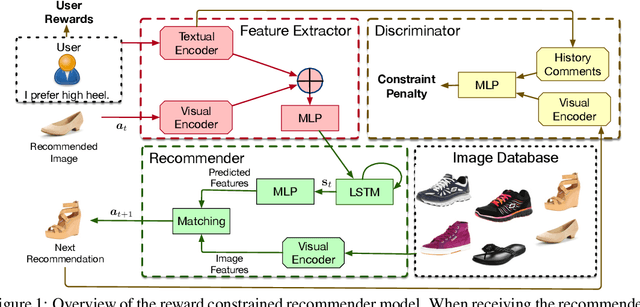



Text-based interactive recommendation provides richer user feedback and has demonstrated advantages over traditional interactive recommender systems. However, recommendations can easily violate preferences of users from their past natural-language feedback, since the recommender needs to explore new items for further improvement. To alleviate this issue, we propose a novel constraint-augmented reinforcement learning (RL) framework to efficiently incorporate user preferences over time. Specifically, we leverage a discriminator to detect recommendations violating user historical preference, which is incorporated into the standard RL objective of maximizing expected cumulative future rewards. Our proposed framework is general and is further extended to the task of constrained text generation. Empirical results show that the proposed method yields consistent improvement relative to standard RL methods.
Improving Adversarial Text Generation by Modeling the Distant Future
May 04, 2020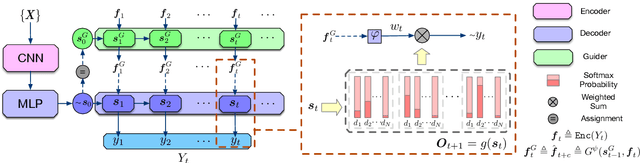
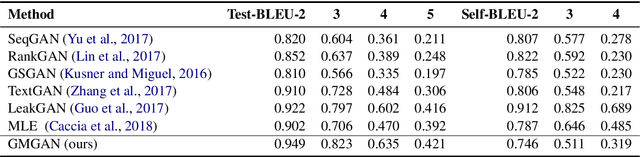
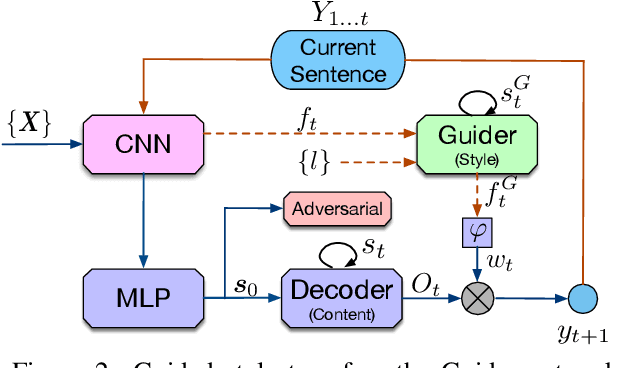
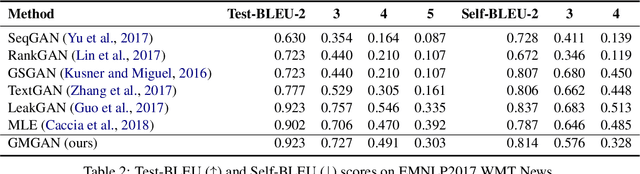
Auto-regressive text generation models usually focus on local fluency, and may cause inconsistent semantic meaning in long text generation. Further, automatically generating words with similar semantics is challenging, and hand-crafted linguistic rules are difficult to apply. We consider a text planning scheme and present a model-based imitation-learning approach to alleviate the aforementioned issues. Specifically, we propose a novel guider network to focus on the generative process over a longer horizon, which can assist next-word prediction and provide intermediate rewards for generator optimization. Extensive experiments demonstrate that the proposed method leads to improved performance.
Towards Faithful Neural Table-to-Text Generation with Content-Matching Constraints
May 03, 2020
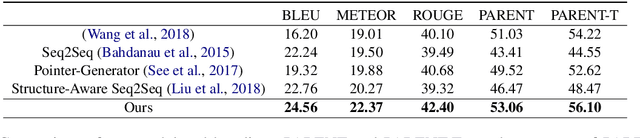
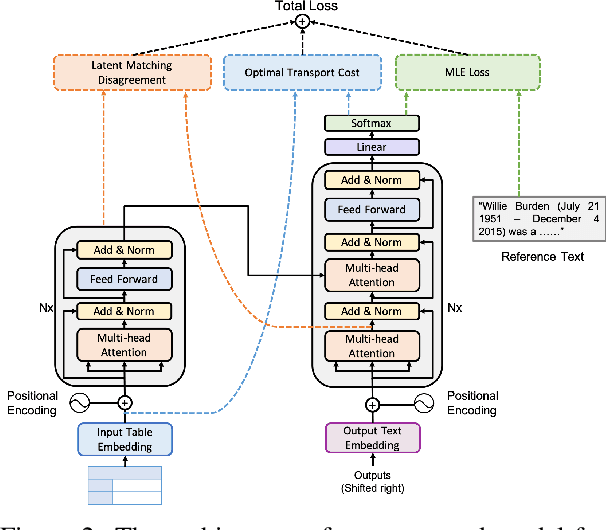
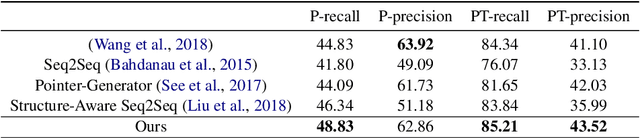
Text generation from a knowledge base aims to translate knowledge triples to natural language descriptions. Most existing methods ignore the faithfulness between a generated text description and the original table, leading to generated information that goes beyond the content of the table. In this paper, for the first time, we propose a novel Transformer-based generation framework to achieve the goal. The core techniques in our method to enforce faithfulness include a new table-text optimal-transport matching loss and a table-text embedding similarity loss based on the Transformer model. Furthermore, to evaluate faithfulness, we propose a new automatic metric specialized to the table-to-text generation problem. We also provide detailed analysis on each component of our model in our experiments. Automatic and human evaluations show that our framework can significantly outperform state-of-the-art by a large margin.