 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Diverse Stochastic Human-Action Generators by Learning Smooth Latent Transitions
Paper and Code
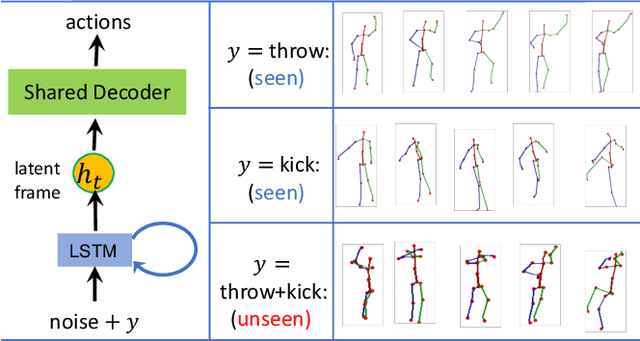

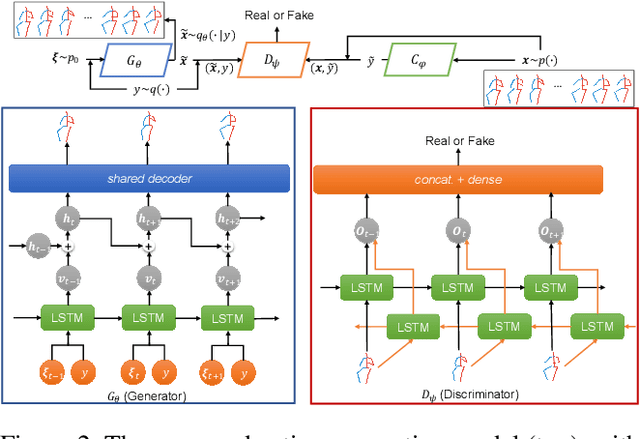

Human-motion generation is a long-standing challenging task due to the requirement of accurately modeling complex and diverse dynamic patterns. Most existing methods adopt sequence models such as RNN to directly model transitions in the original action space. Due to high dimensionality and potential noise, such modeling of action transitions is particularly challenging. In this paper, we focus on skeleton-based action generation and propose to model smooth and diverse transitions on a latent space of action sequences with much lower dimensionality. Conditioned on a latent sequence, actions are generated by a frame-wise decoder shared by all latent action-poses. Specifically, an implicit RNN is defined to model smooth latent sequences, whose randomness (diversity) is controlled by noise from the input. Different from standard action-prediction methods, our model can generate action sequences from pure noise without any conditional action poses. Remarkably, it can also generate unseen actions from mixed classes during training. Our model is learned with a bi-directional generative-adversarial-net framework, which not only can generate diverse action sequences of a particular class or mix classes, but also learns to classify action sequences within the same model. Experimental results show the superiority of our method in both diverse action-sequence generation and classification, relative to existing methods.