 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Constrained Interactive Recommendation with Natural Language Feedback
Paper and Code
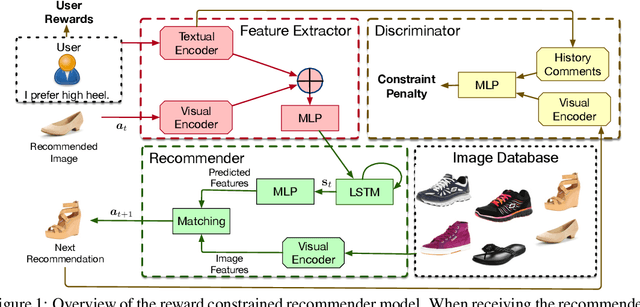



Text-based interactive recommendation provides richer user feedback and has demonstrated advantages over traditional interactive recommender systems. However, recommendations can easily violate preferences of users from their past natural-language feedback, since the recommender needs to explore new items for further improvement. To alleviate this issue, we propose a novel constraint-augmented reinforcement learning (RL) framework to efficiently incorporate user preferences over time. Specifically, we leverage a discriminator to detect recommendations violating user historical preference, which is incorporated into the standard RL objective of maximizing expected cumulative future rewards. Our proposed framework is general and is further extended to the task of constrained text generation. Empirical results show that the proposed method yields consistent improvement relative to standard RL methods.