 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal & Cross-domain Learning for Unsupervised LiDAR Semantic Segmentation
Aug 05, 2023In recent years, cross-modal domain adaptation has been studied on the paired 2D image and 3D LiDAR data to ease the labeling costs for 3D LiDAR semantic segmentation (3DLSS) in the target domain. However, in such a setting the paired 2D and 3D data in the source domain are still collected with additional effort. Since the 2D-3D projections can enable the 3D model to learn semantic information from the 2D counterpart, we ask whether we could further remove the need of source 3D data and only rely on the source 2D images. To answer it, this paper studies a new 3DLSS setting where a 2D dataset (source) with semantic annotations and a paired but unannotated 2D image and 3D LiDAR data (target) are available. To achieve 3DLSS in this scenario, we propose Cross-Modal and Cross-Domain Learning (CoMoDaL). Specifically, our CoMoDaL aims at modeling 1) inter-modal cross-domain distillation between the unpaired source 2D image and target 3D LiDAR data, and 2) the intra-domain cross-modal guidance between the target 2D image and 3D LiDAR data pair. In CoMoDaL, we propose to apply several constraints, such as point-to-pixel and prototype-to-pixel alignments, to associate the semantics in different modalities and domains by constructing mixed samples in two modalities. The experimental results on several datasets show that in the proposed setting, the developed CoMoDaL can achieve segmentation without the supervision of labeled LiDAR data. Ablations are also conducted to provide more analysis. Code will be available publicly.
MMoT: Mixture-of-Modality-Tokens Transformer for Composed Multimodal Conditional Image Synthesis
May 10, 2023



Existing multimodal conditional image synthesis (MCIS) methods generate images conditioned on any combinations of various modalities that require all of them must be exactly conformed, hindering the synthesis controllability and leaving the potential of cross-modality under-exploited. To this end, we propose to generate images conditioned on the compositions of multimodal control signals, where modalities are imperfectly complementary, i.e., composed multimodal conditional image synthesis (CMCIS). Specifically, we observe two challenging issues of the proposed CMCIS task, i.e., the modality coordination problem and the modality imbalance problem. To tackle these issues, we introduce a Mixture-of-Modality-Tokens Transformer (MMoT) that adaptively fuses fine-grained multimodal control signals, a multimodal balanced training loss to stabilize the optimization of each modality, and a multimodal sampling guidance to balance the strength of each modality control signal. Comprehensive experimental results demonstrate that MMoT achieves superior performance on both unimodal conditional image synthesis (UCIS) and MCIS tasks with high-quality and faithful image synthesis on complex multimodal conditions. The project website is available at https://jabir-zheng.github.io/MMoT.
Mining False Positive Examples for Text-Based Person Re-identification
Mar 15, 2023



Text-based person re-identification (ReID) aims to identify images of the targeted person from a large-scale person image database according to a given textual description. However, due to significant inter-modal gaps, text-based person ReID remains a challenging problem. Most existing methods generally rely heavily on the similarity contributed by matched word-region pairs, while neglecting mismatched word-region pairs which may play a decisive role. Accordingly, we propose to mine false positive examples (MFPE) via a jointly optimized multi-branch architecture to handle this problem. MFPE contains three branches including a false positive mining (FPM) branch to highlight the role of mismatched word-region pairs. Besides, MFPE delicately designs a cross-relu loss to increase the gap of similarity scores between matched and mismatched word-region pairs. Extensive experiments on CUHK-PEDES demonstrate the superior effectiveness of MFPE. Our code is released at https://github.com/xx-adeline/MFPE.
HelixSurf: A Robust and Efficient Neural Implicit Surface Learning of Indoor Scenes with Iterative Intertwined Regularization
Mar 01, 2023Recovery of an underlying scene geometry from multiview images stands as a long-time challenge in computer vision research. The recent promise leverages neural implicit surface learning and differentiable volume rendering, and achieves both the recovery of scene geometry and synthesis of novel views, where deep priors of neural models are used as an inductive smoothness bias. While promising for object-level surfaces, these methods suffer when coping with complex scene surfaces. In the meanwhile, traditional multi-view stereo can recover the geometry of scenes with rich textures, by globally optimizing the local, pixel-wise correspondences across multiple views. We are thus motivated to make use of the complementary benefits from the two strategies, and propose a method termed Helix-shaped neural implicit Surface learning or HelixSurf; HelixSurf uses the intermediate prediction from one strategy as the guidance to regularize the learning of the other one, and conducts such intertwined regularization iteratively during the learning process. We also propose an efficient scheme for differentiable volume rendering in HelixSurf. Experiments on surface reconstruction of indoor scenes show that our method compares favorably with existing methods and is orders of magnitude faster, even when some of existing methods are assisted with auxiliary training data. The source code is available at https://github.com/Gorilla-Lab-SCUT/HelixSurf.
Learning Granularity-Unified Representations for Text-to-Image Person Re-identification
Jul 16, 2022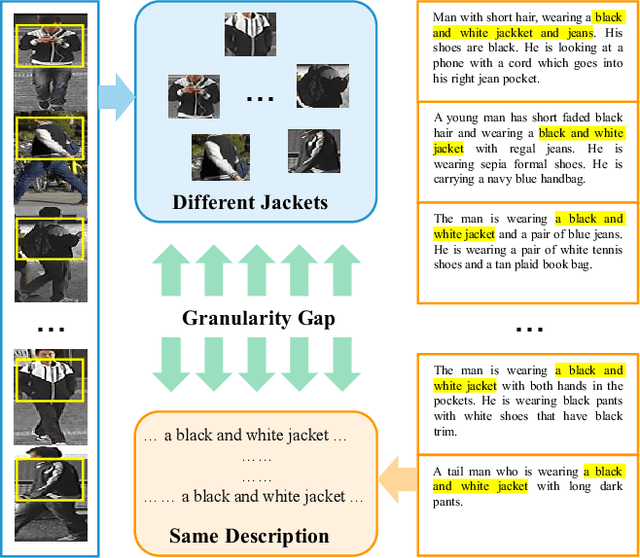
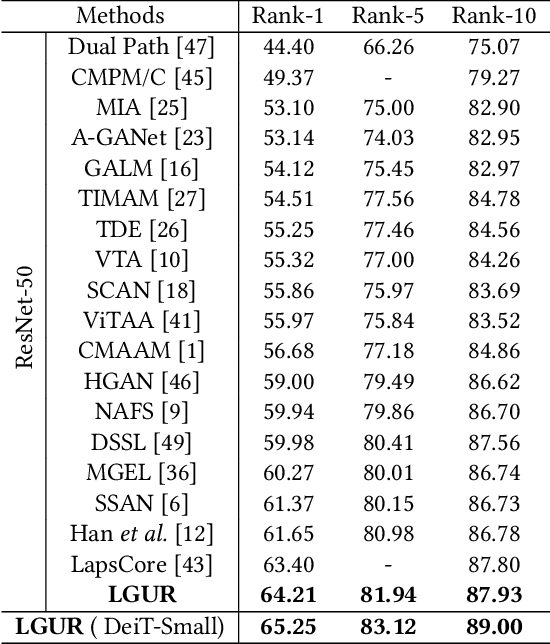
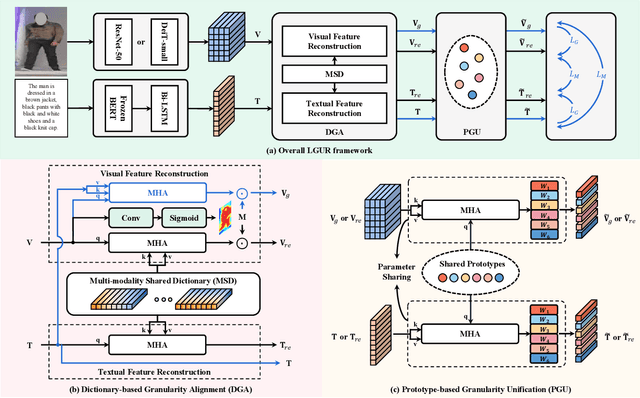
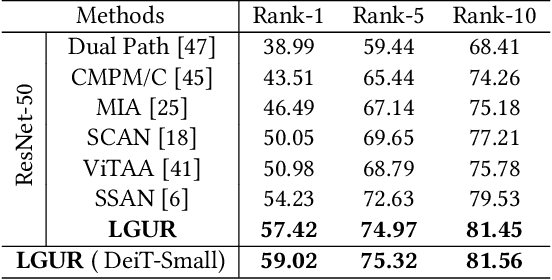
Text-to-image person re-identification (ReID) aims to search for pedestrian images of an interested identity via textual descriptions. It is challenging due to both rich intra-modal variations and significant inter-modal gaps. Existing works usually ignore the difference in feature granularity between the two modalities, i.e., the visual features are usually fine-grained while textual features are coarse, which is mainly responsible for the large inter-modal gaps. In this paper, we propose an end-to-end framework based on transformers to learn granularity-unified representations for both modalities, denoted as LGUR. LGUR framework contains two modules: a Dictionary-based Granularity Alignment (DGA) module and a Prototype-based Granularity Unification (PGU) module. In DGA, in order to align the granularities of two modalities, we introduce a Multi-modality Shared Dictionary (MSD) to reconstruct both visual and textual features. Besides, DGA has two important factors, i.e., the cross-modality guidance and the foreground-centric reconstruction, to facilitate the optimization of MSD. In PGU, we adopt a set of shared and learnable prototypes as the queries to extract diverse and semantically aligned features for both modalities in the granularity-unified feature space, which further promotes the ReID performance. Comprehensive experiments show that our LGUR consistently outperforms state-of-the-arts by large margins on both CUHK-PEDES and ICFG-PEDES datasets. Code will be released at https://github.com/ZhiyinShao-H/LGUR.
Category-Level 6D Object Pose and Size Estimation using Self-Supervised Deep Prior Deformation Networks
Jul 12, 2022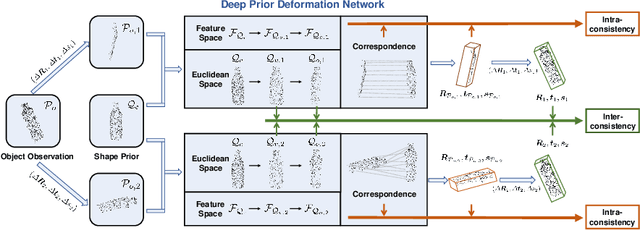
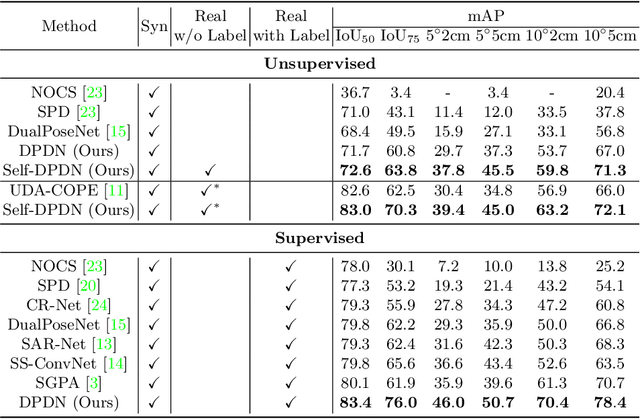
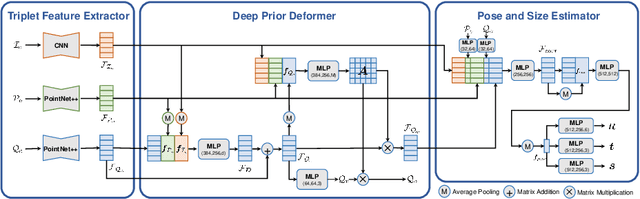
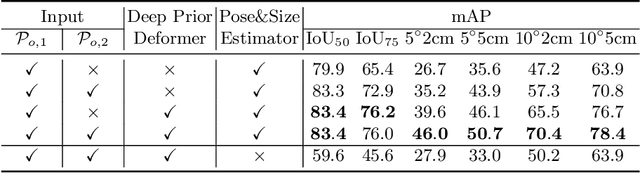
It is difficult to precisely annotate object instances and their semantics in 3D space, and as such, synthetic data are extensively used for these tasks, e.g., category-level 6D object pose and size estimation. However, the easy annotations in synthetic domains bring the downside effect of synthetic-to-real (Sim2Real) domain gap. In this work, we aim to address this issue in the task setting of Sim2Real, unsupervised domain adaptation for category-level 6D object pose and size estimation. We propose a method that is built upon a novel Deep Prior Deformation Network, shortened as DPDN. DPDN learns to deform features of categorical shape priors to match those of object observations, and is thus able to establish deep correspondence in the feature space for direct regression of object poses and sizes. To reduce the Sim2Real domain gap, we formulate a novel self-supervised objective upon DPDN via consistency learning; more specifically, we apply two rigid transformations to each object observation in parallel, and feed them into DPDN respectively to yield dual sets of predictions; on top of the parallel learning, an inter-consistency term is employed to keep cross consistency between dual predictions for improving the sensitivity of DPDN to pose changes, while individual intra-consistency ones are used to enforce self-adaptation within each learning itself. We train DPDN on both training sets of the synthetic CAMERA25 and real-world REAL275 datasets; our results outperform the existing methods on REAL275 test set under both the unsupervised and supervised settings. Ablation studies also verify the efficacy of our designs. Our code is released publicly at https://github.com/JiehongLin/Self-DPDN.
Towards Hard-Positive Query Mining for DETR-based Human-Object Interaction Detection
Jul 12, 2022
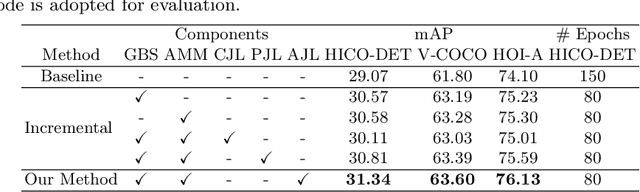
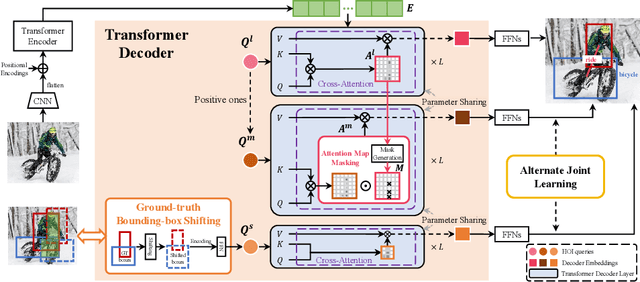
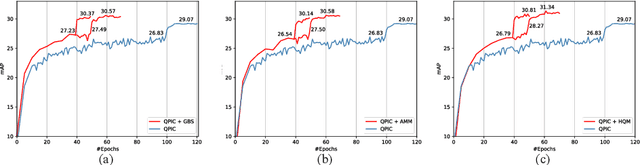
Human-Object Interaction (HOI) detection is a core task for high-level image understanding. Recently, Detection Transformer (DETR)-based HOI detectors have become popular due to their superior performance and efficient structure. However, these approaches typically adopt fixed HOI queries for all testing images, which is vulnerable to the location change of objects in one specific image. Accordingly, in this paper, we propose to enhance DETR's robustness by mining hard-positive queries, which are forced to make correct predictions using partial visual cues. First, we explicitly compose hard-positive queries according to the ground-truth (GT) position of labeled human-object pairs for each training image. Specifically, we shift the GT bounding boxes of each labeled human-object pair so that the shifted boxes cover only a certain portion of the GT ones. We encode the coordinates of the shifted boxes for each labeled human-object pair into an HOI query. Second, we implicitly construct another set of hard-positive queries by masking the top scores in cross-attention maps of the decoder layers. The masked attention maps then only cover partial important cues for HOI predictions. Finally, an alternate strategy is proposed that efficiently combines both types of hard queries. In each iteration, both DETR's learnable queries and one selected type of hard-positive queries are adopted for loss computation. Experimental results show that our proposed approach can be widely applied to existing DETR-based HOI detectors. Moreover, we consistently achieve state-of-the-art performance on three benchmarks: HICO-DET, V-COCO, and HOI-A. Code is available at https://github.com/MuchHair/HQM.
1st Place Solution to the EPIC-Kitchens Action Anticipation Challenge 2022
Jul 10, 2022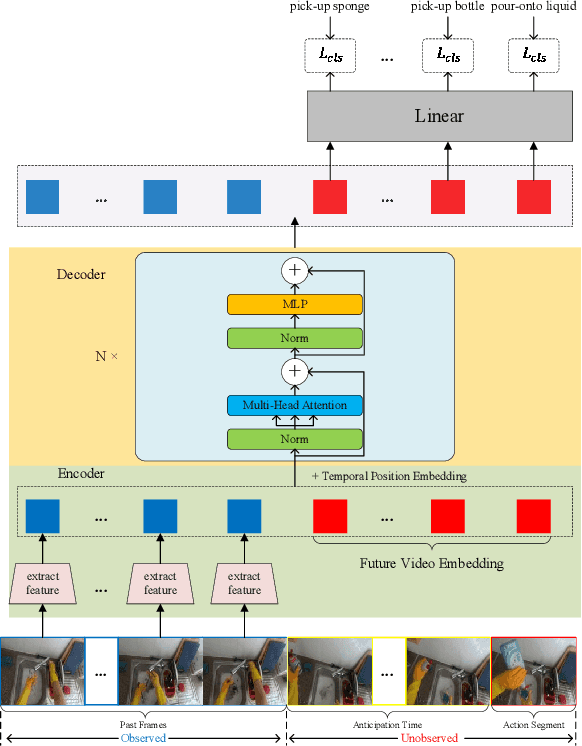
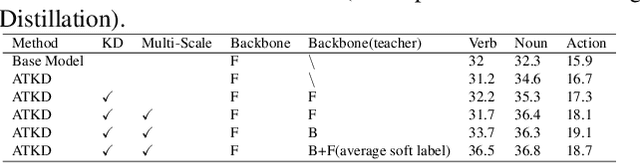
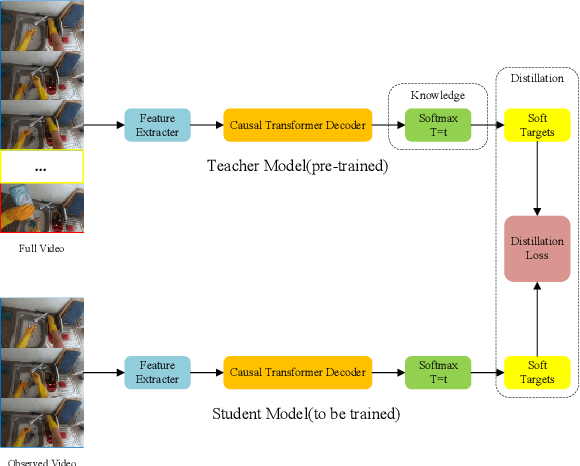
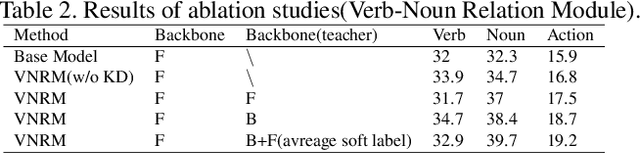
In this report, we describe the technical details of our submission to the EPIC-Kitchens Action Anticipation Challenge 2022. In this competition, we develop the following two approaches. 1) Anticipation Time Knowledge Distillation using the soft labels learned by the teacher model as knowledge to guide the student network to learn the information of anticipation time; 2) Verb-Noun Relation Module for building the relationship between verbs and nouns. Our method achieves state-of-the-art results on the testing set of EPIC-Kitchens Action Anticipation Challenge 2022.
Style Interleaved Learning for Generalizable Person Re-identification
Jul 07, 2022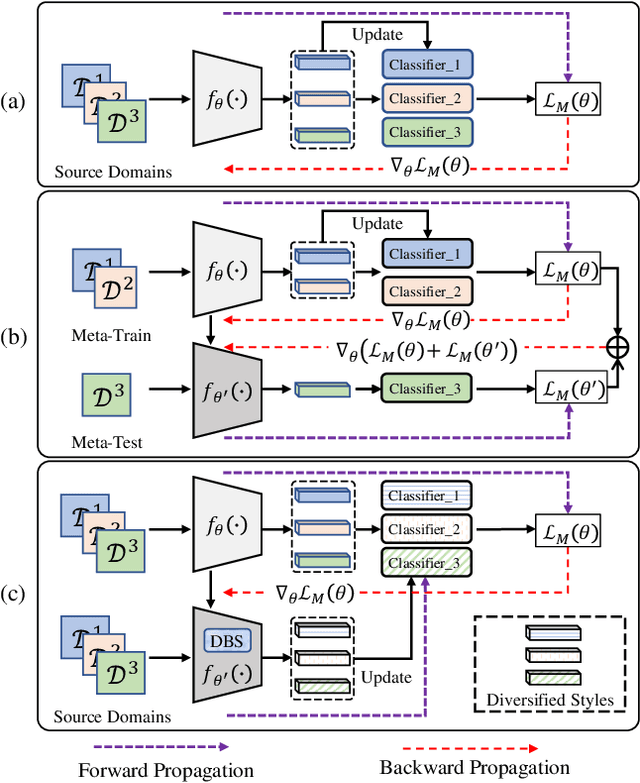
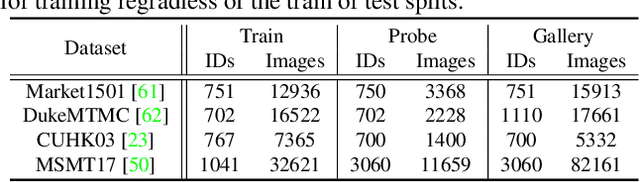
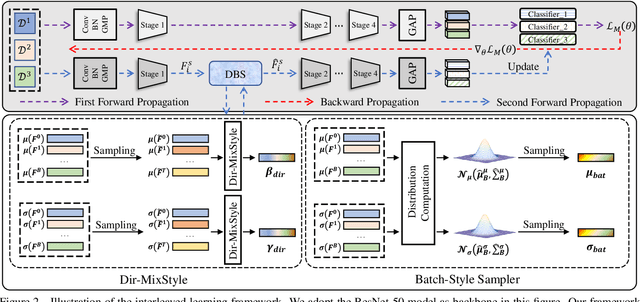
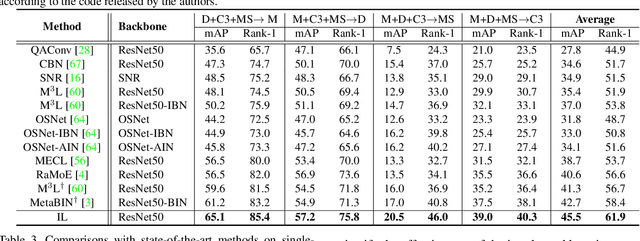
Domain generalization (DG) for person re-identification (ReID) is a challenging problem, as there is no access to target domain data permitted during the training process. Most existing DG ReID methods employ the same features for the updating of the feature extractor and classifier parameters. This common practice causes the model to overfit to existing feature styles in the source domain, resulting in sub-optimal generalization ability on target domains even if meta-learning is used. To solve this problem, we propose a novel style interleaved learning framework. Unlike conventional learning strategies, interleaved learning incorporates two forward propagations and one backward propagation for each iteration. We employ the features of interleaved styles to update the feature extractor and classifiers using different forward propagations, which helps the model avoid overfitting to certain domain styles. In order to fully explore the advantages of style interleaved learning, we further propose a novel feature stylization approach to diversify feature styles. This approach not only mixes the feature styles of multiple training samples, but also samples new and meaningful feature styles from batch-level style distribution. Extensive experimental results show that our model consistently outperforms state-of-the-art methods on large-scale benchmarks for DG ReID, yielding clear advantages in computational efficiency. Code is available at https://github.com/WentaoTan/Interleaved-Learning.
Context Sensing Attention Network for Video-based Person Re-identification
Jul 06, 2022

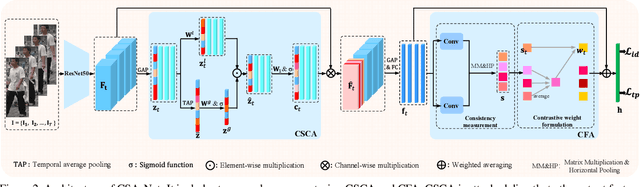
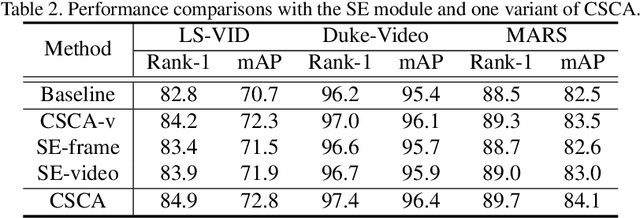
Video-based person re-identification (ReID) is challenging due to the presence of various interferences in video frames. Recent approaches handle this problem using temporal aggregation strategies. In this work, we propose a novel Context Sensing Attention Network (CSA-Net), which improves both the frame feature extraction and temporal aggregation steps. First, we introduce the Context Sensing Channel Attention (CSCA) module, which emphasizes responses from informative channels for each frame. These informative channels are identified with reference not only to each individual frame, but also to the content of the entire sequence. Therefore, CSCA explores both the individuality of each frame and the global context of the sequence. Second, we propose the Contrastive Feature Aggregation (CFA) module, which predicts frame weights for temporal aggregation. Here, the weight for each frame is determined in a contrastive manner: i.e., not only by the quality of each individual frame, but also by the average quality of the other frames in a sequence. Therefore, it effectively promotes the contribution of relatively good frames. Extensive experimental results on four datasets show that CSA-Net consistently achieves state-of-the-art performance.