 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAspect-oriented Opinion Alignment Network for Aspect-Based Sentiment Classification
Aug 22, 2023Aspect-based sentiment classification is a crucial problem in fine-grained sentiment analysis, which aims to predict the sentiment polarity of the given aspect according to its context. Previous works have made remarkable progress in leveraging attention mechanism to extract opinion words for different aspects. However, a persistent challenge is the effective management of semantic mismatches, which stem from attention mechanisms that fall short in adequately aligning opinions words with their corresponding aspect in multi-aspect sentences. To address this issue, we propose a novel Aspect-oriented Opinion Alignment Network (AOAN) to capture the contextual association between opinion words and the corresponding aspect. Specifically, we first introduce a neighboring span enhanced module which highlights various compositions of neighboring words and given aspects. In addition, we design a multi-perspective attention mechanism that align relevant opinion information with respect to the given aspect. Extensive experiments on three benchmark datasets demonstrate that our model achieves state-of-the-art results. The source code is available at https://github.com/AONE-NLP/ABSA-AOAN.
MixReorg: Cross-Modal Mixed Patch Reorganization is a Good Mask Learner for Open-World Semantic Segmentation
Aug 09, 2023



Recently, semantic segmentation models trained with image-level text supervision have shown promising results in challenging open-world scenarios. However, these models still face difficulties in learning fine-grained semantic alignment at the pixel level and predicting accurate object masks. To address this issue, we propose MixReorg, a novel and straightforward pre-training paradigm for semantic segmentation that enhances a model's ability to reorganize patches mixed across images, exploring both local visual relevance and global semantic coherence. Our approach involves generating fine-grained patch-text pairs data by mixing image patches while preserving the correspondence between patches and text. The model is then trained to minimize the segmentation loss of the mixed images and the two contrastive losses of the original and restored features. With MixReorg as a mask learner, conventional text-supervised semantic segmentation models can achieve highly generalizable pixel-semantic alignment ability, which is crucial for open-world segmentation. After training with large-scale image-text data, MixReorg models can be applied directly to segment visual objects of arbitrary categories, without the need for further fine-tuning. Our proposed framework demonstrates strong performance on popular zero-shot semantic segmentation benchmarks, outperforming GroupViT by significant margins of 5.0%, 6.2%, 2.5%, and 3.4% mIoU on PASCAL VOC2012, PASCAL Context, MS COCO, and ADE20K, respectively.
H-VFI: Hierarchical Frame Interpolation for Videos with Large Motions
Nov 21, 2022



Capitalizing on the rapid development of neural networks, recent video frame interpolation (VFI) methods have achieved notable improvements. However, they still fall short for real-world videos containing large motions. Complex deformation and/or occlusion caused by large motions make it an extremely difficult problem in video frame interpolation. In this paper, we propose a simple yet effective solution, H-VFI, to deal with large motions in video frame interpolation. H-VFI contributes a hierarchical video interpolation transformer (HVIT) to learn a deformable kernel in a coarse-to-fine strategy in multiple scales. The learnt deformable kernel is then utilized in convolving the input frames for predicting the interpolated frame. Starting from the smallest scale, H-VFI updates the deformable kernel by a residual in succession based on former predicted kernels, intermediate interpolated results and hierarchical features from transformer. Bias and masks to refine the final outputs are then predicted by a transformer block based on interpolated results. The advantage of such a progressive approximation is that the large motion frame interpolation problem can be decomposed into several relatively simpler sub-tasks, which enables a very accurate prediction in the final results. Another noteworthy contribution of our paper consists of a large-scale high-quality dataset, YouTube200K, which contains videos depicting a great variety of scenarios captured at high resolution and high frame rate. Extensive experiments on multiple frame interpolation benchmarks validate that H-VFI outperforms existing state-of-the-art methods especially for videos with large motions.
Learning Self-Regularized Adversarial Views for Self-Supervised Vision Transformers
Oct 16, 2022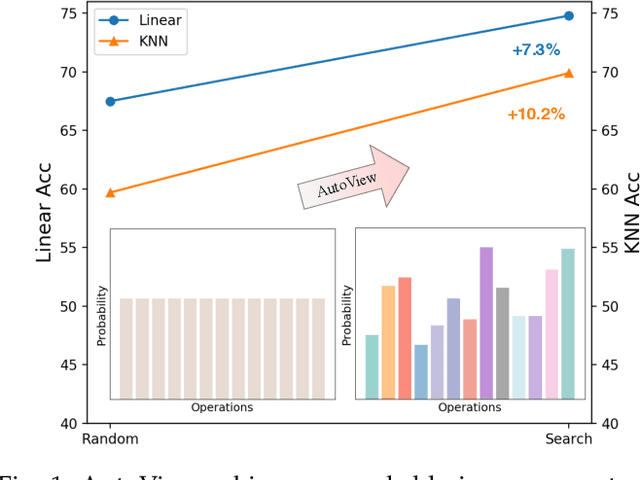
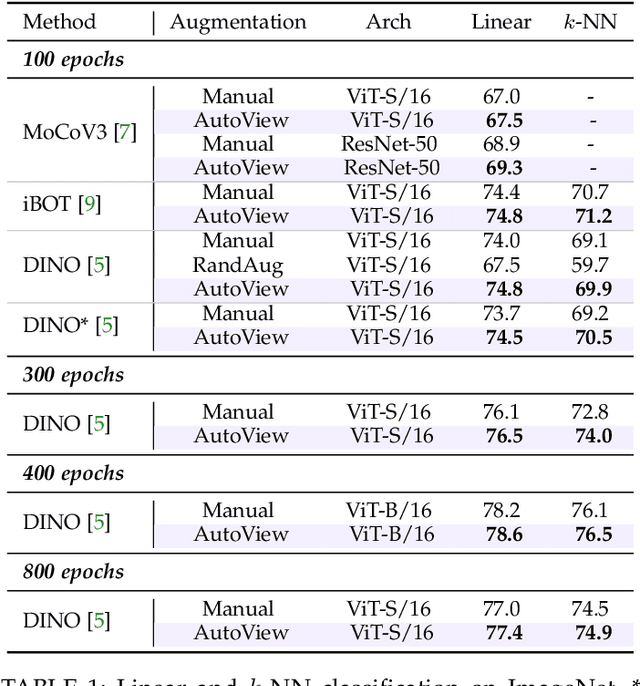
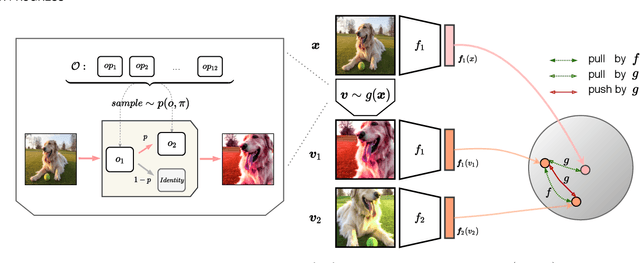

Automatic data augmentation (AutoAugment) strategies are indispensable in supervised data-efficient training protocols of vision transformers, and have led to state-of-the-art results in supervised learning. Despite the success, its development and application on self-supervised vision transformers have been hindered by several barriers, including the high search cost, the lack of supervision, and the unsuitable search space. In this work, we propose AutoView, a self-regularized adversarial AutoAugment method, to learn views for self-supervised vision transformers, by addressing the above barriers. First, we reduce the search cost of AutoView to nearly zero by learning views and network parameters simultaneously in a single forward-backward step, minimizing and maximizing the mutual information among different augmented views, respectively. Then, to avoid information collapse caused by the lack of label supervision, we propose a self-regularized loss term to guarantee the information propagation. Additionally, we present a curated augmentation policy search space for self-supervised learning, by modifying the generally used search space designed for supervised learning. On ImageNet, our AutoView achieves remarkable improvement over RandAug baseline (+10.2% k-NN accuracy), and consistently outperforms sota manually tuned view policy by a clear margin (up to +1.3% k-NN accuracy). Extensive experiments show that AutoView pretraining also benefits downstream tasks (+1.2% mAcc on ADE20K Semantic Segmentation and +2.8% mAP on revisited Oxford Image Retrieval benchmark) and improves model robustness (+2.3% Top-1 Acc on ImageNet-A and +1.0% AUPR on ImageNet-O). Code and models will be available at https://github.com/Trent-tangtao/AutoView.
DeViT: Deformed Vision Transformers in Video Inpainting
Sep 28, 2022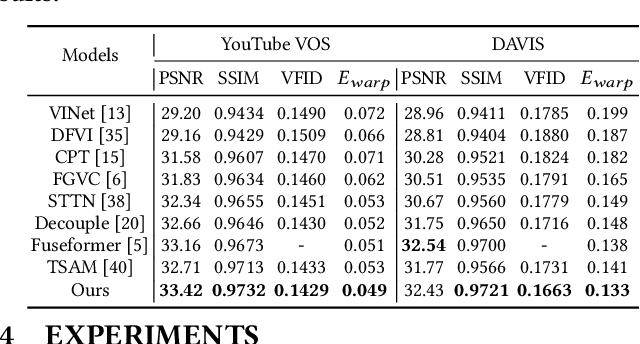
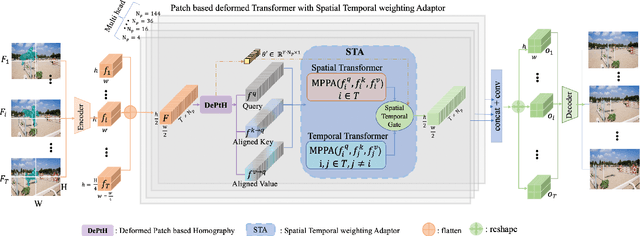
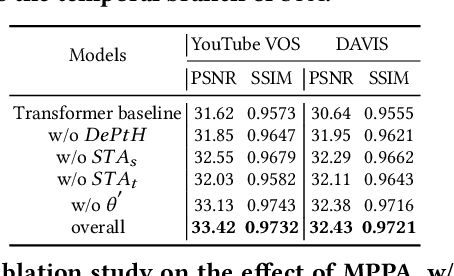
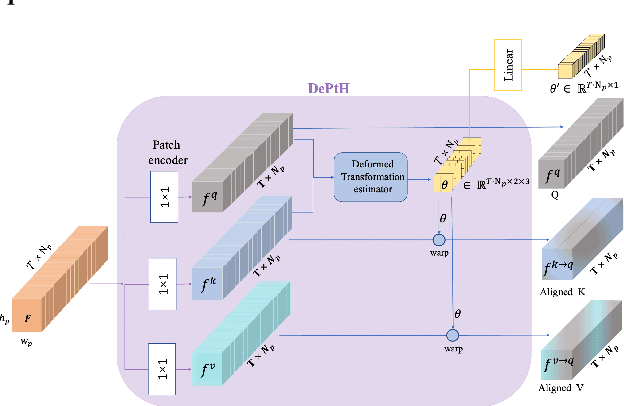
This paper proposes a novel video inpainting method. We make three main contributions: First, we extended previous Transformers with patch alignment by introducing Deformed Patch-based Homography (DePtH), which improves patch-level feature alignments without additional supervision and benefits challenging scenes with various deformation. Second, we introduce Mask Pruning-based Patch Attention (MPPA) to improve patch-wised feature matching by pruning out less essential features and using saliency map. MPPA enhances matching accuracy between warped tokens with invalid pixels. Third, we introduce a Spatial-Temporal weighting Adaptor (STA) module to obtain accurate attention to spatial-temporal tokens under the guidance of the Deformation Factor learned from DePtH, especially for videos with agile motions. Experimental results demonstrate that our method outperforms recent methods qualitatively and quantitatively and achieves a new state-of-the-art.
Generalizable Memory-driven Transformer for Multivariate Long Sequence Time-series Forecasting
Jul 16, 2022
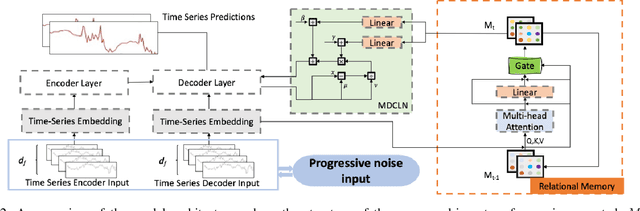
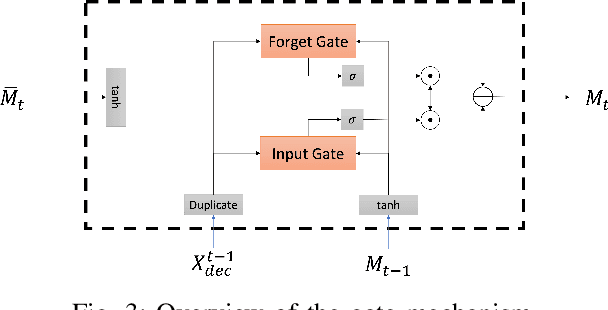
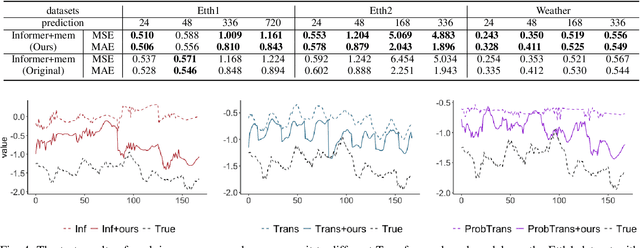
Multivariate long sequence time-series forecasting (M-LSTF) is a practical but challenging problem. Unlike traditional timer-series forecasting tasks, M-LSTF tasks are more challenging from two aspects: 1) M-LSTF models need to learn time-series patterns both within and between multiple time features; 2) Under the rolling forecasting setting, the similarity between two consecutive training samples increases with the increasing prediction length, which makes models more prone to overfitting. In this paper, we propose a generalizable memory-driven Transformer to target M-LSTF problems. Specifically, we first propose a global-level memory component to drive the forecasting procedure by integrating multiple time-series features. In addition, we adopt a progressive fashion to train our model to increase its generalizability, in which we gradually introduce Bernoulli noises to training samples. Extensive experiments have been performed on five different datasets across multiple fields. Experimental results demonstrate that our approach can be seamlessly plugged into varying Transformer-based models to improve their performances up to roughly 30%. Particularly, this is the first work to specifically focus on the M-LSTF tasks to the best of our knowledge.
Continual Object Detection via Prototypical Task Correlation Guided Gating Mechanism
May 06, 2022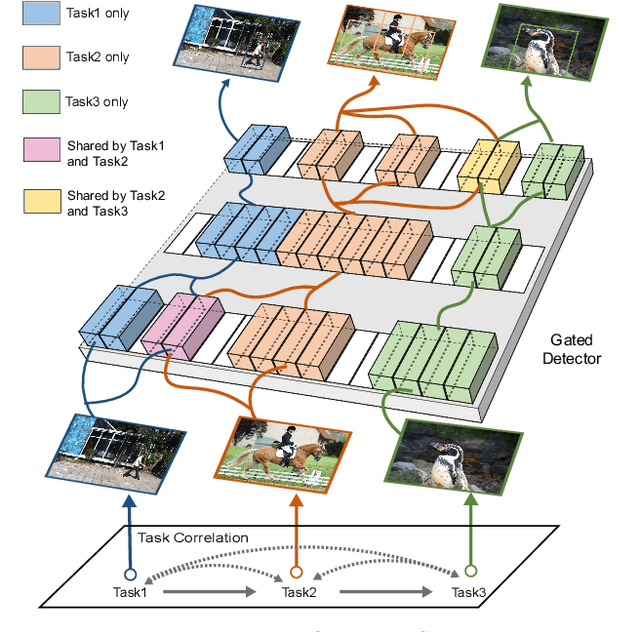
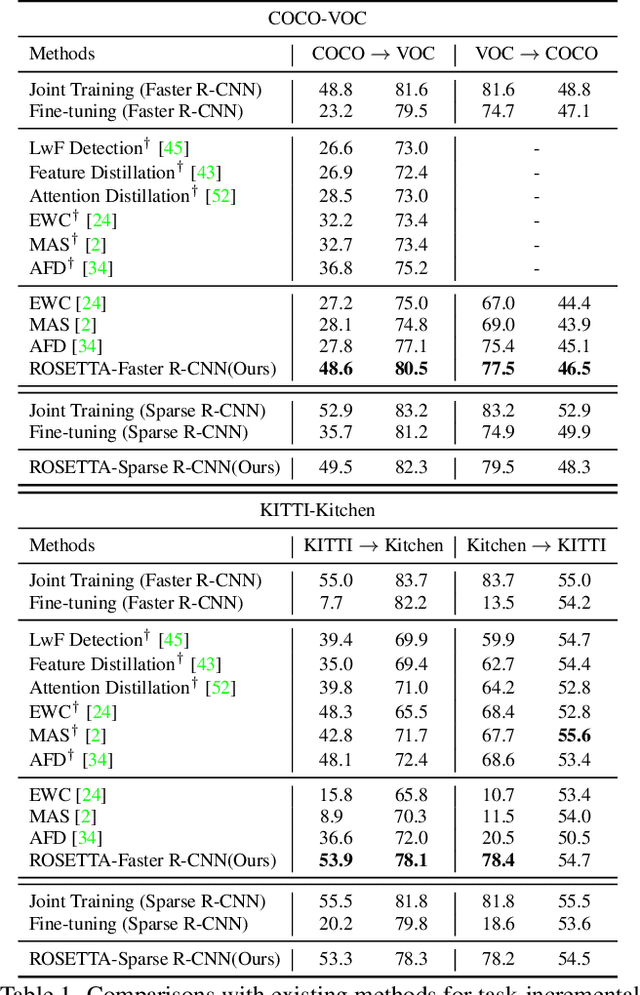
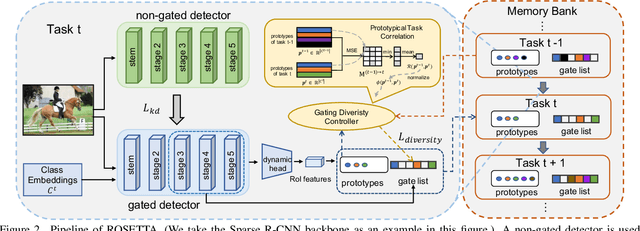
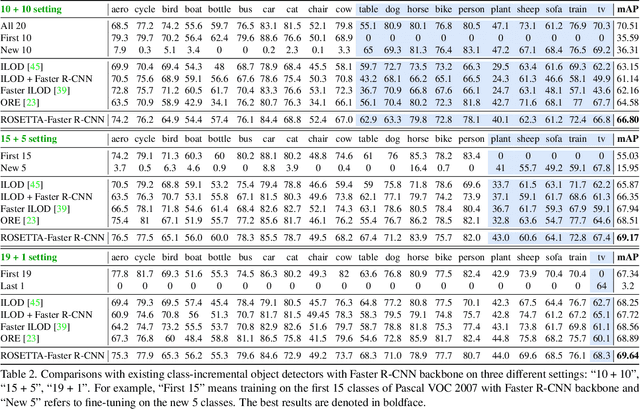
Continual learning is a challenging real-world problem for constructing a mature AI system when data are provided in a streaming fashion. Despite recent progress in continual classification, the researches of continual object detection are impeded by the diverse sizes and numbers of objects in each image. Different from previous works that tune the whole network for all tasks, in this work, we present a simple and flexible framework for continual object detection via pRotOtypical taSk corrElaTion guided gaTing mechAnism (ROSETTA). Concretely, a unified framework is shared by all tasks while task-aware gates are introduced to automatically select sub-models for specific tasks. In this way, various knowledge can be successively memorized by storing their corresponding sub-model weights in this system. To make ROSETTA automatically determine which experience is available and useful, a prototypical task correlation guided Gating Diversity Controller(GDC) is introduced to adaptively adjust the diversity of gates for the new task based on class-specific prototypes. GDC module computes class-to-class correlation matrix to depict the cross-task correlation, and hereby activates more exclusive gates for the new task if a significant domain gap is observed. Comprehensive experiments on COCO-VOC, KITTI-Kitchen, class-incremental detection on VOC and sequential learning of four tasks show that ROSETTA yields state-of-the-art performance on both task-based and class-based continual object detection.
Look Back and Forth: Video Super-Resolution with Explicit Temporal Difference Modeling
Apr 14, 2022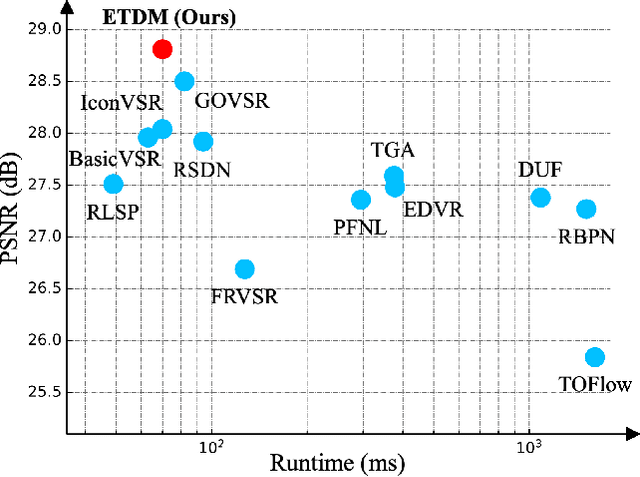
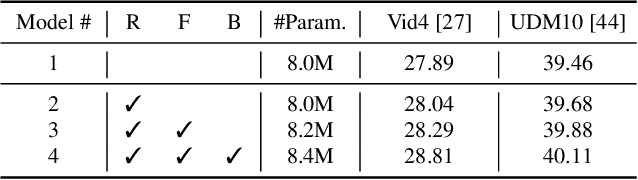
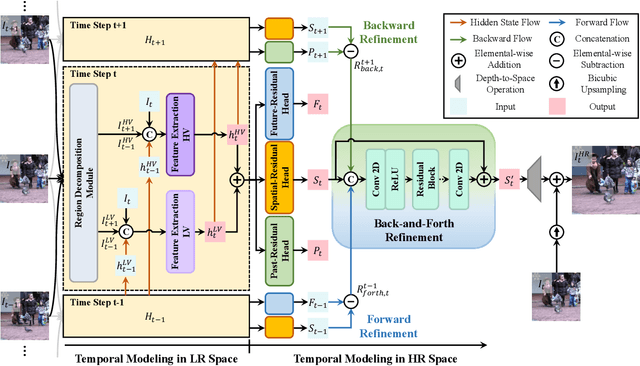
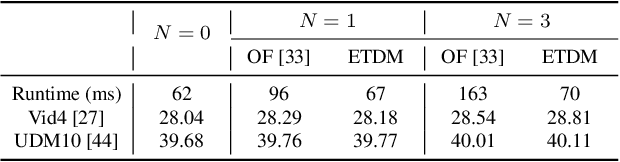
Temporal modeling is crucial for video super-resolution. Most of the video super-resolution methods adopt the optical flow or deformable convolution for explicitly motion compensation. However, such temporal modeling techniques increase the model complexity and might fail in case of occlusion or complex motion, resulting in serious distortion and artifacts. In this paper, we propose to explore the role of explicit temporal difference modeling in both LR and HR space. Instead of directly feeding consecutive frames into a VSR model, we propose to compute the temporal difference between frames and divide those pixels into two subsets according to the level of difference. They are separately processed with two branches of different receptive fields in order to better extract complementary information. To further enhance the super-resolution result, not only spatial residual features are extracted, but the difference between consecutive frames in high-frequency domain is also computed. It allows the model to exploit intermediate SR results in both future and past to refine the current SR output. The difference at different time steps could be cached such that information from further distance in time could be propagated to the current frame for refinement. Experiments on several video super-resolution benchmark datasets demonstrate the effectiveness of the proposed method and its favorable performance against state-of-the-art methods.
Arch-Graph: Acyclic Architecture Relation Predictor for Task-Transferable Neural Architecture Search
Apr 12, 2022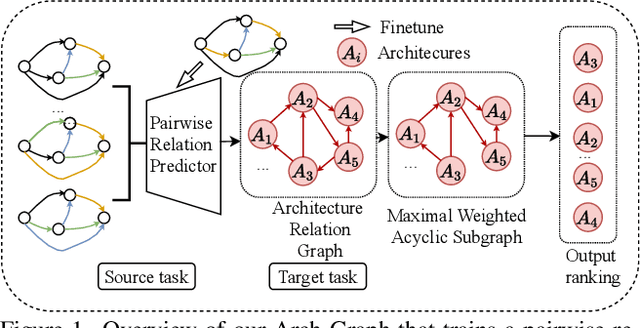
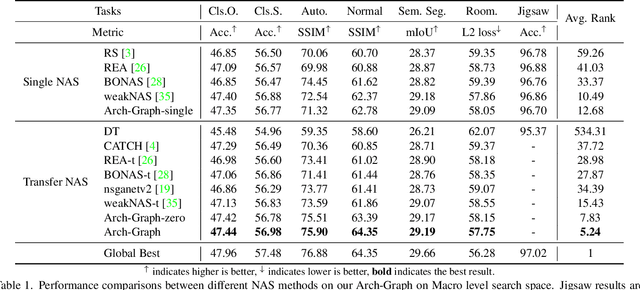
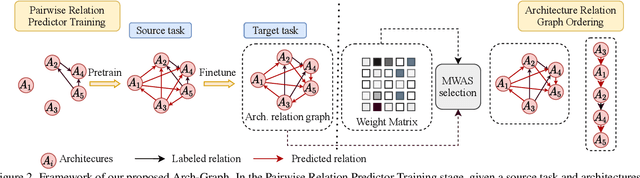
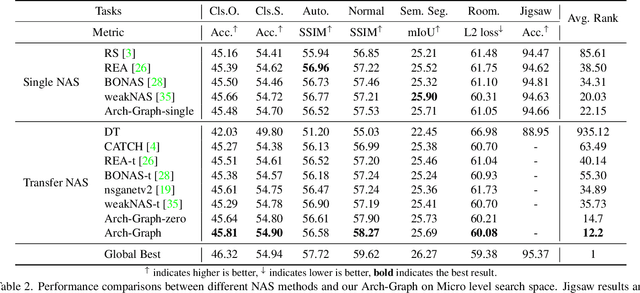
Neural Architecture Search (NAS) aims to find efficient models for multiple tasks. Beyond seeking solutions for a single task, there are surging interests in transferring network design knowledge across multiple tasks. In this line of research, effectively modeling task correlations is vital yet highly neglected. Therefore, we propose \textbf{Arch-Graph}, a transferable NAS method that predicts task-specific optimal architectures with respect to given task embeddings. It leverages correlations across multiple tasks by using their embeddings as a part of the predictor's input for fast adaptation. We also formulate NAS as an architecture relation graph prediction problem, with the relational graph constructed by treating candidate architectures as nodes and their pairwise relations as edges. To enforce some basic properties such as acyclicity in the relational graph, we add additional constraints to the optimization process, converting NAS into the problem of finding a Maximal Weighted Acyclic Subgraph (MWAS). Our algorithm then strives to eliminate cycles and only establish edges in the graph if the rank results can be trusted. Through MWAS, Arch-Graph can effectively rank candidate models for each task with only a small budget to finetune the predictor. With extensive experiments on TransNAS-Bench-101, we show Arch-Graph's transferability and high sample efficiency across numerous tasks, beating many NAS methods designed for both single-task and multi-task search. It is able to find top 0.16\% and 0.29\% architectures on average on two search spaces under the budget of only 50 models.
Beyond Fixation: Dynamic Window Visual Transformer
Apr 08, 2022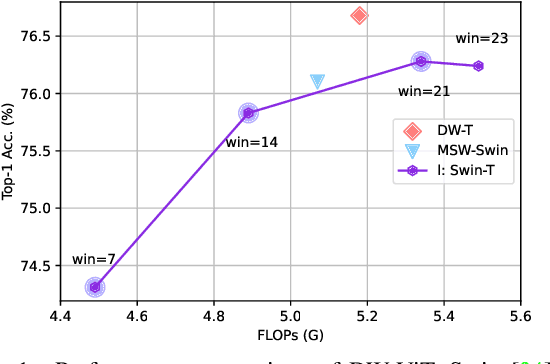
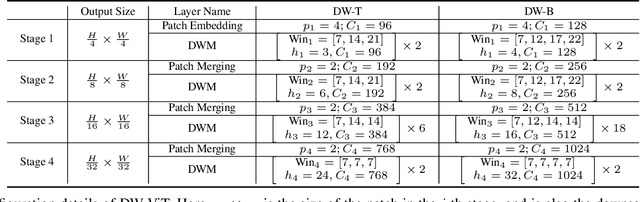
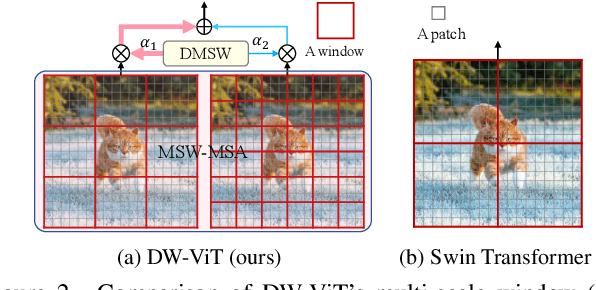
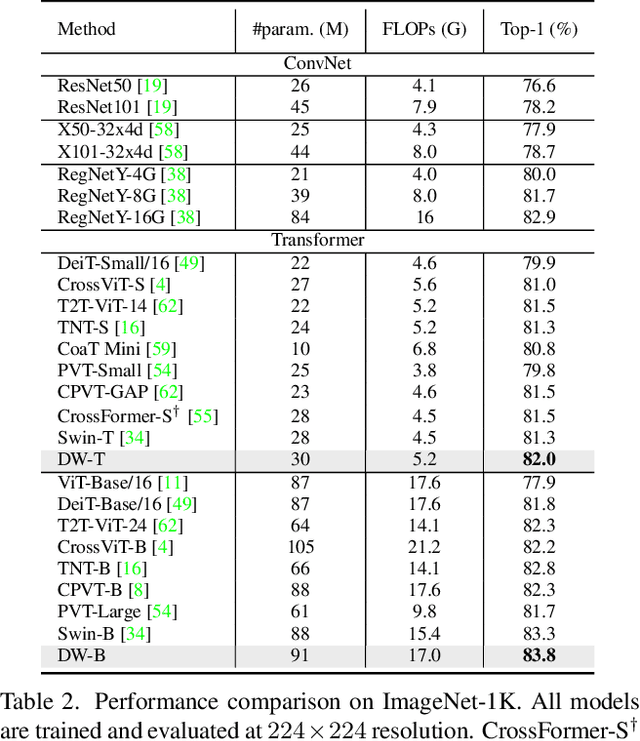
Recently, a surge of interest in visual transformers is to reduce the computational cost by limiting the calculation of self-attention to a local window. Most current work uses a fixed single-scale window for modeling by default, ignoring the impact of window size on model performance. However, this may limit the modeling potential of these window-based models for multi-scale information. In this paper, we propose a novel method, named Dynamic Window Vision Transformer (DW-ViT). The dynamic window strategy proposed by DW-ViT goes beyond the model that employs a fixed single window setting. To the best of our knowledge, we are the first to use dynamic multi-scale windows to explore the upper limit of the effect of window settings on model performance. In DW-ViT, multi-scale information is obtained by assigning windows of different sizes to different head groups of window multi-head self-attention. Then, the information is dynamically fused by assigning different weights to the multi-scale window branches. We conducted a detailed performance evaluation on three datasets, ImageNet-1K, ADE20K, and COCO. Compared with related state-of-the-art (SoTA) methods, DW-ViT obtains the best performance. Specifically, compared with the current SoTA Swin Transformers \cite{liu2021swin}, DW-ViT has achieved consistent and substantial improvements on all three datasets with similar parameters and computational costs. In addition, DW-ViT exhibits good scalability and can be easily inserted into any window-based visual transformers.