 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffLoc: Lightweight Vision Transformer for Efficient 6-DOF Camera Relocalization
Feb 21, 2024



Camera relocalization is pivotal in computer vision, with applications in AR, drones, robotics, and autonomous driving. It estimates 3D camera position and orientation (6-DoF) from images. Unlike traditional methods like SLAM, recent strides use deep learning for direct end-to-end pose estimation. We propose EffLoc, a novel efficient Vision Transformer for single-image camera relocalization. EffLoc's hierarchical layout, memory-bound self-attention, and feed-forward layers boost memory efficiency and inter-channel communication. Our introduced sequential group attention (SGA) module enhances computational efficiency by diversifying input features, reducing redundancy, and expanding model capacity. EffLoc excels in efficiency and accuracy, outperforming prior methods, such as AtLoc and MapNet. It thrives on large-scale outdoor car-driving scenario, ensuring simplicity, end-to-end trainability, and eliminating handcrafted loss functions.
DK-SLAM: Monocular Visual SLAM with Deep Keypoints Adaptive Learning, Tracking and Loop-Closing
Jan 17, 2024



Unreliable feature extraction and matching in handcrafted features undermine the performance of visual SLAM in complex real-world scenarios. While learned local features, leveraging CNNs, demonstrate proficiency in capturing high-level information and excel in matching benchmarks, they encounter challenges in continuous motion scenes, resulting in poor generalization and impacting loop detection accuracy. To address these issues, we present DK-SLAM, a monocular visual SLAM system with adaptive deep local features. MAML optimizes the training of these features, and we introduce a coarse-to-fine feature tracking approach. Initially, a direct method approximates the relative pose between consecutive frames, followed by a feature matching method for refined pose estimation. To counter cumulative positioning errors, a novel online learning binary feature-based online loop closure module identifies loop nodes within a sequence. Experimental results underscore DK-SLAM's efficacy, outperforms representative SLAM solutions, such as ORB-SLAM3 on publicly available datasets.
ReLoc-PDR: Visual Relocalization Enhanced Pedestrian Dead Reckoning via Graph Optimization
Sep 04, 2023Accurately and reliably positioning pedestrians in satellite-denied conditions remains a significant challenge. Pedestrian dead reckoning (PDR) is commonly employed to estimate pedestrian location using low-cost inertial sensor. However, PDR is susceptible to drift due to sensor noise, incorrect step detection, and inaccurate stride length estimation. This work proposes ReLoc-PDR, a fusion framework combining PDR and visual relocalization using graph optimization. ReLoc-PDR leverages time-correlated visual observations and learned descriptors to achieve robust positioning in visually-degraded environments. A graph optimization-based fusion mechanism with the Tukey kernel effectively corrects cumulative errors and mitigates the impact of abnormal visual observations. Real-world experiments demonstrate that our ReLoc-PDR surpasses representative methods in accuracy and robustness, achieving accurte and robust pedestrian positioning results using only a smartphone in challenging environments such as less-textured corridors and dark nighttime scenarios.
Drone-NeRF: Efficient NeRF Based 3D Scene Reconstruction for Large-Scale Drone Survey
Aug 30, 2023Neural rendering has garnered substantial attention owing to its capacity for creating realistic 3D scenes. However, its applicability to extensive scenes remains challenging, with limitations in effectiveness. In this work, we propose the Drone-NeRF framework to enhance the efficient reconstruction of unbounded large-scale scenes suited for drone oblique photography using Neural Radiance Fields (NeRF). Our approach involves dividing the scene into uniform sub-blocks based on camera position and depth visibility. Sub-scenes are trained in parallel using NeRF, then merged for a complete scene. We refine the model by optimizing camera poses and guiding NeRF with a uniform sampler. Integrating chosen samples enhances accuracy. A hash-coded fusion MLP accelerates density representation, yielding RGB and Depth outputs. Our framework accounts for sub-scene constraints, reduces parallel-training noise, handles shadow occlusion, and merges sub-regions for a polished rendering result. This Drone-NeRF framework demonstrates promising capabilities in addressing challenges related to scene complexity, rendering efficiency, and accuracy in drone-obtained imagery.
Deep Learning for Visual Localization and Mapping: A Survey
Aug 27, 2023



Deep learning based localization and mapping approaches have recently emerged as a new research direction and receive significant attentions from both industry and academia. Instead of creating hand-designed algorithms based on physical models or geometric theories, deep learning solutions provide an alternative to solve the problem in a data-driven way. Benefiting from the ever-increasing volumes of data and computational power on devices, these learning methods are fast evolving into a new area that shows potentials to track self-motion and estimate environmental model accurately and robustly for mobile agents. In this work, we provide a comprehensive survey, and propose a taxonomy for the localization and mapping methods using deep learning. This survey aims to discuss two basic questions: whether deep learning is promising to localization and mapping; how deep learning should be applied to solve this problem. To this end, a series of localization and mapping topics are investigated, from the learning based visual odometry, global relocalization, to mapping, and simultaneous localization and mapping (SLAM). It is our hope that this survey organically weaves together the recent works in this vein from robotics, computer vision and machine learning communities, and serves as a guideline for future researchers to apply deep learning to tackle the problem of visual localization and mapping.
Deep Learning for Inertial Positioning: A Survey
Mar 20, 2023Inertial sensors are widely utilized in smartphones, drones, robots, and IoT devices, playing a crucial role in enabling ubiquitous and reliable localization. Inertial sensor-based positioning is essential in various applications, including personal navigation, location-based security, and human-device interaction. However, low-cost MEMS inertial sensors' measurements are inevitably corrupted by various error sources, leading to unbounded drifts when integrated doubly in traditional inertial navigation algorithms, subjecting inertial positioning to the problem of error drifts. In recent years, with the rapid increase in sensor data and computational power, deep learning techniques have been developed, sparking significant research into addressing the problem of inertial positioning. Relevant literature in this field spans across mobile computing, robotics, and machine learning. In this article, we provide a comprehensive review of deep learning-based inertial positioning and its applications in tracking pedestrians, drones, vehicles, and robots. We connect efforts from different fields and discuss how deep learning can be applied to address issues such as sensor calibration, positioning error drift reduction, and multi-sensor fusion. This article aims to attract readers from various backgrounds, including researchers and practitioners interested in the potential of deep learning-based techniques to solve inertial positioning problems. Our review demonstrates the exciting possibilities that deep learning brings to the table and provides a roadmap for future research in this field.
Self-supervised Egomotion and Depth Learning via Bi-directional Coarse-to-Fine Scale Recovery
Nov 16, 2022



Self-supervised learning of egomotion and depth has recently attracted great attentions. These learning models can provide pose and depth maps to support navigation and perception task for autonomous driving and robots, while they do not require high-precision ground-truth labels to train the networks. However, monocular vision based methods suffer from pose scale-ambiguity problem, so that can not generate physical meaningful trajectory, and thus their applications are limited in real-world. We propose a novel self-learning deep neural network framework that can learn to estimate egomotion and depths with absolute metric scale from monocular images. Coarse depth scale is recovered via comparing point cloud data against a pretrained model that ensures the consistency of photometric loss. The scale-ambiguity problem is solved by introducing a novel two-stages coarse-to-fine scale recovery strategy that jointly refines coarse poses and depths. Our model successfully produces pose and depth estimates in global scale-metric, even in low-light condition, i.e. driving at night. The evaluation on the public datasets demonstrates that our model outperforms both representative traditional and learning based VOs and VIOs, e.g. VINS-mono, ORB-SLAM, SC-Learner, and UnVIO.
DevNet: Self-supervised Monocular Depth Learning via Density Volume Construction
Sep 20, 2022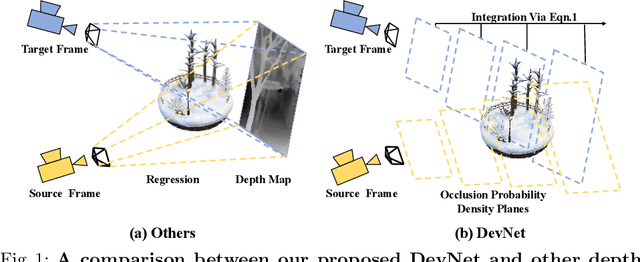
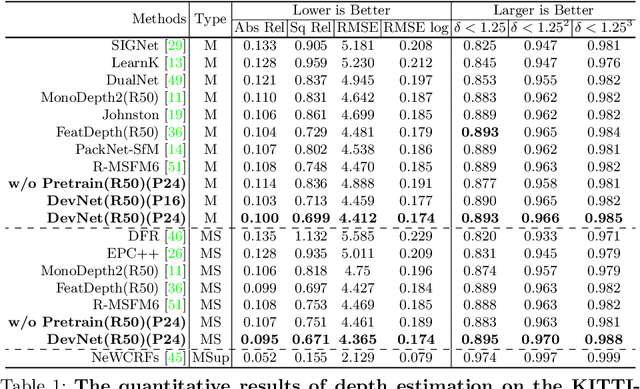
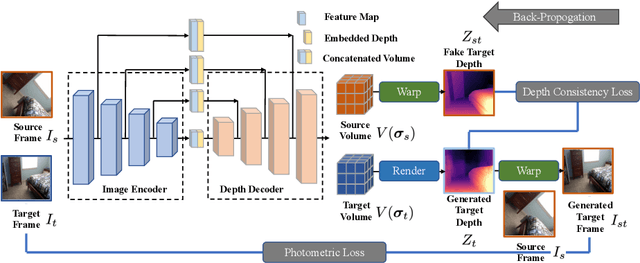

Self-supervised depth learning from monocular images normally relies on the 2D pixel-wise photometric relation between temporally adjacent image frames. However, they neither fully exploit the 3D point-wise geometric correspondences, nor effectively tackle the ambiguities in the photometric warping caused by occlusions or illumination inconsistency. To address these problems, this work proposes Density Volume Construction Network (DevNet), a novel self-supervised monocular depth learning framework, that can consider 3D spatial information, and exploit stronger geometric constraints among adjacent camera frustums. Instead of directly regressing the pixel value from a single image, our DevNet divides the camera frustum into multiple parallel planes and predicts the pointwise occlusion probability density on each plane. The final depth map is generated by integrating the density along corresponding rays. During the training process, novel regularization strategies and loss functions are introduced to mitigate photometric ambiguities and overfitting. Without obviously enlarging model parameters size or running time, DevNet outperforms several representative baselines on both the KITTI-2015 outdoor dataset and NYU-V2 indoor dataset. In particular, the root-mean-square-deviation is reduced by around 4% with DevNet on both KITTI-2015 and NYU-V2 in the task of depth estimation. Code is available at https://github.com/gitkaichenzhou/DevNet.
EMA-VIO: Deep Visual-Inertial Odometry with External Memory Attention
Sep 18, 2022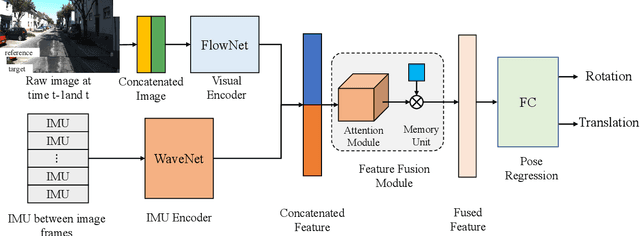
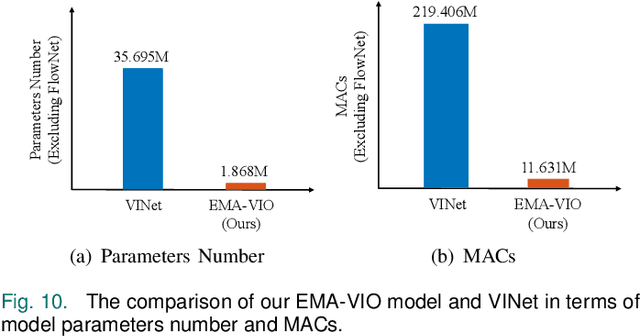
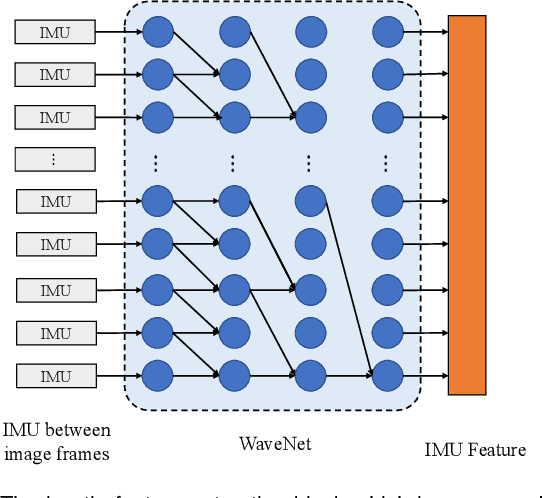
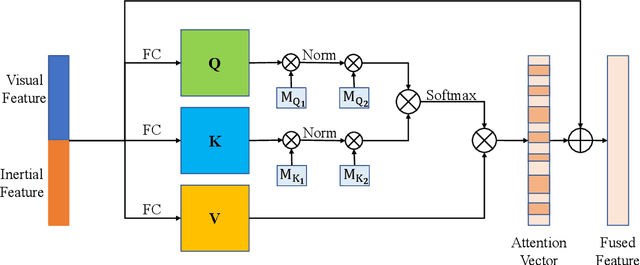
Accurate and robust localization is a fundamental need for mobile agents. Visual-inertial odometry (VIO) algorithms exploit the information from camera and inertial sensors to estimate position and translation. Recent deep learning based VIO models attract attentions as they provide pose information in a data-driven way, without the need of designing hand-crafted algorithms. Existing learning based VIO models rely on recurrent models to fuse multimodal data and process sensor signal, which are hard to train and not efficient enough. We propose a novel learning based VIO framework with external memory attention that effectively and efficiently combines visual and inertial features for states estimation. Our proposed model is able to estimate pose accurately and robustly, even in challenging scenarios, e.g., on overcast days and water-filled ground , which are difficult for traditional VIO algorithms to extract visual features. Experiments validate that it outperforms both traditional and learning based VIO baselines in different scenes.
P2-Net: Joint Description and Detection of Local Features for Pixel and Point Matching
Mar 01, 2021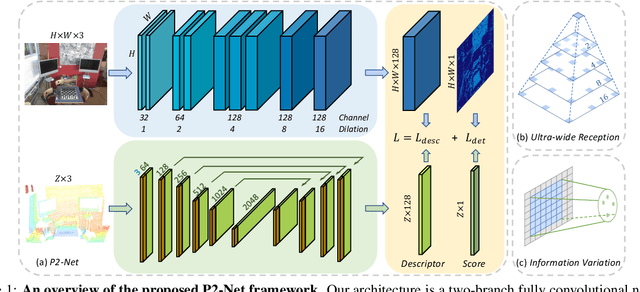
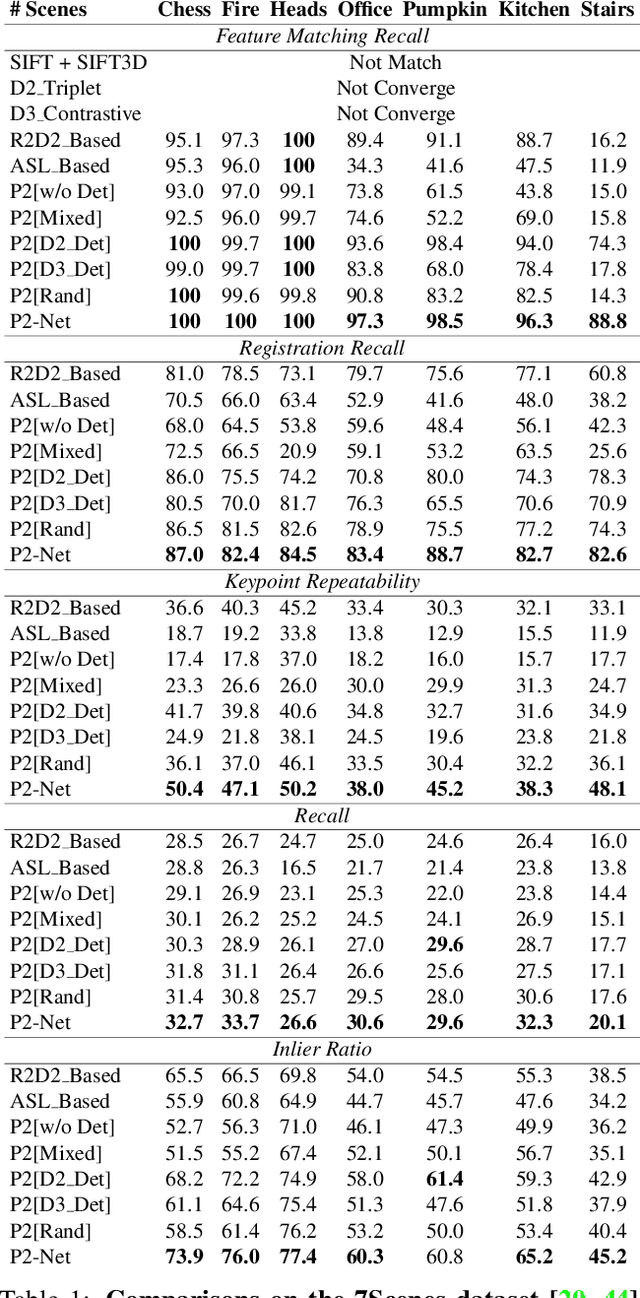
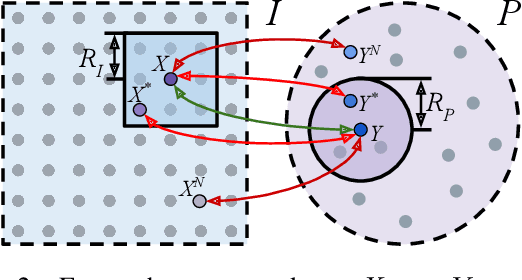
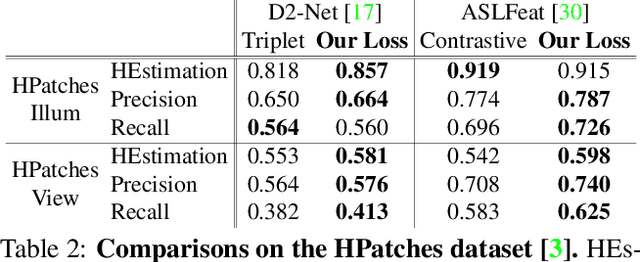
Accurately describing and detecting 2D and 3D keypoints is crucial to establishing correspondences across images and point clouds. Despite a plethora of learning-based 2D or 3D local feature descriptors and detectors having been proposed, the derivation of a shared descriptor and joint keypoint detector that directly matches pixels and points remains under-explored by the community. This work takes the initiative to establish fine-grained correspondences between 2D images and 3D point clouds. In order to directly match pixels and points, a dual fully convolutional framework is presented that maps 2D and 3D inputs into a shared latent representation space to simultaneously describe and detect keypoints. Furthermore, an ultra-wide reception mechanism in combination with a novel loss function are designed to mitigate the intrinsic information variations between pixel and point local regions. Extensive experimental results demonstrate that our framework shows competitive performance in fine-grained matching between images and point clouds and achieves state-of-the-art results for the task of indoor visual localization. Our source code will be available at [no-name-for-blind-review].