 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing COVID-19 Diagnosis with Privacy-Preserving Collaboration in Artificial Intelligence
Nov 18, 2021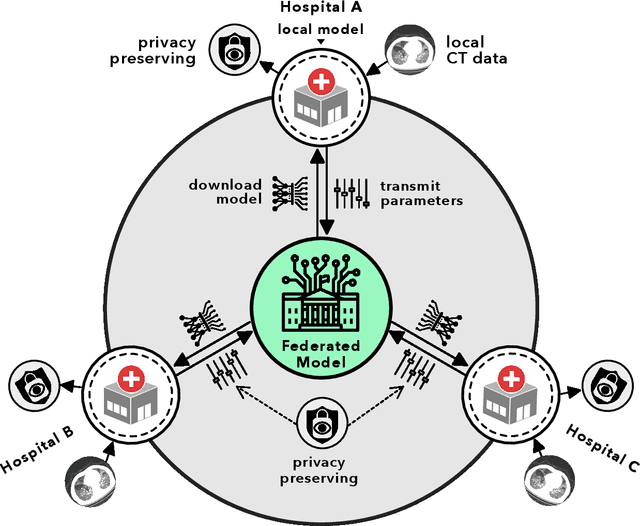
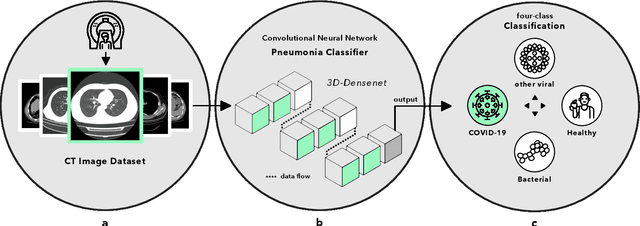
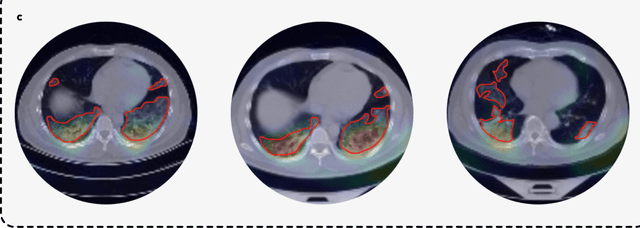
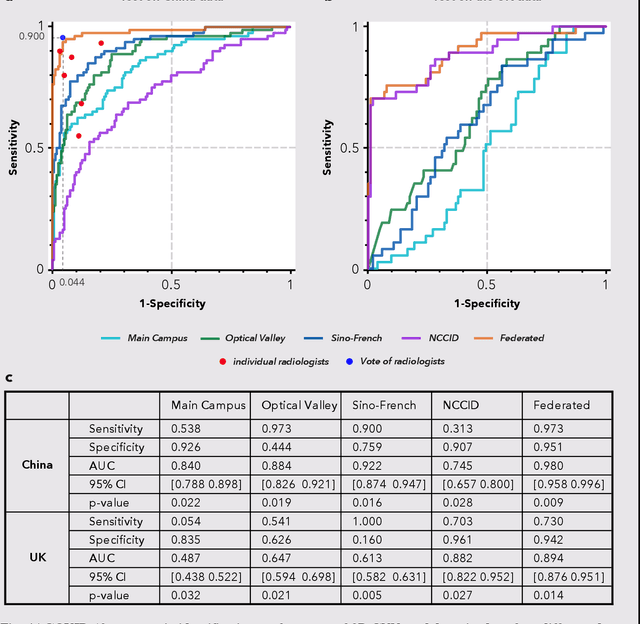
Artificial intelligence (AI) provides a promising substitution for streamlining COVID-19 diagnoses. However, concerns surrounding security and trustworthiness impede the collection of large-scale representative medical data, posing a considerable challenge for training a well-generalised model in clinical practices. To address this, we launch the Unified CT-COVID AI Diagnostic Initiative (UCADI), where the AI model can be distributedly trained and independently executed at each host institution under a federated learning framework (FL) without data sharing. Here we show that our FL model outperformed all the local models by a large yield (test sensitivity /specificity in China: 0.973/0.951, in the UK: 0.730/0.942), achieving comparable performance with a panel of professional radiologists. We further evaluated the model on the hold-out (collected from another two hospitals leaving out the FL) and heterogeneous (acquired with contrast materials) data, provided visual explanations for decisions made by the model, and analysed the trade-offs between the model performance and the communication costs in the federated training process. Our study is based on 9,573 chest computed tomography scans (CTs) from 3,336 patients collected from 23 hospitals located in China and the UK. Collectively, our work advanced the prospects of utilising federated learning for privacy-preserving AI in digital health.
Logic-Consistency Text Generation from Semantic Parses
Aug 02, 2021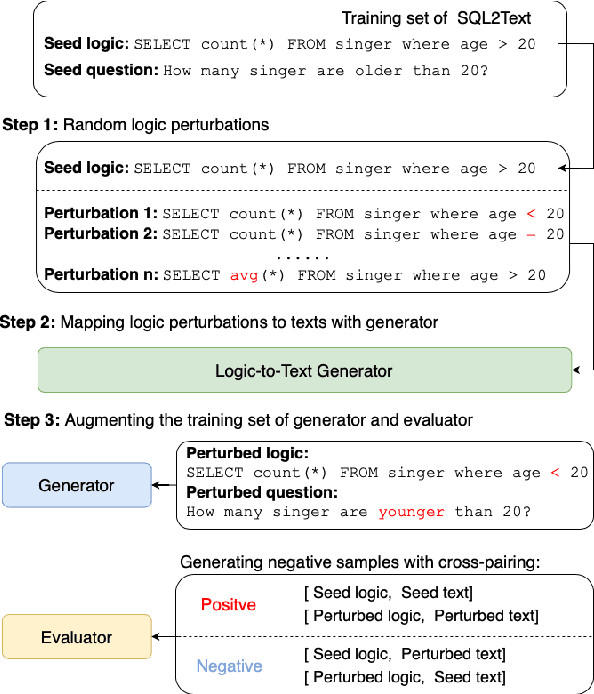

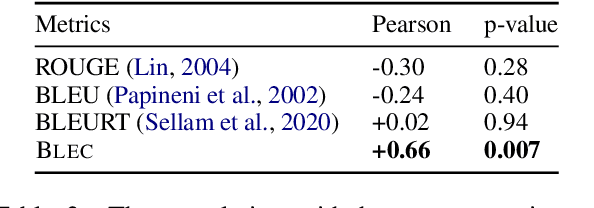
Text generation from semantic parses is to generate textual descriptions for formal representation inputs such as logic forms and SQL queries. This is challenging due to two reasons: (1) the complex and intensive inner logic with the data scarcity constraint, (2) the lack of automatic evaluation metrics for logic consistency. To address these two challenges, this paper first proposes SNOWBALL, a framework for logic consistent text generation from semantic parses that employs an iterative training procedure by recursively augmenting the training set with quality control. Second, we propose a novel automatic metric, BLEC, for evaluating the logical consistency between the semantic parses and generated texts. The experimental results on two benchmark datasets, Logic2Text and Spider, demonstrate the SNOWBALL framework enhances the logic consistency on both BLEC and human evaluation. Furthermore, our statistical analysis reveals that BLEC is more logically consistent with human evaluation than general-purpose automatic metrics including BLEU, ROUGE and, BLEURT. Our data and code are available at https://github.com/Ciaranshu/relogic.
Feature-metric Loss for Self-supervised Learning of Depth and Egomotion
Jul 21, 2020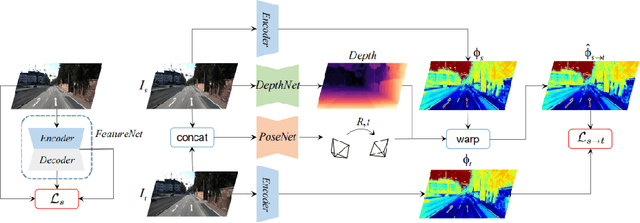


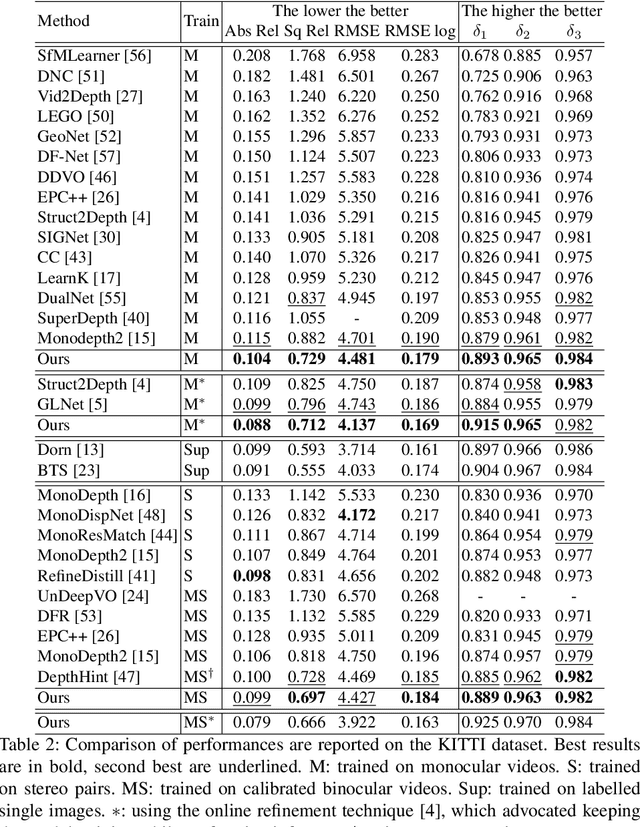
Photometric loss is widely used for self-supervised depth and egomotion estimation. However, the loss landscapes induced by photometric differences are often problematic for optimization, caused by plateau landscapes for pixels in textureless regions or multiple local minima for less discriminative pixels. In this work, feature-metric loss is proposed and defined on feature representation, where the feature representation is also learned in a self-supervised manner and regularized by both first-order and second-order derivatives to constrain the loss landscapes to form proper convergence basins. Comprehensive experiments and detailed analysis via visualization demonstrate the effectiveness of the proposed feature-metric loss. In particular, our method improves state-of-the-art methods on KITTI from 0.885 to 0.925 measured by $\delta_1$ for depth estimation, and significantly outperforms previous method for visual odometry.
Non-iterative Simultaneous Rigid Registration Method for Serial Sections of Biological Tissue
May 11, 2020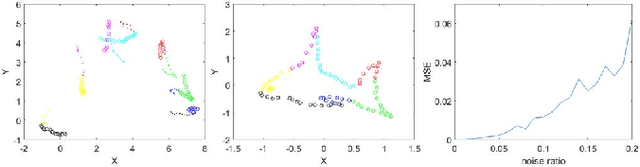
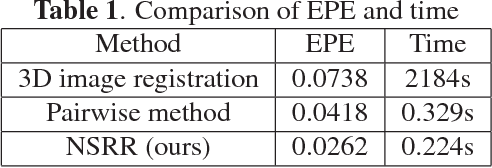
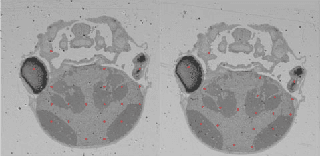
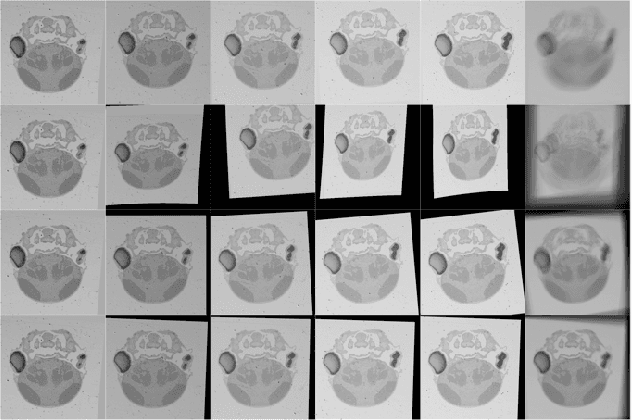
In this paper, we propose a novel non-iterative algorithm to simultaneously estimate optimal rigid transformation for serial section images, which is a key component in volume reconstruction of serial sections of biological tissue. In order to avoid error accumulation and propagation caused by current algorithms, we add extra condition that the position of the first and the last section images should remain unchanged. This constrained simultaneous registration problem has not been solved before. Our algorithm method is non-iterative, it can simultaneously compute rigid transformation for a large number of serial section images in a short time. We prove that our algorithm gets optimal solution under ideal condition. And we test our algorithm with synthetic data and real data to verify our algorithm's effectiveness.
* appears in IEEE International Symposium on Biomedical Imaging 2018 (ISBI 2018)
How Furiously Can Colourless Green Ideas Sleep? Sentence Acceptability in Context
Apr 02, 2020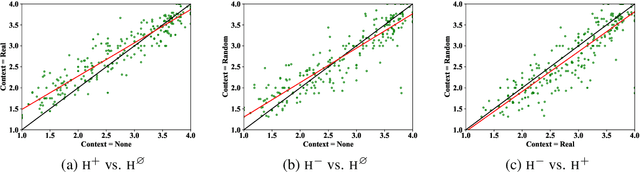

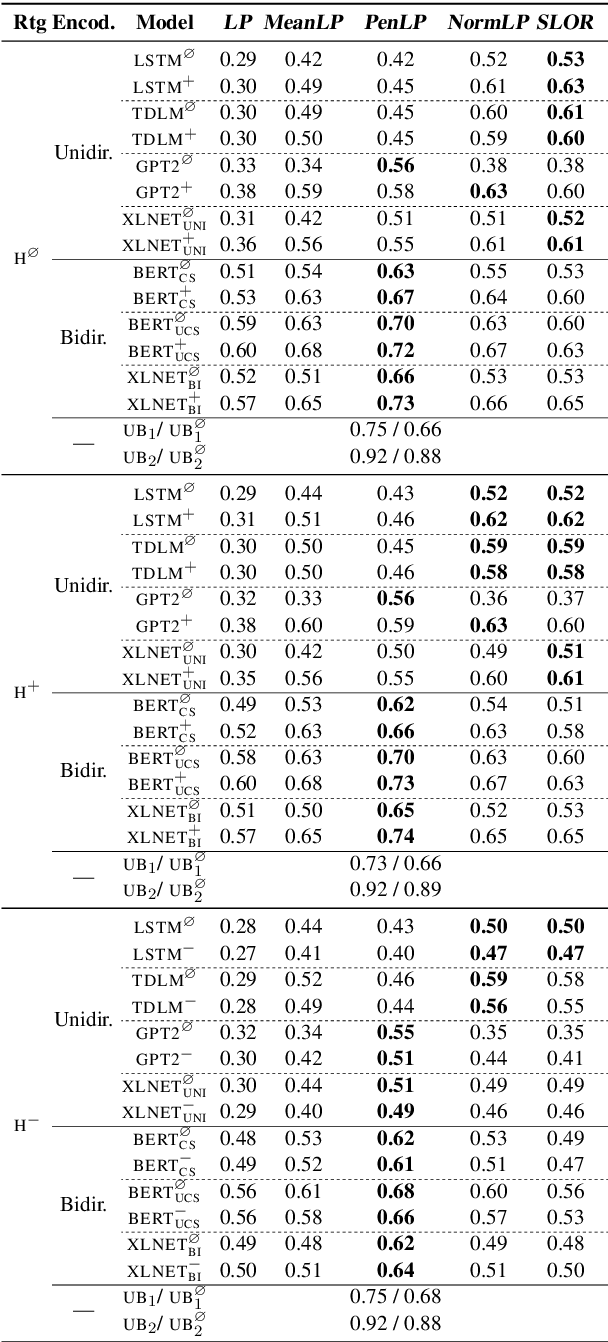
We study the influence of context on sentence acceptability. First we compare the acceptability ratings of sentences judged in isolation, with a relevant context, and with an irrelevant context. Our results show that context induces a cognitive load for humans, which compresses the distribution of ratings. Moreover, in relevant contexts we observe a discourse coherence effect which uniformly raises acceptability. Next, we test unidirectional and bidirectional language models in their ability to predict acceptability ratings. The bidirectional models show very promising results, with the best model achieving a new state-of-the-art for unsupervised acceptability prediction. The two sets of experiments provide insights into the cognitive aspects of sentence processing and central issues in the computational modelling of text and discourse.
Abnormality Detection in Mammography using Deep Convolutional Neural Networks
Mar 05, 2018



Breast cancer is the most common cancer in women worldwide. The most common screening technology is mammography. To reduce the cost and workload of radiologists, we propose a computer aided detection approach for classifying and localizing calcifications and masses in mammogram images. To improve on conventional approaches, we apply deep convolutional neural networks (CNN) for automatic feature learning and classifier building. In computer-aided mammography, deep CNN classifiers cannot be trained directly on full mammogram images because of the loss of image details from resizing at input layers. Instead, our classifiers are trained on labelled image patches and then adapted to work on full mammogram images for localizing the abnormalities. State-of-the-art deep convolutional neural networks are compared on their performance of classifying the abnormalities. Experimental results indicate that VGGNet receives the best overall accuracy at 92.53\% in classifications. For localizing abnormalities, ResNet is selected for computing class activation maps because it is ready to be deployed without structural change or further training. Our approach demonstrates that deep convolutional neural network classifiers have remarkable localization capabilities despite no supervision on the location of abnormalities is provided.
Hierarchical Spatial Transformer Network
Jan 30, 2018
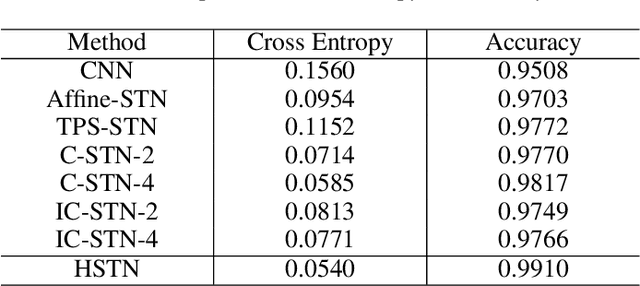

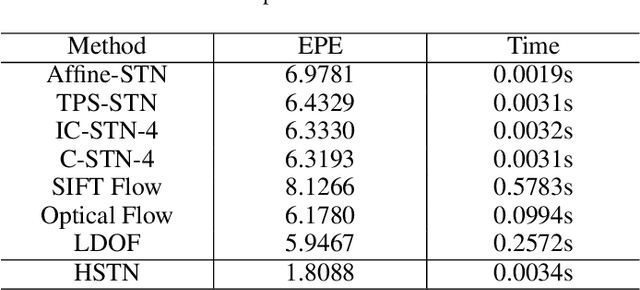
Computer vision researchers have been expecting that neural networks have spatial transformation ability to eliminate the interference caused by geometric distortion for a long time. Emergence of spatial transformer network makes dream come true. Spatial transformer network and its variants can handle global displacement well, but lack the ability to deal with local spatial variance. Hence how to achieve a better manner of deformation in the neural network has become a pressing matter of the moment. To address this issue, we analyze the advantages and disadvantages of approximation theory and optical flow theory, then we combine them to propose a novel way to achieve image deformation and implement it with a hierarchical convolutional neural network. This new approach solves for a linear deformation along with an optical flow field to model image deformation. In the experiments of cluttered MNIST handwritten digits classification and image plane alignment, our method outperforms baseline methods by a large margin.
Finite Element Based Tracking of Deforming Surfaces
Oct 28, 2014
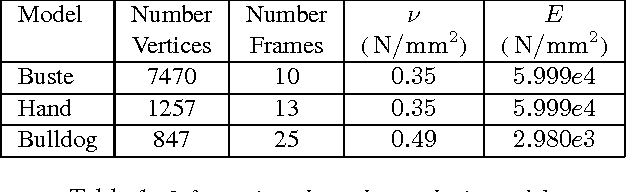
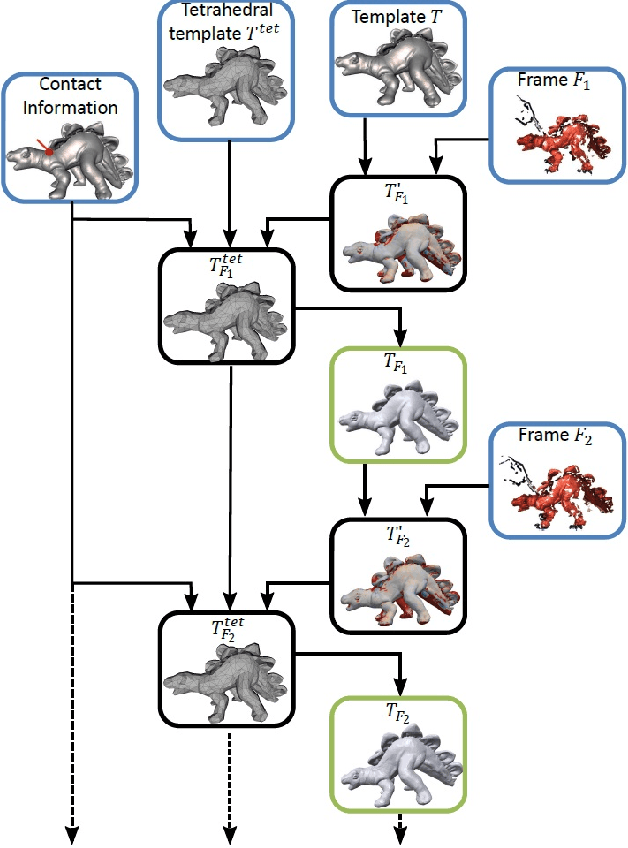

We present an approach to robustly track the geometry of an object that deforms over time from a set of input point clouds captured from a single viewpoint. The deformations we consider are caused by applying forces to known locations on the object's surface. Our method combines the use of prior information on the geometry of the object modeled by a smooth template and the use of a linear finite element method to predict the deformation. This allows the accurate reconstruction of both the observed and the unobserved sides of the object. We present tracking results for noisy low-quality point clouds acquired by either a stereo camera or a depth camera, and simulations with point clouds corrupted by different error terms. We show that our method is also applicable to large non-linear deformations.
* additional experiments
Estimation of Human Body Shape and Posture Under Clothing
Jun 26, 2014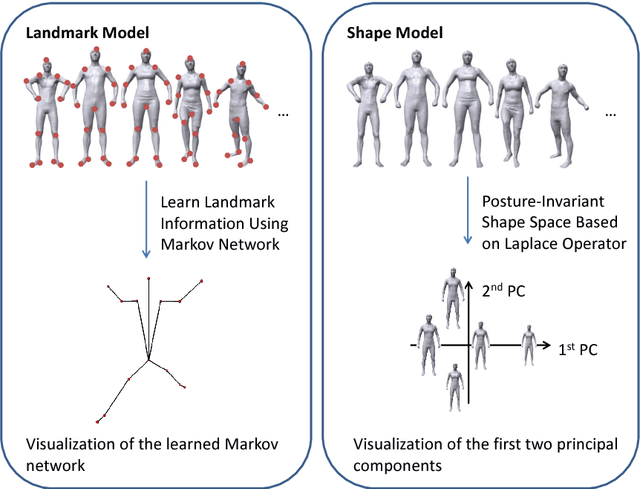
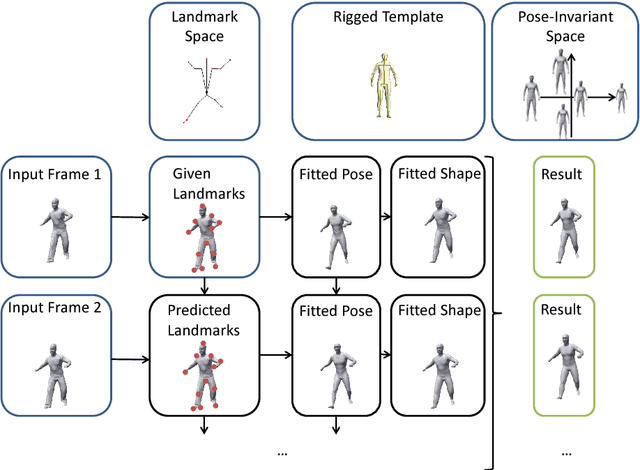
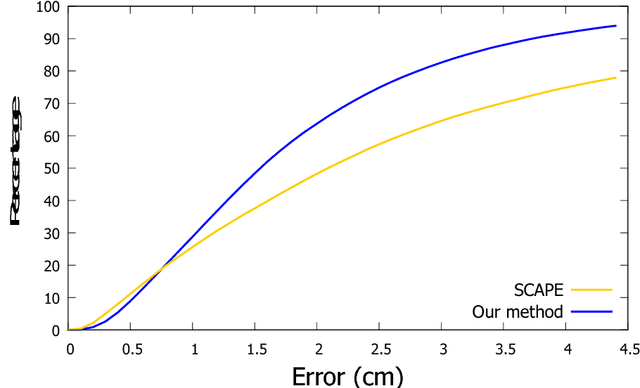

Estimating the body shape and posture of a dressed human subject in motion represented as a sequence of (possibly incomplete) 3D meshes is important for virtual change rooms and security. To solve this problem, statistical shape spaces encoding human body shape and posture variations are commonly used to constrain the search space for the shape estimate. In this work, we propose a novel method that uses a posture-invariant shape space to model body shape variation combined with a skeleton-based deformation to model posture variation. Our method can estimate the body shape and posture of both static scans and motion sequences of dressed human body scans. In case of motion sequences, our method takes advantage of motion cues to solve for a single body shape estimate along with a sequence of posture estimates. We apply our approach to both static scans and motion sequences and demonstrate that using our method, higher fitting accuracy is achieved than when using a variant of the popular SCAPE model as statistical model.
* 23 pages, 11 figures
Fully Automatic Expression-Invariant Face Correspondence
Jan 30, 2013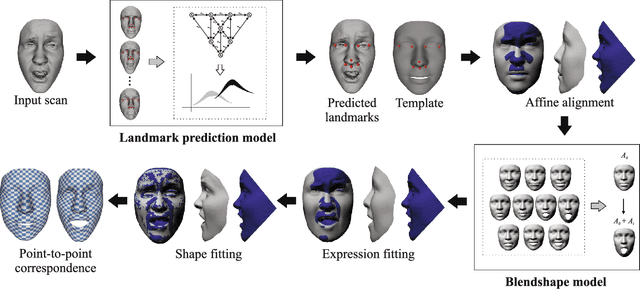
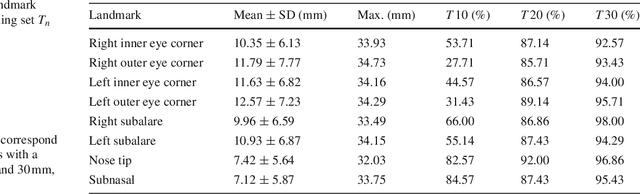
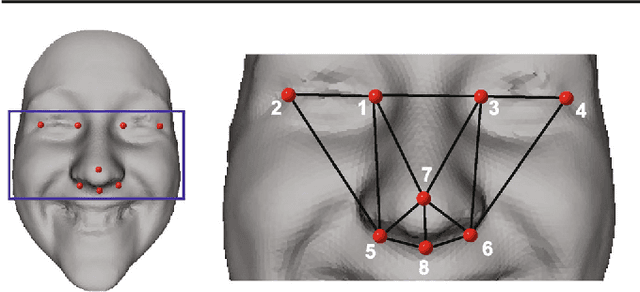
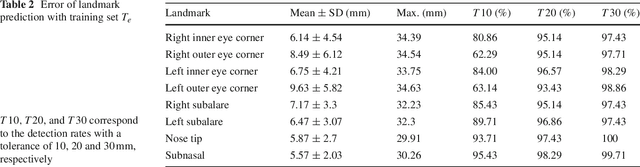
We consider the problem of computing accurate point-to-point correspondences among a set of human face scans with varying expressions. Our fully automatic approach does not require any manually placed markers on the scan. Instead, the approach learns the locations of a set of landmarks present in a database and uses this knowledge to automatically predict the locations of these landmarks on a newly available scan. The predicted landmarks are then used to compute point-to-point correspondences between a template model and the newly available scan. To accurately fit the expression of the template to the expression of the scan, we use as template a blendshape model. Our algorithm was tested on a database of human faces of different ethnic groups with strongly varying expressions. Experimental results show that the obtained point-to-point correspondence is both highly accurate and consistent for most of the tested 3D face models.