 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPC-VLA: A Vision-Language-Action Framework with a Supervisor for Failure Prediction and Correction
Sep 04, 2025



Robotic manipulation is a fundamental component of automation. However, traditional perception-planning pipelines often fall short in open-ended tasks due to limited flexibility, while the architecture of a single end-to-end Vision-Language-Action (VLA) offers promising capabilities but lacks crucial mechanisms for anticipating and recovering from failure. To address these challenges, we propose FPC-VLA, a dual-model framework that integrates VLA with a supervisor for failure prediction and correction. The supervisor evaluates action viability through vision-language queries and generates corrective strategies when risks arise, trained efficiently without manual labeling. A similarity-guided fusion module further refines actions by leveraging past predictions. Evaluation results on multiple simulation platforms (SIMPLER and LIBERO) and robot embodiments (WidowX, Google Robot, Franka) show that FPC-VLA outperforms state-of-the-art models in both zero-shot and fine-tuned settings. By activating the supervisor only at keyframes, our approach significantly increases task success rates with minimal impact on execution time. Successful real-world deployments on diverse, long-horizon tasks confirm FPC-VLA's strong generalization and practical utility for building more reliable autonomous systems.
Feature-metric Loss for Self-supervised Learning of Depth and Egomotion
Jul 21, 2020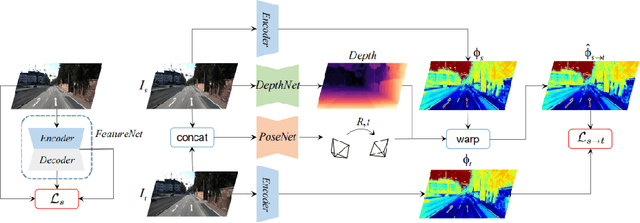


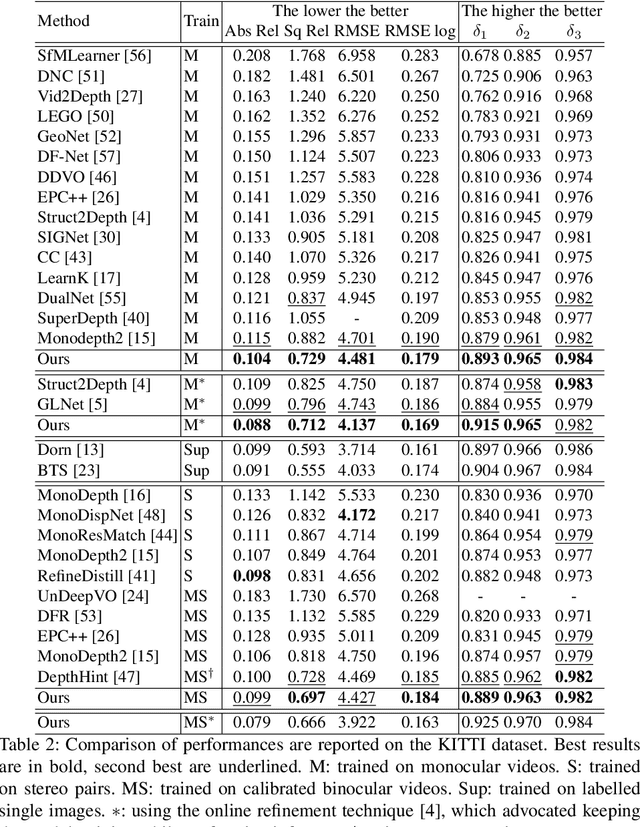
Photometric loss is widely used for self-supervised depth and egomotion estimation. However, the loss landscapes induced by photometric differences are often problematic for optimization, caused by plateau landscapes for pixels in textureless regions or multiple local minima for less discriminative pixels. In this work, feature-metric loss is proposed and defined on feature representation, where the feature representation is also learned in a self-supervised manner and regularized by both first-order and second-order derivatives to constrain the loss landscapes to form proper convergence basins. Comprehensive experiments and detailed analysis via visualization demonstrate the effectiveness of the proposed feature-metric loss. In particular, our method improves state-of-the-art methods on KITTI from 0.885 to 0.925 measured by $\delta_1$ for depth estimation, and significantly outperforms previous method for visual odometry.