 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironmental, Social and Governance Sentiment Analysis on Slovene News: A Novel Dataset and Models
Apr 08, 2026Environmental, Social, and Governance (ESG) considerations are increasingly integral to assessing corporate performance, reputation, and long-term sustainability. Yet, reliable ESG ratings remain limited for smaller companies and emerging markets. We introduce the first publicly available Slovene ESG sentiment dataset and a suite of models for automatic ESG sentiment detection. The dataset, derived from the MaCoCu Slovene news collection, combines large language model (LLM)-assisted filtering with human annotation of company-related ESG content. We evaluate the performance of monolingual (SloBERTa) and multilingual (XLM-R) models, embedding-based classifiers (TabPFN), hierarchical ensemble architectures, and large language models. Results show that LLMs achieve the strongest performance on Environmental (Gemma3-27B, F1-macro: 0.61) and Social aspects (gpt-oss 20B, F1-macro: 0.45), while fine-tuned SloBERTa is the best model on Governance classification (F1-macro: 0.54). We then show in a small case study how the best-preforming classifier (gpt-oss) can be applied to investigate ESG aspects for selected companies across a long time frame.
Multilingual Cognitive Impairment Detection in the Era of Foundation Models
Apr 08, 2026We evaluate cognitive impairment (CI) classification from transcripts of speech in English, Slovene, and Korean. We compare zero-shot large language models (LLMs) used as direct classifiers under three input settings -- transcript-only, linguistic-features-only, and combined -- with supervised tabular approaches trained under a leave-one-out protocol. The tabular models operate on engineered linguistic features, transcript embeddings, and early or late fusion of both modalities. Across languages, zero-shot LLMs provide competitive no-training baselines, but supervised tabular models generally perform better, particularly when engineered linguistic features are included and combined with embeddings. Few-shot experiments focusing on embeddings indicate that the value of limited supervision is language-dependent, with some languages benefiting substantially from additional labelled examples while others remain constrained without richer feature representations. Overall, the results suggest that, in small-data CI detection, structured linguistic signals and simple fusion-based classifiers remain strong and reliable signals.
Fine-Refine: Iterative Fine-grained Refinement for Mitigating Dialogue Hallucination
Feb 17, 2026The tendency for hallucination in current large language models (LLMs) negatively impacts dialogue systems. Such hallucinations produce factually incorrect responses that may mislead users and undermine system trust. Existing refinement methods for dialogue systems typically operate at the response level, overlooking the fact that a single response may contain multiple verifiable or unverifiable facts. To address this gap, we propose Fine-Refine, a fine-grained refinement framework that decomposes responses into atomic units, verifies each unit using external knowledge, assesses fluency via perplexity, and iteratively corrects granular errors. We evaluate factuality across the HybriDialogue and OpendialKG datasets in terms of factual accuracy (fact score) and coverage (Not Enough Information Proportion), and experiments show that Fine-Refine substantially improves factuality, achieving up to a 7.63-point gain in dialogue fact score, with a small trade-off in dialogue quality.
CG-TTRL: Context-Guided Test-Time Reinforcement Learning for On-Device Large Language Models
Nov 09, 2025Test-time Reinforcement Learning (TTRL) has shown promise in adapting foundation models for complex tasks at test-time, resulting in large performance improvements. TTRL leverages an elegant two-phase sampling strategy: first, multi-sampling derives a pseudo-label via majority voting, while subsequent downsampling and reward-based fine-tuning encourages the model to explore and learn diverse valid solutions, with the pseudo-label modulating the reward signal. Meanwhile, in-context learning has been widely explored at inference time and demonstrated the ability to enhance model performance without weight updates. However, TTRL's two-phase sampling strategy under-utilizes contextual guidance, which can potentially improve pseudo-label accuracy in the initial exploitation phase while regulating exploration in the second. To address this, we propose context-guided TTRL (CG-TTRL), integrating context dynamically into both sampling phases and propose a method for efficient context selection for on-device applications. Our evaluations on mathematical and scientific QA benchmarks show CG-TTRL outperforms TTRL (e.g. additional 7% relative accuracy improvement over TTRL), while boosting efficiency by obtaining strong performance after only a few steps of test-time training (e.g. 8% relative improvement rather than 1% over TTRL after 3 steps).
FairJudge: MLLM Judging for Social Attributes and Prompt Image Alignment
Oct 26, 2025Text-to-image (T2I) systems lack simple, reproducible ways to evaluate how well images match prompts and how models treat social attributes. Common proxies -- face classifiers and contrastive similarity -- reward surface cues, lack calibrated abstention, and miss attributes only weakly visible (for example, religion, culture, disability). We present FairJudge, a lightweight protocol that treats instruction-following multimodal LLMs as fair judges. It scores alignment with an explanation-oriented rubric mapped to [-1, 1]; constrains judgments to a closed label set; requires evidence grounded in the visible content; and mandates abstention when cues are insufficient. Unlike CLIP-only pipelines, FairJudge yields accountable, evidence-aware decisions; unlike mitigation that alters generators, it targets evaluation fairness. We evaluate gender, race, and age on FairFace, PaTA, and FairCoT; extend to religion, culture, and disability; and assess profession correctness and alignment on IdenProf, FairCoT-Professions, and our new DIVERSIFY-Professions. We also release DIVERSIFY, a 469-image corpus of diverse, non-iconic scenes. Across datasets, judge models outperform contrastive and face-centric baselines on demographic prediction and improve mean alignment while maintaining high profession accuracy, enabling more reliable, reproducible fairness audits.
A Computational Framework to Identify Self-Aspects in Text
Jul 17, 2025This Ph.D. proposal introduces a plan to develop a computational framework to identify Self-aspects in text. The Self is a multifaceted construct and it is reflected in language. While it is described across disciplines like cognitive science and phenomenology, it remains underexplored in natural language processing (NLP). Many of the aspects of the Self align with psychological and other well-researched phenomena (e.g., those related to mental health), highlighting the need for systematic NLP-based analysis. In line with this, we plan to introduce an ontology of Self-aspects and a gold-standard annotated dataset. Using this foundation, we will develop and evaluate conventional discriminative models, generative large language models, and embedding-based retrieval approaches against four main criteria: interpretability, ground-truth adherence, accuracy, and computational efficiency. Top-performing models will be applied in case studies in mental health and empirical phenomenology.
Improving Factuality for Dialogue Response Generation via Graph-Based Knowledge Augmentation
Jun 14, 2025



Large Language Models (LLMs) succeed in many natural language processing tasks. However, their tendency to hallucinate - generate plausible but inconsistent or factually incorrect text - can cause problems in certain tasks, including response generation in dialogue. To mitigate this issue, knowledge-augmented methods have shown promise in reducing hallucinations. Here, we introduce a novel framework designed to enhance the factuality of dialogue response generation, as well as an approach to evaluate dialogue factual accuracy. Our framework combines a knowledge triple retriever, a dialogue rewrite, and knowledge-enhanced response generation to produce more accurate and grounded dialogue responses. To further evaluate generated responses, we propose a revised fact score that addresses the limitations of existing fact-score methods in dialogue settings, providing a more reliable assessment of factual consistency. We evaluate our methods using different baselines on the OpendialKG and HybriDialogue datasets. Our methods significantly improve factuality compared to other graph knowledge-augmentation baselines, including the state-of-the-art G-retriever. The code will be released on GitHub.
Breaking Language Barriers or Reinforcing Bias? A Study of Gender and Racial Disparities in Multilingual Contrastive Vision Language Models
May 20, 2025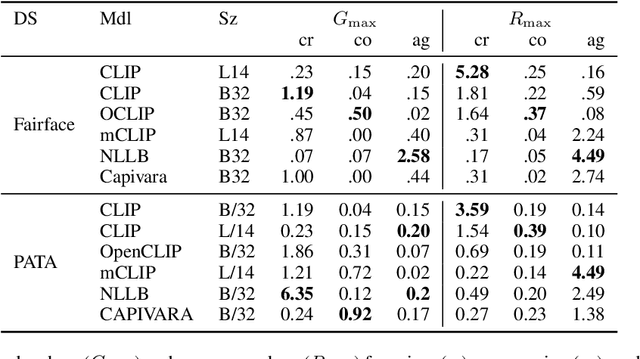
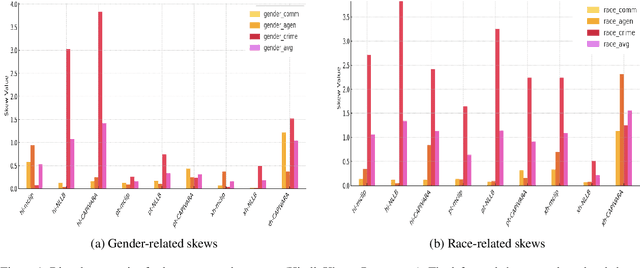
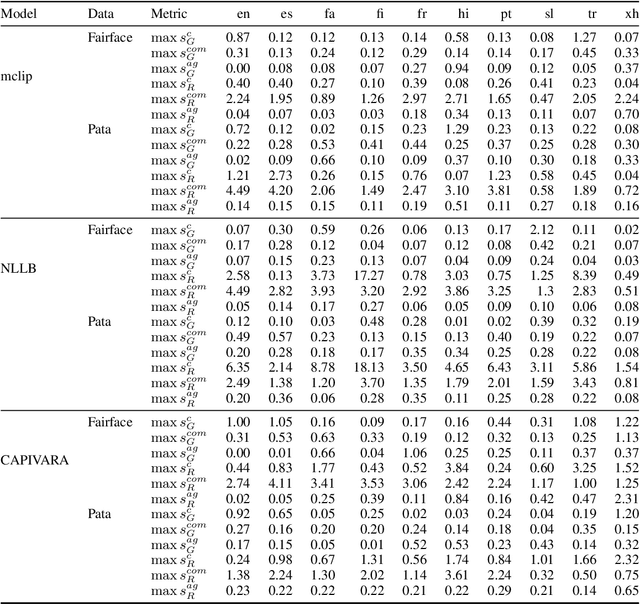
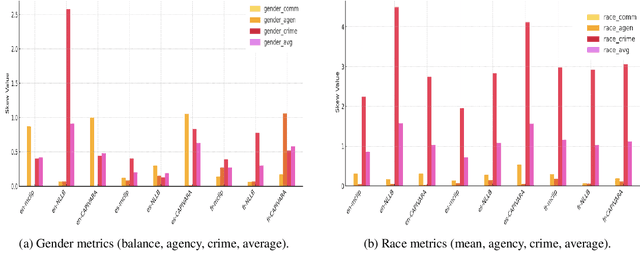
Multilingual vision-language models promise universal image-text retrieval, yet their social biases remain under-explored. We present the first systematic audit of three public multilingual CLIP checkpoints -- M-CLIP, NLLB-CLIP, and CAPIVARA-CLIP -- across ten languages that vary in resource availability and grammatical gender. Using balanced subsets of \textsc{FairFace} and the \textsc{PATA} stereotype suite in a zero-shot setting, we quantify race and gender bias and measure stereotype amplification. Contrary to the assumption that multilinguality mitigates bias, every model exhibits stronger gender bias than its English-only baseline. CAPIVARA-CLIP shows its largest biases precisely in the low-resource languages it targets, while the shared cross-lingual encoder of NLLB-CLIP transports English gender stereotypes into gender-neutral languages; loosely coupled encoders largely avoid this transfer. Highly gendered languages consistently magnify all measured bias types, but even gender-neutral languages remain vulnerable when cross-lingual weight sharing imports foreign stereotypes. Aggregated metrics conceal language-specific ``hot spots,'' underscoring the need for fine-grained, language-aware bias evaluation in future multilingual vision-language research.
Recent Trends in Linear Text Segmentation: a Survey
Nov 25, 2024



Linear Text Segmentation is the task of automatically tagging text documents with topic shifts, i.e. the places in the text where the topics change. A well-established area of research in Natural Language Processing, drawing from well-understood concepts in linguistic and computational linguistic research, the field has recently seen a lot of interest as a result of the surge of text, video, and audio available on the web, which in turn require ways of summarising and categorizing the mole of content for which linear text segmentation is a fundamental step. In this survey, we provide an extensive overview of current advances in linear text segmentation, describing the state of the art in terms of resources and approaches for the task. Finally, we highlight the limitations of available resources and of the task itself, while indicating ways forward based on the most recent literature and under-explored research directions.
Evaluating and explaining training strategies for zero-shot cross-lingual news sentiment analysis
Sep 30, 2024



We investigate zero-shot cross-lingual news sentiment detection, aiming to develop robust sentiment classifiers that can be deployed across multiple languages without target-language training data. We introduce novel evaluation datasets in several less-resourced languages, and experiment with a range of approaches including the use of machine translation; in-context learning with large language models; and various intermediate training regimes including a novel task objective, POA, that leverages paragraph-level information. Our results demonstrate significant improvements over the state of the art, with in-context learning generally giving the best performance, but with the novel POA approach giving a competitive alternative with much lower computational overhead. We also show that language similarity is not in itself sufficient for predicting the success of cross-lingual transfer, but that similarity in semantic content and structure can be equally important.