 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of contextual embeddings on less-resourced languages
Jul 22, 2021

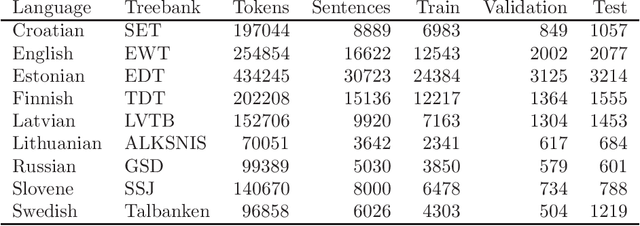
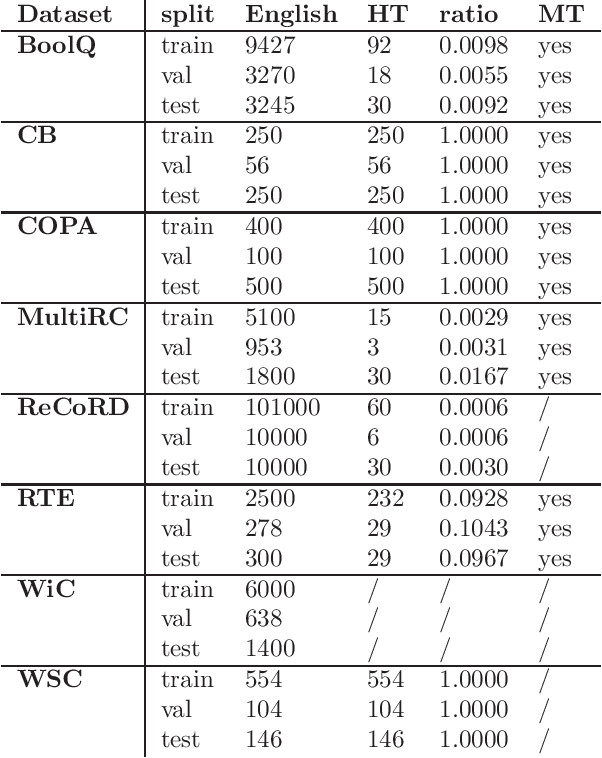
The current dominance of deep neural networks in natural language processing is based on contextual embeddings such as ELMo, BERT, and BERT derivatives. Most existing work focuses on English; in contrast, we present here the first multilingual empirical comparison of two ELMo and several monolingual and multilingual BERT models using 14 tasks in nine languages. In monolingual settings, our analysis shows that monolingual BERT models generally dominate, with a few exceptions such as the dependency parsing task, where they are not competitive with ELMo models trained on large corpora. In cross-lingual settings, BERT models trained on only a few languages mostly do best, closely followed by massively multilingual BERT models.
How Furiously Can Colourless Green Ideas Sleep? Sentence Acceptability in Context
Apr 02, 2020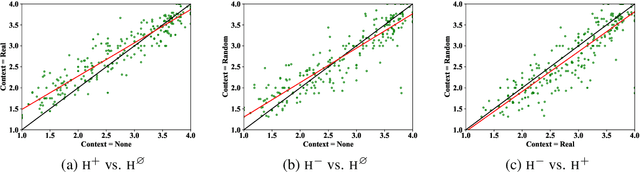
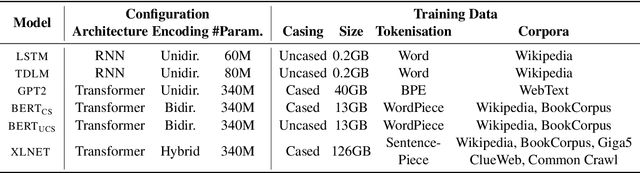

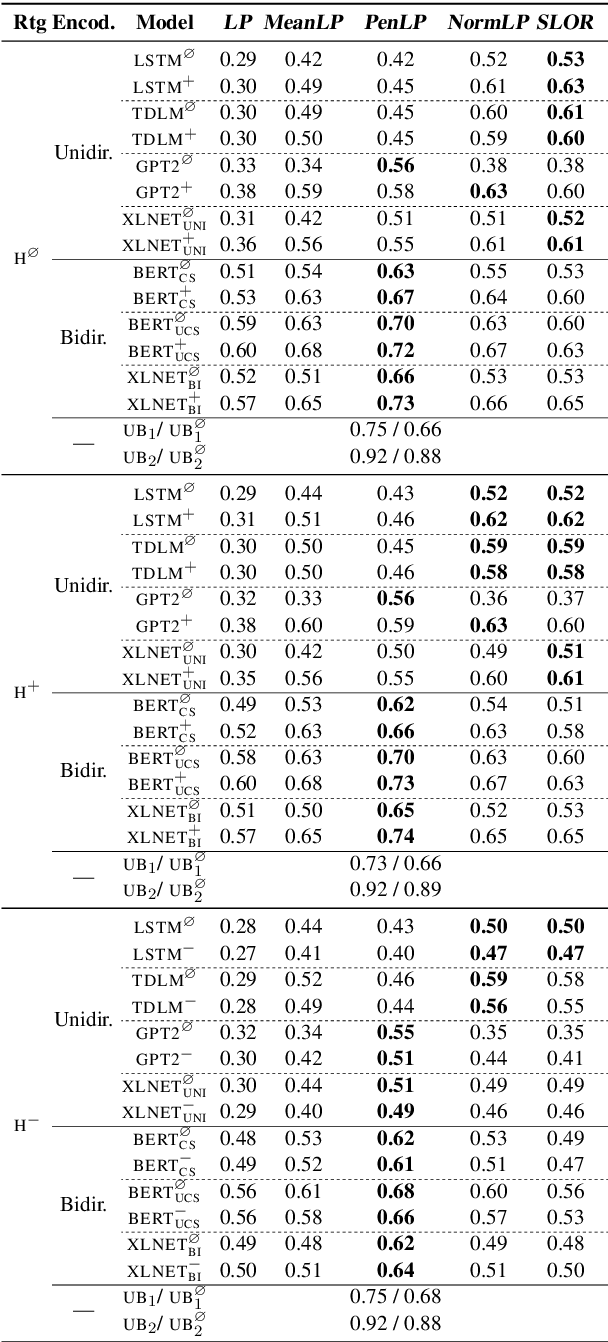
We study the influence of context on sentence acceptability. First we compare the acceptability ratings of sentences judged in isolation, with a relevant context, and with an irrelevant context. Our results show that context induces a cognitive load for humans, which compresses the distribution of ratings. Moreover, in relevant contexts we observe a discourse coherence effect which uniformly raises acceptability. Next, we test unidirectional and bidirectional language models in their ability to predict acceptability ratings. The bidirectional models show very promising results, with the best model achieving a new state-of-the-art for unsupervised acceptability prediction. The two sets of experiments provide insights into the cognitive aspects of sentence processing and central issues in the computational modelling of text and discourse.