 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenBox: A Generalized Black-box Optimization Service
Jun 06, 2021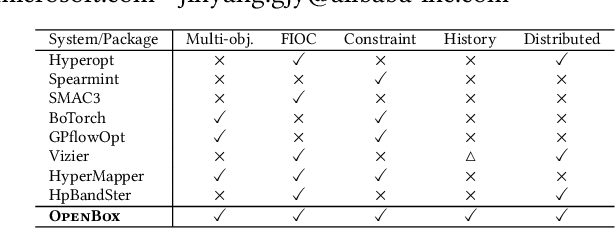
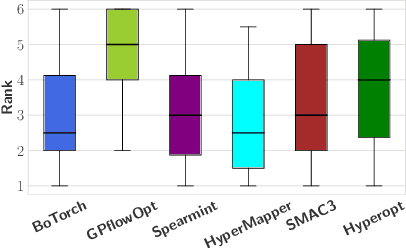
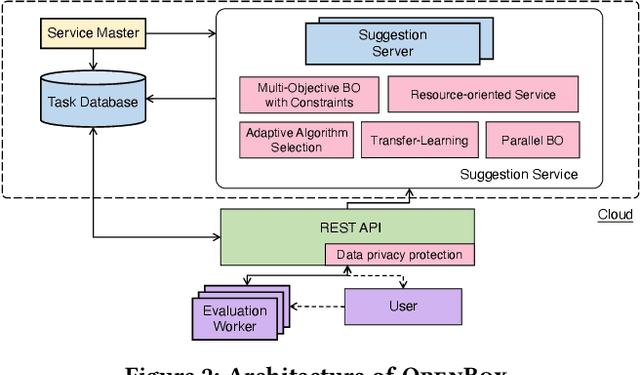

Black-box optimization (BBO) has a broad range of applications, including automatic machine learning, engineering, physics, and experimental design. However, it remains a challenge for users to apply BBO methods to their problems at hand with existing software packages, in terms of applicability, performance, and efficiency. In this paper, we build OpenBox, an open-source and general-purpose BBO service with improved usability. The modular design behind OpenBox also facilitates flexible abstraction and optimization of basic BBO components that are common in other existing systems. OpenBox is distributed, fault-tolerant, and scalable. To improve efficiency, OpenBox further utilizes "algorithm agnostic" parallelization and transfer learning. Our experimental results demonstrate the effectiveness and efficiency of OpenBox compared to existing systems.
Towards Demystifying Serverless Machine Learning Training
May 17, 2021
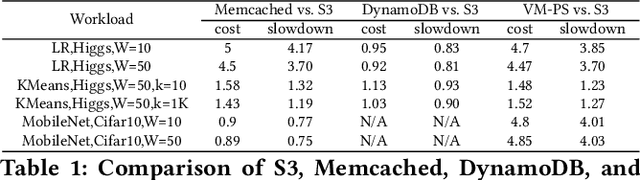

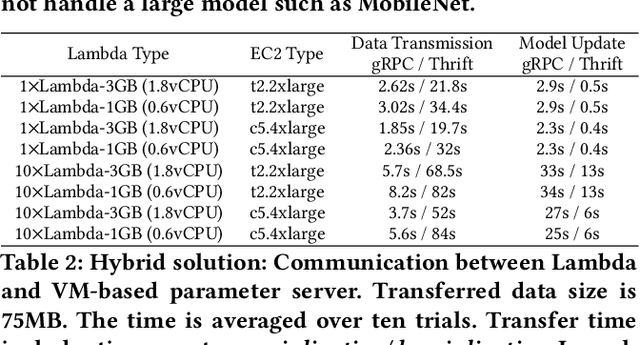
The appeal of serverless (FaaS) has triggered a growing interest on how to use it in data-intensive applications such as ETL, query processing, or machine learning (ML). Several systems exist for training large-scale ML models on top of serverless infrastructures (e.g., AWS Lambda) but with inconclusive results in terms of their performance and relative advantage over "serverful" infrastructures (IaaS). In this paper we present a systematic, comparative study of distributed ML training over FaaS and IaaS. We present a design space covering design choices such as optimization algorithms and synchronization protocols, and implement a platform, LambdaML, that enables a fair comparison between FaaS and IaaS. We present experimental results using LambdaML, and further develop an analytic model to capture cost/performance tradeoffs that must be considered when opting for a serverless infrastructure. Our results indicate that ML training pays off in serverless only for models with efficient (i.e., reduced) communication and that quickly converge. In general, FaaS can be much faster but it is never significantly cheaper than IaaS.
A Novel Transformer based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images
May 11, 2021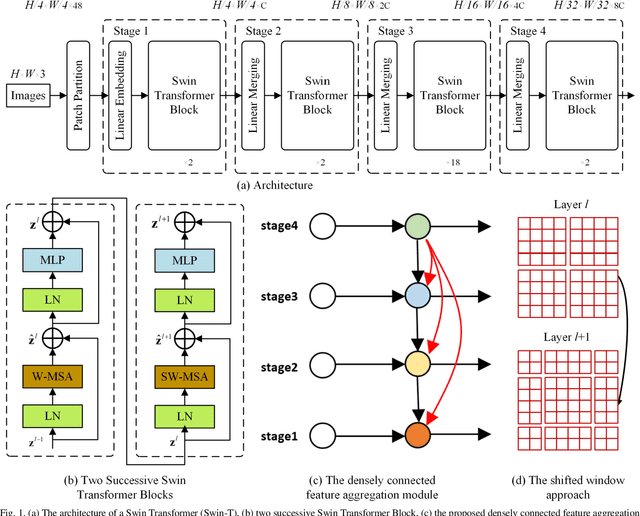
The fully-convolutional network (FCN) with an encoder-decoder architecture has been the standard paradigm for semantic segmentation. The encoder-decoder architecture utilizes an encoder to capture multi-level feature maps, which are incorporated into the final prediction by a decoder. As the context is crucial for precise segmentation, tremendous effort has been made to extract such information in an intelligent fashion, including employing dilated/atrous convolutions or inserting attention modules. However, these endeavours are all based on the FCN architecture with ResNet or other backbones, which cannot fully exploit the context from the theoretical concept. By contrast, we propose the Swin Transformer as the backbone to extract the context information and design a novel decoder of densely connected feature aggregation module (DCFAM) to restore the resolution and produce the segmentation map. The experimental results on two remotely sensed semantic segmentation datasets demonstrate the effectiveness of the proposed scheme.
Multilingual Language Models Predict Human Reading Behavior
Apr 12, 2021
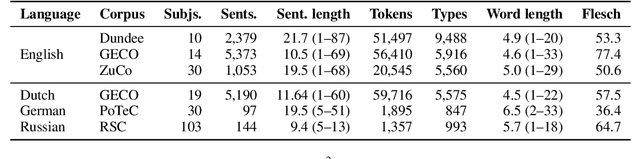

We analyze if large language models are able to predict patterns of human reading behavior. We compare the performance of language-specific and multilingual pretrained transformer models to predict reading time measures reflecting natural human sentence processing on Dutch, English, German, and Russian texts. This results in accurate models of human reading behavior, which indicates that transformer models implicitly encode relative importance in language in a way that is comparable to human processing mechanisms. We find that BERT and XLM models successfully predict a range of eye tracking features. In a series of experiments, we analyze the cross-domain and cross-language abilities of these models and show how they reflect human sentence processing.
Distributed Learning Systems with First-order Methods
Apr 12, 2021

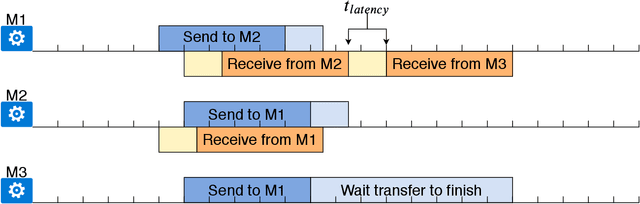
Scalable and efficient distributed learning is one of the main driving forces behind the recent rapid advancement of machine learning and artificial intelligence. One prominent feature of this topic is that recent progresses have been made by researchers in two communities: (1) the system community such as database, data management, and distributed systems, and (2) the machine learning and mathematical optimization community. The interaction and knowledge sharing between these two communities has led to the rapid development of new distributed learning systems and theory. In this work, we hope to provide a brief introduction of some distributed learning techniques that have recently been developed, namely lossy communication compression (e.g., quantization and sparsification), asynchronous communication, and decentralized communication. One special focus in this work is on making sure that it can be easily understood by researchers in both communities -- On the system side, we rely on a simplified system model hiding many system details that are not necessary for the intuition behind the system speedups; while, on the theory side, we rely on minimal assumptions and significantly simplify the proof of some recent work to achieve comparable results.
SaNet: Scale-aware Neural Network for Semantic Labelling of Multiple Spatial Resolution Aerial Images
Apr 10, 2021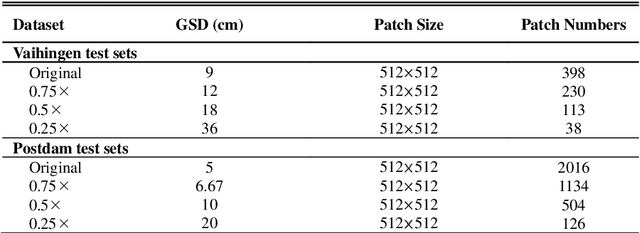


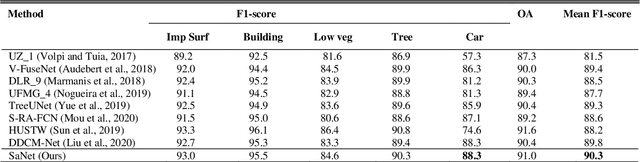
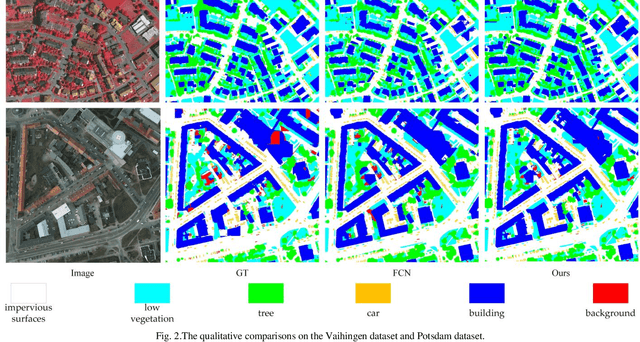
Assigning geospatial objects of aerial images with specific categories at the pixel level is a fundamental task in urban scene interpretation. Along with rapid developments in sensor technologies, aerial images can be captured at multiple spatial resolutions (MSR) with information content manifested at different scales. Extracting information from these MSR aerial images represents huge opportunities for enhanced feature representation and characterisation. However, MSR images suffer from two critical issues: 1) increased variation in the sizes of geospatial objects and 2) information and informative feature loss at coarse spatial resolutions. In this paper, we propose a novel scale-aware neural network (SaNet) for semantic labelling of MSR aerial images to address these two issues. SaNet deploys a densely connected feature network (DCFPN) module to capture high-quality multi-scale context, such as to address the scale variation issue and increase the quality of segmentation for both large and small objects simultaneously. A spatial feature recalibration (SFR) module is further incorporated into the network to learn complete semantic features with enhanced spatial relationships, where the effects of information and informative feature loss are addressed. The combination of DCFPN and SFR allows the proposed SaNet to learn scale-aware features from MSR aerial images. Extensive experiments undertaken on ISPRS semantic segmentation datasets demonstrated the outstanding accuracy of the proposed SaNet in cross-resolution segmentation, with an average OA of 83.4% on the Vaihingen dataset and an average F1 score of 80.4% on the Potsdam dataset, outperforming state-of-the-art deep learning approaches, including FPN (80.2% and 76.6%), PSPNet (79.8% and 76.2%) and Deeplabv3+ (80.8% and 76.1%) as well as DDCM-Net (81.7% and 77.6%) and EaNet (81.5% and 78.3%).
TRS: Transferability Reduced Ensemble via Encouraging Gradient Diversity and Model Smoothness
Apr 01, 2021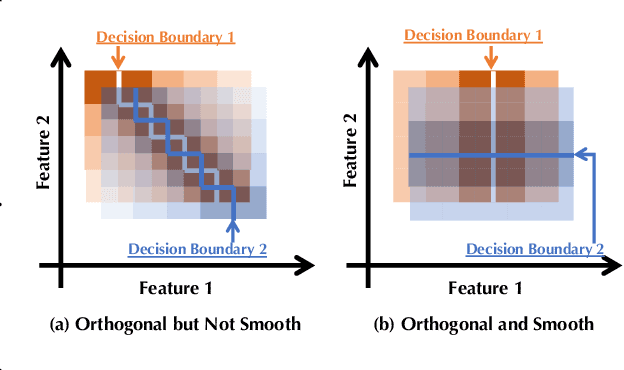
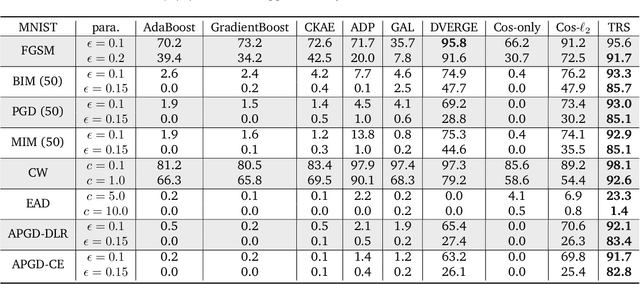
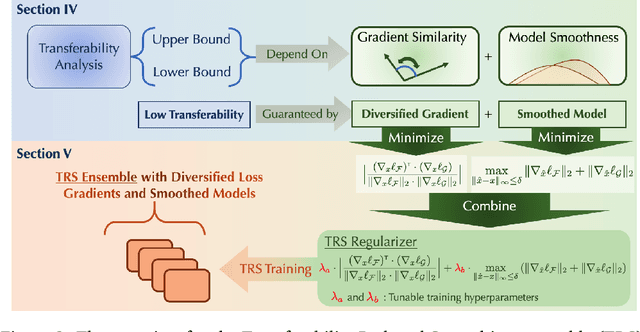
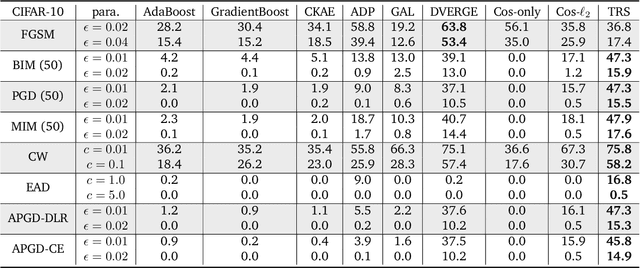
Adversarial Transferability is an intriguing property of adversarial examples -- a perturbation that is crafted against one model is also effective against another model, which may arise from a different model family or training process. To better protect ML systems against adversarial attacks, several questions are raised: what are the sufficient conditions for adversarial transferability? Is it possible to bound such transferability? Is there a way to reduce the transferability in order to improve the robustness of an ensemble ML model? To answer these questions, we first theoretically analyze sufficient conditions for transferability between models and propose a practical algorithm to reduce transferability within an ensemble to improve its robustness. Our theoretical analysis shows only the orthogonality between gradients of different models is not enough to ensure low adversarial transferability: the model smoothness is also an important factor. In particular, we provide a lower/upper bound of adversarial transferability based on model gradient similarity for low risk classifiers based on gradient orthogonality and model smoothness. We demonstrate that under the condition of gradient orthogonality, smoother classifiers will guarantee lower adversarial transferability. Furthermore, we propose an effective Transferability Reduced Smooth-ensemble(TRS) training strategy to train a robust ensemble with low transferability by enforcing model smoothness and gradient orthogonality between base models. We conduct extensive experiments on TRS by comparing with other state-of-the-art baselines on different datasets, showing that the proposed TRS outperforms all baselines significantly. We believe our analysis on adversarial transferability will inspire future research towards developing robust ML models taking these adversarial transferability properties into account.
DataLens: Scalable Privacy Preserving Training via Gradient Compression and Aggregation
Mar 20, 2021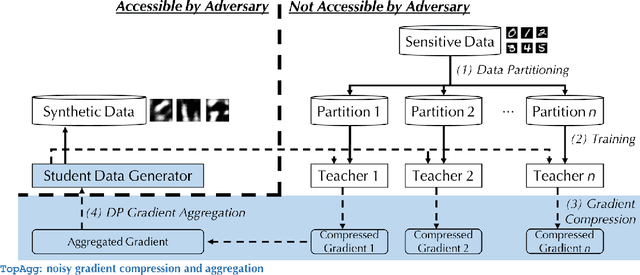
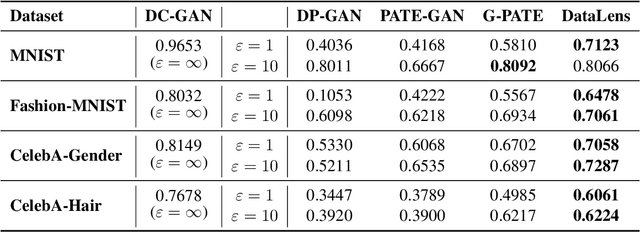
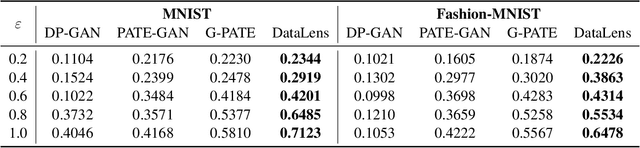
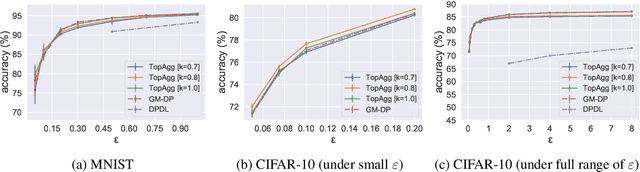
Recent success of deep neural networks (DNNs) hinges on the availability of large-scale dataset; however, training on such dataset often poses privacy risks for sensitive training information. In this paper, we aim to explore the power of generative models and gradient sparsity, and propose a scalable privacy-preserving generative model DATALENS. Comparing with the standard PATE privacy-preserving framework which allows teachers to vote on one-dimensional predictions, voting on the high dimensional gradient vectors is challenging in terms of privacy preservation. As dimension reduction techniques are required, we need to navigate a delicate tradeoff space between (1) the improvement of privacy preservation and (2) the slowdown of SGD convergence. To tackle this, we take advantage of communication efficient learning and propose a novel noise compression and aggregation approach TOPAGG by combining top-k compression for dimension reduction with a corresponding noise injection mechanism. We theoretically prove that the DATALENS framework guarantees differential privacy for its generated data, and provide analysis on its convergence. To demonstrate the practical usage of DATALENS, we conduct extensive experiments on diverse datasets including MNIST, Fashion-MNIST, and high dimensional CelebA, and we show that, DATALENS significantly outperforms other baseline DP generative models. In addition, we adapt the proposed TOPAGG approach, which is one of the key building blocks in DATALENS, to DP SGD training, and show that it is able to achieve higher utility than the state-of-the-art DP SGD approach in most cases.
Spectral Temporal Graph Neural Network for Multivariate Time-series Forecasting
Mar 13, 2021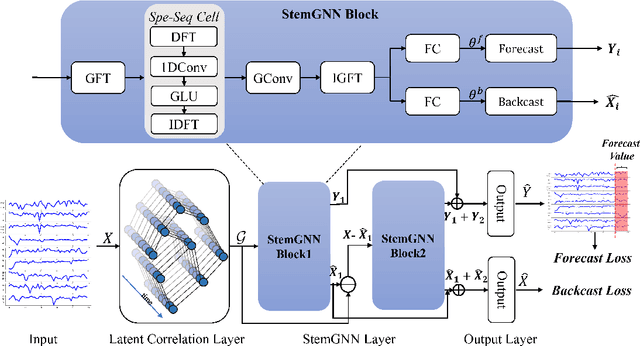

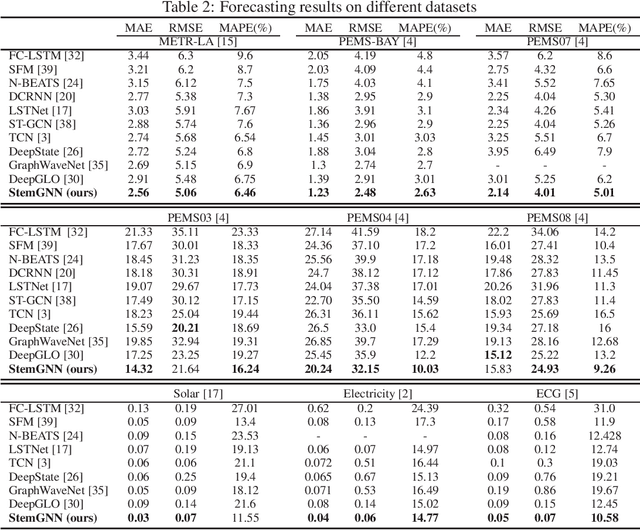
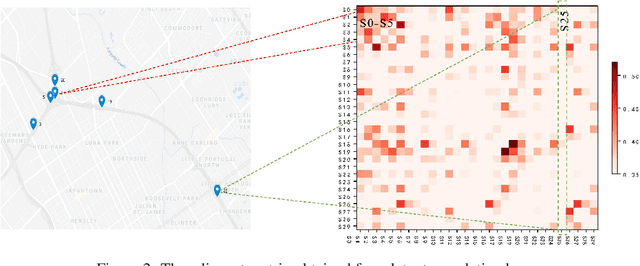
Multivariate time-series forecasting plays a crucial role in many real-world applications. It is a challenging problem as one needs to consider both intra-series temporal correlations and inter-series correlations simultaneously. Recently, there have been multiple works trying to capture both correlations, but most, if not all of them only capture temporal correlations in the time domain and resort to pre-defined priors as inter-series relationships. In this paper, we propose Spectral Temporal Graph Neural Network (StemGNN) to further improve the accuracy of multivariate time-series forecasting. StemGNN captures inter-series correlations and temporal dependencies \textit{jointly} in the \textit{spectral domain}. It combines Graph Fourier Transform (GFT) which models inter-series correlations and Discrete Fourier Transform (DFT) which models temporal dependencies in an end-to-end framework. After passing through GFT and DFT, the spectral representations hold clear patterns and can be predicted effectively by convolution and sequential learning modules. Moreover, StemGNN learns inter-series correlations automatically from the data without using pre-defined priors. We conduct extensive experiments on ten real-world datasets to demonstrate the effectiveness of StemGNN. Code is available at https://github.com/microsoft/StemGNN/
Evolving Attention with Residual Convolutions
Feb 20, 2021



Transformer is a ubiquitous model for natural language processing and has attracted wide attentions in computer vision. The attention maps are indispensable for a transformer model to encode the dependencies among input tokens. However, they are learned independently in each layer and sometimes fail to capture precise patterns. In this paper, we propose a novel and generic mechanism based on evolving attention to improve the performance of transformers. On one hand, the attention maps in different layers share common knowledge, thus the ones in preceding layers can instruct the attention in succeeding layers through residual connections. On the other hand, low-level and high-level attentions vary in the level of abstraction, so we adopt convolutional layers to model the evolutionary process of attention maps. The proposed evolving attention mechanism achieves significant performance improvement over various state-of-the-art models for multiple tasks, including image classification, natural language understanding and machine translation.