 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Traffic State Forecasting using Spatio-Temporal Network Dependencies: A Sparse Graph Neural Network Approach
Nov 06, 2022



Traffic state prediction in a transportation network is paramount for effective traffic operations and management, as well as informed user and system-level decision-making. However, long-term traffic prediction (beyond 30 minutes into the future) remains challenging in current research. In this work, we integrate the spatio-temporal dependencies in the transportation network from network modeling, together with the graph convolutional network (GCN) and graph attention network (GAT). To further tackle the dramatic computation and memory cost caused by the giant model size (i.e., number of weights) caused by multiple cascaded layers, we propose sparse training to mitigate the training cost, while preserving the prediction accuracy. It is a process of training using a fixed number of nonzero weights in each layer in each iteration. We consider the problem of long-term traffic speed forecasting for a real large-scale transportation network data from the California Department of Transportation (Caltrans) Performance Measurement System (PeMS). Experimental results show that the proposed GCN-STGT and GAT-STGT models achieve low prediction errors on short-, mid- and long-term prediction horizons, of 15, 30 and 45 minutes in duration, respectively. Using our sparse training, we could train from scratch with high sparsity (e.g., up to 90%), equivalent to 10 times floating point operations per second (FLOPs) reduction on computational cost using the same epochs as dense training, and arrive at a model with very small accuracy loss compared with the original dense training
Aerial Manipulation Using a Novel Unmanned Aerial Vehicle Cyber-Physical System
Oct 27, 2022Unmanned Aerial Vehicles(UAVs) are attaining more and more maneuverability and sensory ability as a promising teleoperation platform for intelligent interaction with the environments. This work presents a novel 5-degree-of-freedom (DoF) unmanned aerial vehicle (UAV) cyber-physical system for aerial manipulation. This UAV's body is capable of exerting powerful propulsion force in the longitudinal direction, decoupling the translational dynamics and the rotational dynamics on the longitudinal plane. A high-level impedance control law is proposed to drive the vehicle for trajectory tracking and interaction with the environments. In addition, a vision-based real-time target identification and tracking method integrating a YOLO v3 real-time object detector with feature tracking, and morphological operations is proposed to be implemented onboard the vehicle with support of model compression techniques to eliminate latency caused by video wireless transmission and heavy computation burden on traditional teleoperation platforms.
Towards Real-Time Temporal Graph Learning
Oct 12, 2022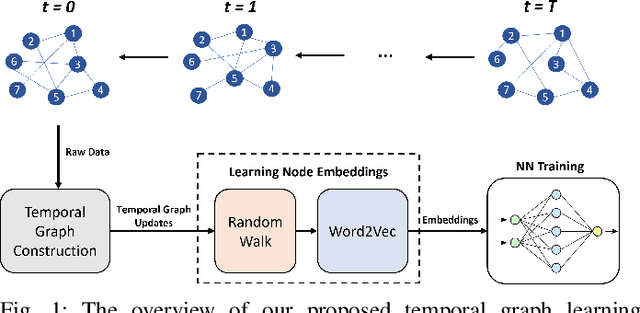
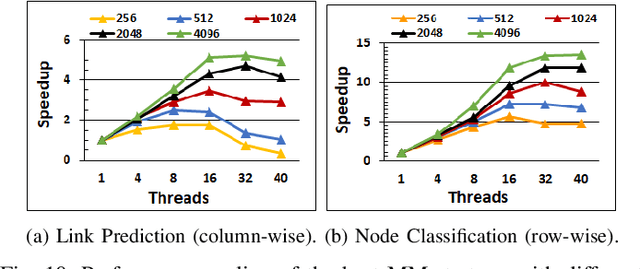
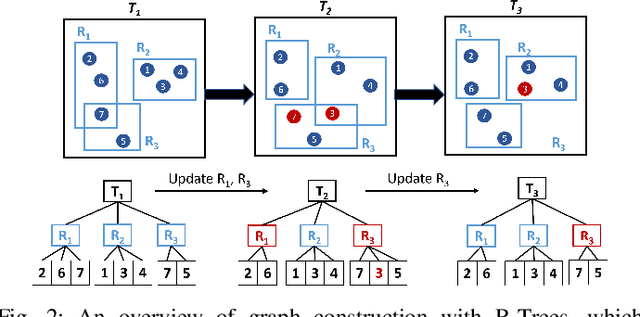
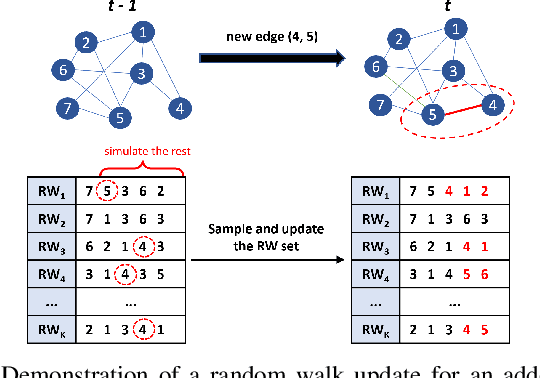
In recent years, graph representation learning has gained significant popularity, which aims to generate node embeddings that capture features of graphs. One of the methods to achieve this is employing a technique called random walks that captures node sequences in a graph and then learns embeddings for each node using a natural language processing technique called Word2Vec. These embeddings are then used for deep learning on graph data for classification tasks, such as link prediction or node classification. Prior work operates on pre-collected temporal graph data and is not designed to handle updates on a graph in real-time. Real world graphs change dynamically and their entire temporal updates are not available upfront. In this paper, we propose an end-to-end graph learning pipeline that performs temporal graph construction, creates low-dimensional node embeddings, and trains multi-layer neural network models in an online setting. The training of the neural network models is identified as the main performance bottleneck as it performs repeated matrix operations on many sequentially connected low-dimensional kernels. We propose to unlock fine-grain parallelism in these low-dimensional kernels to boost performance of model training.
PolyMPCNet: Towards ReLU-free Neural Architecture Search in Two-party Computation Based Private Inference
Sep 20, 2022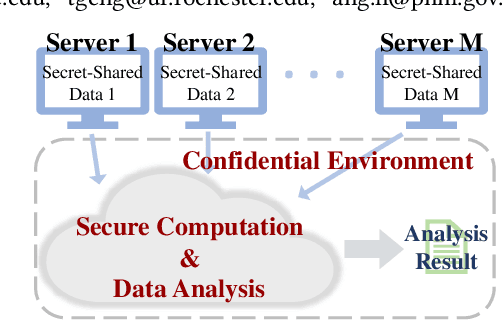
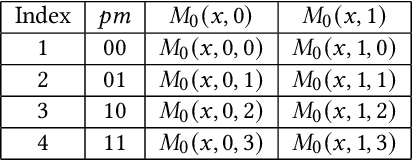
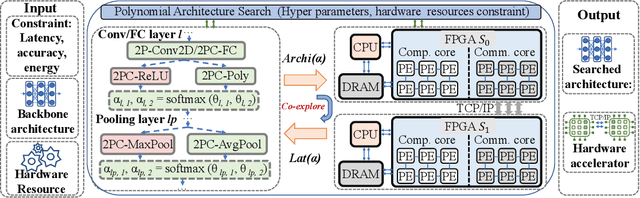
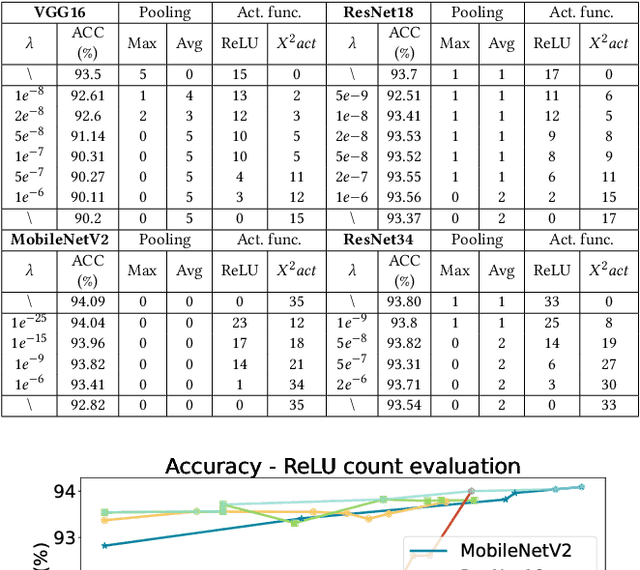
The rapid growth and deployment of deep learning (DL) has witnessed emerging privacy and security concerns. To mitigate these issues, secure multi-party computation (MPC) has been discussed, to enable the privacy-preserving DL computation. In practice, they often come at very high computation and communication overhead, and potentially prohibit their popularity in large scale systems. Two orthogonal research trends have attracted enormous interests in addressing the energy efficiency in secure deep learning, i.e., overhead reduction of MPC comparison protocol, and hardware acceleration. However, they either achieve a low reduction ratio and suffer from high latency due to limited computation and communication saving, or are power-hungry as existing works mainly focus on general computing platforms such as CPUs and GPUs. In this work, as the first attempt, we develop a systematic framework, PolyMPCNet, of joint overhead reduction of MPC comparison protocol and hardware acceleration, by integrating hardware latency of the cryptographic building block into the DNN loss function to achieve high energy efficiency, accuracy, and security guarantee. Instead of heuristically checking the model sensitivity after a DNN is well-trained (through deleting or dropping some non-polynomial operators), our key design principle is to em enforce exactly what is assumed in the DNN design -- training a DNN that is both hardware efficient and secure, while escaping the local minima and saddle points and maintaining high accuracy. More specifically, we propose a straight through polynomial activation initialization method for cryptographic hardware friendly trainable polynomial activation function to replace the expensive 2P-ReLU operator. We develop a cryptographic hardware scheduler and the corresponding performance model for Field Programmable Gate Arrays (FPGA) platform.
Uncertainty Quantification of Collaborative Detection for Self-Driving
Sep 16, 2022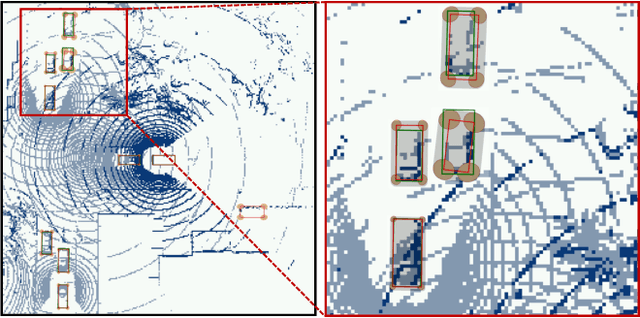
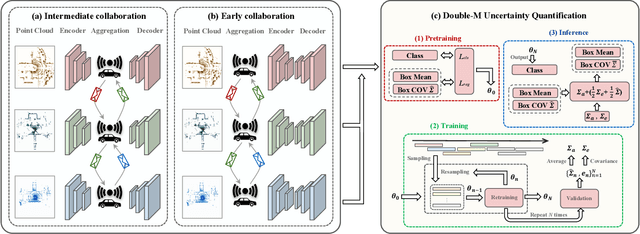
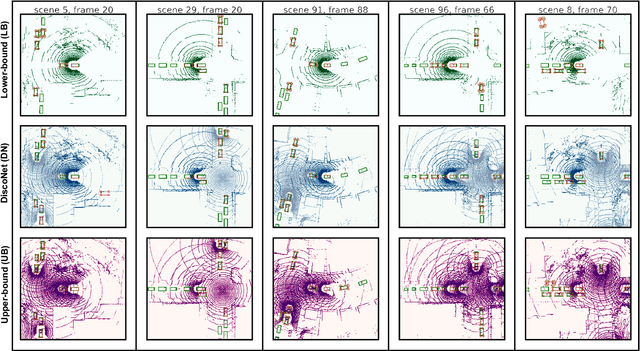
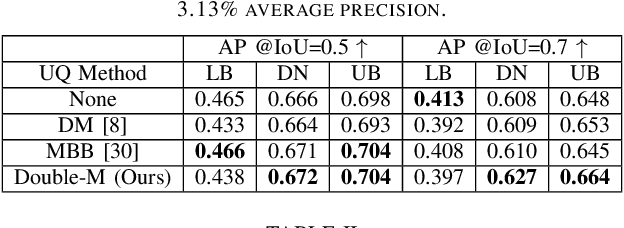
Sharing information between connected and autonomous vehicles (CAVs) fundamentally improves the performance of collaborative object detection for self-driving. However, CAVs still have uncertainties on object detection due to practical challenges, which will affect the later modules in self-driving such as planning and control. Hence, uncertainty quantification is crucial for safety-critical systems such as CAVs. Our work is the first to estimate the uncertainty of collaborative object detection. We propose a novel uncertainty quantification method, called Double-M Quantification, which tailors a moving block bootstrap (MBB) algorithm with direct modeling of the multivariant Gaussian distribution of each corner of the bounding box. Our method captures both the epistemic uncertainty and aleatoric uncertainty with one inference pass based on the offline Double-M training process. And it can be used with different collaborative object detectors. Through experiments on the comprehensive collaborative perception dataset, we show that our Double-M method achieves more than 4X improvement on uncertainty score and more than 3% accuracy improvement, compared with the state-of-the-art uncertainty quantification methods. Our code is public on https://coperception.github.io/double-m-quantification.
Towards Sparsification of Graph Neural Networks
Sep 11, 2022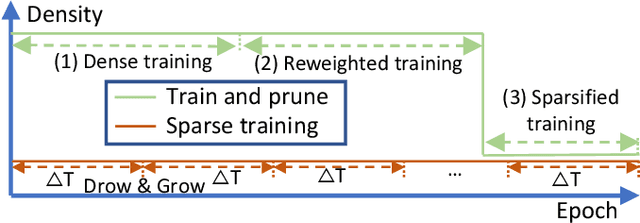
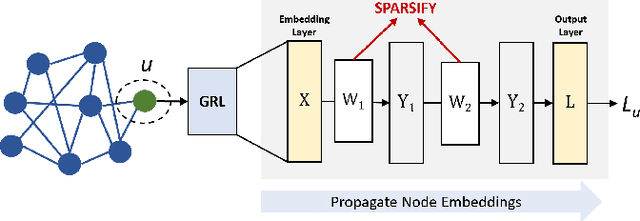
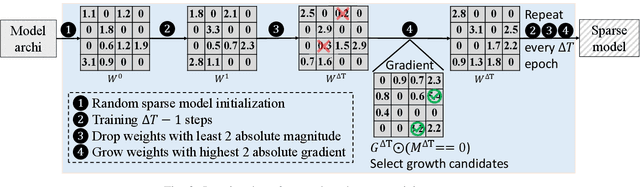

As real-world graphs expand in size, larger GNN models with billions of parameters are deployed. High parameter count in such models makes training and inference on graphs expensive and challenging. To reduce the computational and memory costs of GNNs, optimization methods such as pruning the redundant nodes and edges in input graphs have been commonly adopted. However, model compression, which directly targets the sparsification of model layers, has been mostly limited to traditional Deep Neural Networks (DNNs) used for tasks such as image classification and object detection. In this paper, we utilize two state-of-the-art model compression methods (1) train and prune and (2) sparse training for the sparsification of weight layers in GNNs. We evaluate and compare the efficiency of both methods in terms of accuracy, training sparsity, and training FLOPs on real-world graphs. Our experimental results show that on the ia-email, wiki-talk, and stackoverflow datasets for link prediction, sparse training with much lower training FLOPs achieves a comparable accuracy with the train and prune method. On the brain dataset for node classification, sparse training uses a lower number FLOPs (less than 1/7 FLOPs of train and prune method) and preserves a much better accuracy performance under extreme model sparsity.
Securing the Spike: On the Transferabilty and Security of Spiking Neural Networks to Adversarial Examples
Sep 07, 2022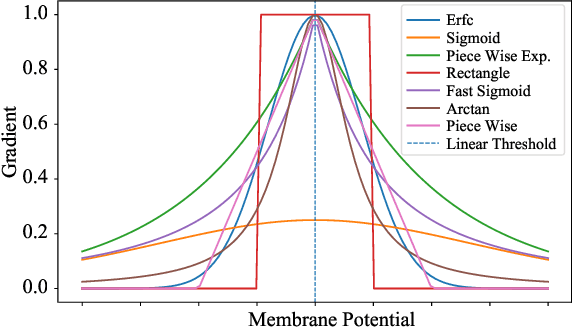
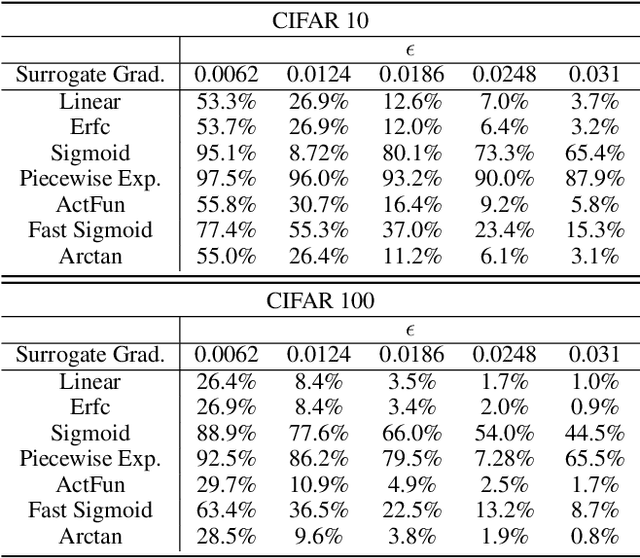
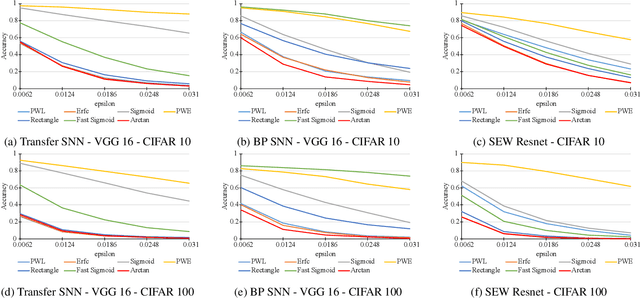
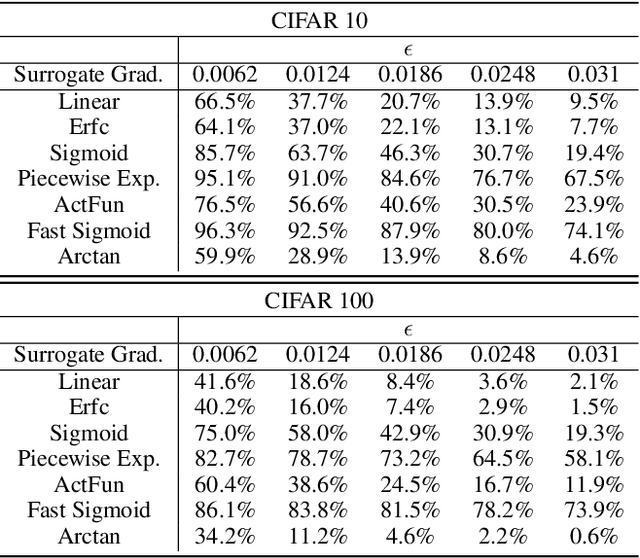
Spiking neural networks (SNNs) have attracted much attention for their high energy efficiency and for recent advances in their classification performance. However, unlike traditional deep learning approaches, the analysis and study of the robustness of SNNs to adversarial examples remains relatively underdeveloped. In this work we advance the field of adversarial machine learning through experimentation and analyses of three important SNN security attributes. First, we show that successful white-box adversarial attacks on SNNs are highly dependent on the underlying surrogate gradient technique. Second, we analyze the transferability of adversarial examples generated by SNNs and other state-of-the-art architectures like Vision Transformers and Big Transfer CNNs. We demonstrate that SNNs are not often deceived by adversarial examples generated by Vision Transformers and certain types of CNNs. Lastly, we develop a novel white-box attack that generates adversarial examples capable of fooling both SNN models and non-SNN models simultaneously. Our experiments and analyses are broad and rigorous covering two datasets (CIFAR-10 and CIFAR-100), five different white-box attacks and twelve different classifier models.
A Length Adaptive Algorithm-Hardware Co-design of Transformer on FPGA Through Sparse Attention and Dynamic Pipelining
Aug 07, 2022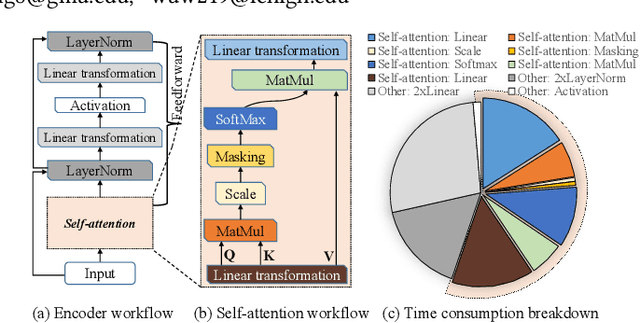
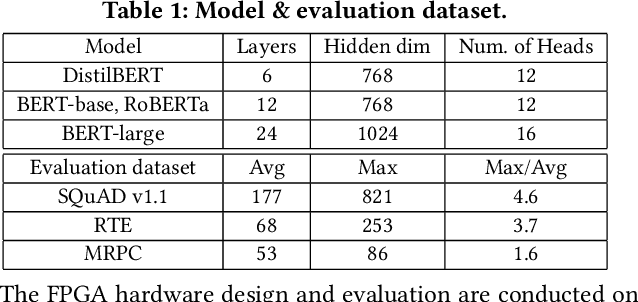
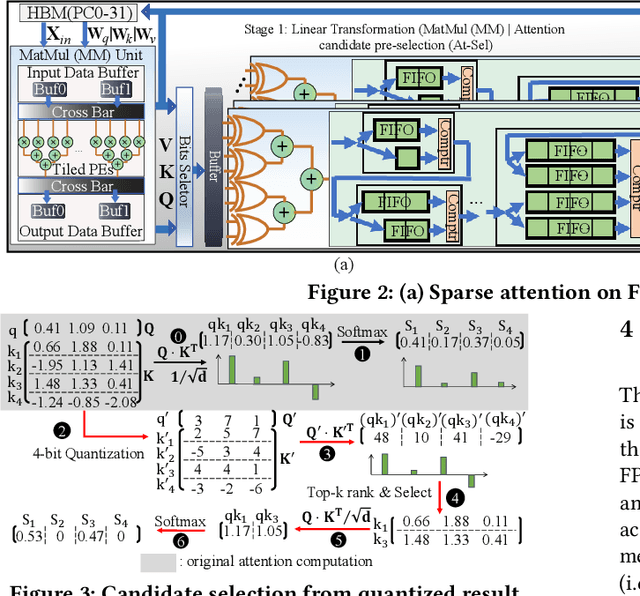
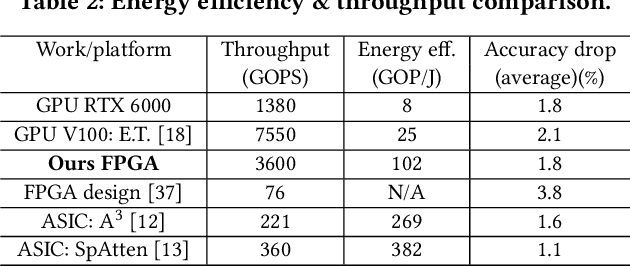
Transformers are considered one of the most important deep learning models since 2018, in part because it establishes state-of-the-art (SOTA) records and could potentially replace existing Deep Neural Networks (DNNs). Despite the remarkable triumphs, the prolonged turnaround time of Transformer models is a widely recognized roadblock. The variety of sequence lengths imposes additional computing overhead where inputs need to be zero-padded to the maximum sentence length in the batch to accommodate the parallel computing platforms. This paper targets the field-programmable gate array (FPGA) and proposes a coherent sequence length adaptive algorithm-hardware co-design for Transformer acceleration. Particularly, we develop a hardware-friendly sparse attention operator and a length-aware hardware resource scheduling algorithm. The proposed sparse attention operator brings the complexity of attention-based models down to linear complexity and alleviates the off-chip memory traffic. The proposed length-aware resource hardware scheduling algorithm dynamically allocates the hardware resources to fill up the pipeline slots and eliminates bubbles for NLP tasks. Experiments show that our design has very small accuracy loss and has 80.2 $\times$ and 2.6 $\times$ speedup compared to CPU and GPU implementation, and 4 $\times$ higher energy efficiency than state-of-the-art GPU accelerator optimized via CUBLAS GEMM.
EVE: Environmental Adaptive Neural Network Models for Low-power Energy Harvesting System
Jul 14, 2022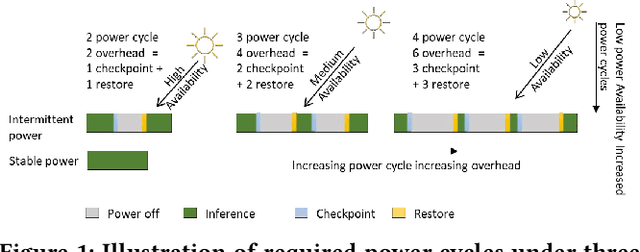
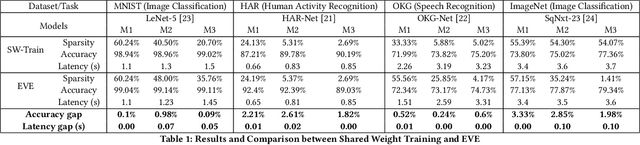
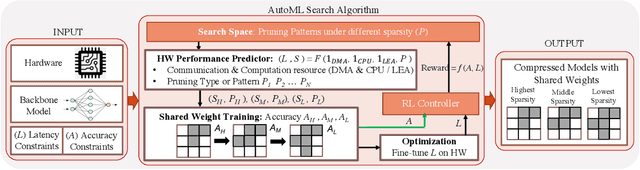
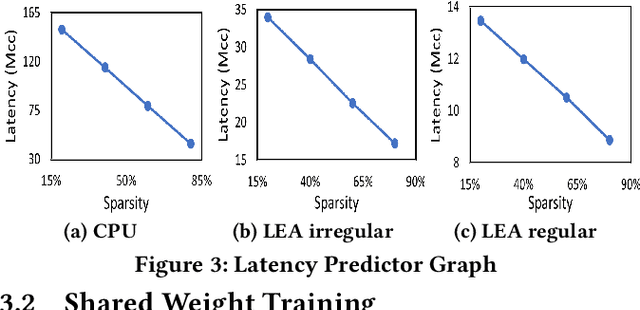
IoT devices are increasingly being implemented with neural network models to enable smart applications. Energy harvesting (EH) technology that harvests energy from ambient environment is a promising alternative to batteries for powering those devices due to the low maintenance cost and wide availability of the energy sources. However, the power provided by the energy harvester is low and has an intrinsic drawback of instability since it varies with the ambient environment. This paper proposes EVE, an automated machine learning (autoML) co-exploration framework to search for desired multi-models with shared weights for energy harvesting IoT devices. Those shared models incur significantly reduced memory footprint with different levels of model sparsity, latency, and accuracy to adapt to the environmental changes. An efficient on-device implementation architecture is further developed to efficiently execute each model on device. A run-time model extraction algorithm is proposed that retrieves individual model with negligible overhead when a specific model mode is triggered. Experimental results show that the neural networks models generated by EVE is on average 2.5X times faster than the baseline models without pruning and shared weights.
An Automatic and Efficient BERT Pruning for Edge AI Systems
Jun 21, 2022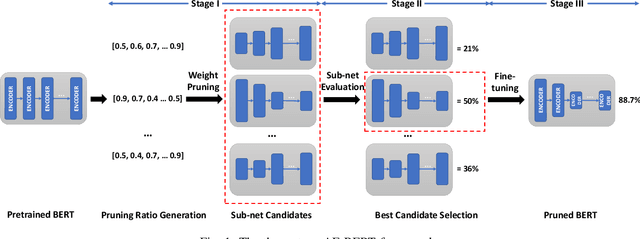
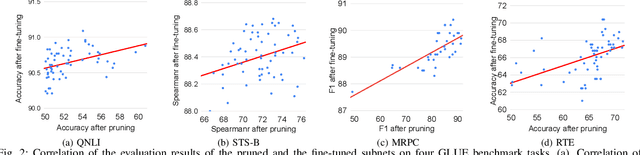
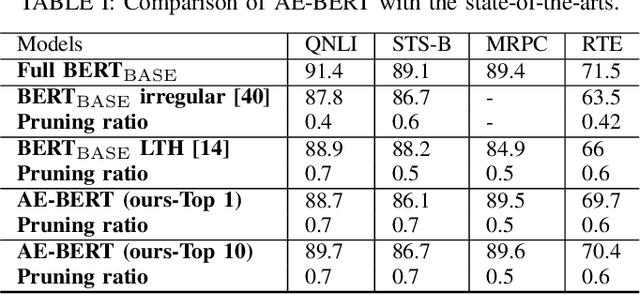
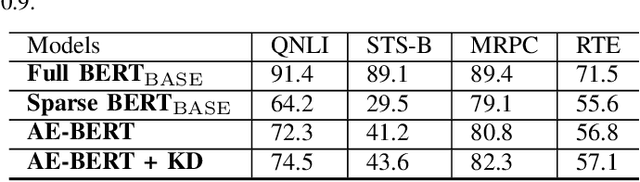
With the yearning for deep learning democratization, there are increasing demands to implement Transformer-based natural language processing (NLP) models on resource-constrained devices for low-latency and high accuracy. Existing BERT pruning methods require domain experts to heuristically handcraft hyperparameters to strike a balance among model size, latency, and accuracy. In this work, we propose AE-BERT, an automatic and efficient BERT pruning framework with efficient evaluation to select a "good" sub-network candidate (with high accuracy) given the overall pruning ratio constraints. Our proposed method requires no human experts experience and achieves a better accuracy performance on many NLP tasks. Our experimental results on General Language Understanding Evaluation (GLUE) benchmark show that AE-BERT outperforms the state-of-the-art (SOTA) hand-crafted pruning methods on BERT$_{\mathrm{BASE}}$. On QNLI and RTE, we obtain 75\% and 42.8\% more overall pruning ratio while achieving higher accuracy. On MRPC, we obtain a 4.6 higher score than the SOTA at the same overall pruning ratio of 0.5. On STS-B, we can achieve a 40\% higher pruning ratio with a very small loss in Spearman correlation compared to SOTA hand-crafted pruning methods. Experimental results also show that after model compression, the inference time of a single BERT$_{\mathrm{BASE}}$ encoder on Xilinx Alveo U200 FPGA board has a 1.83$\times$ speedup compared to Intel(R) Xeon(R) Gold 5218 (2.30GHz) CPU, which shows the reasonableness of deploying the proposed method generated subnets of BERT$_{\mathrm{BASE}}$ model on computation restricted devices.