 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEER: Automatic Prompt Engineering Enhances Large Language Model Reranking
Jun 20, 2024Large Language Models (LLMs) have significantly enhanced Information Retrieval (IR) across various modules, such as reranking. Despite impressive performance, current zero-shot relevance ranking with LLMs heavily relies on human prompt engineering. Existing automatic prompt engineering algorithms primarily focus on language modeling and classification tasks, leaving the domain of IR, particularly reranking, underexplored. Directly applying current prompt engineering algorithms to relevance ranking is challenging due to the integration of query and long passage pairs in the input, where the ranking complexity surpasses classification tasks. To reduce human effort and unlock the potential of prompt optimization in reranking, we introduce a novel automatic prompt engineering algorithm named APEER. APEER iteratively generates refined prompts through feedback and preference optimization. Extensive experiments with four LLMs and ten datasets demonstrate the substantial performance improvement of APEER over existing state-of-the-art (SoTA) manual prompts. Furthermore, we find that the prompts generated by APEER exhibit better transferability across diverse tasks and LLMs. Code is available at https://github.com/jincan333/APEER.
A Secure and Efficient Federated Learning Framework for NLP
Jan 28, 2022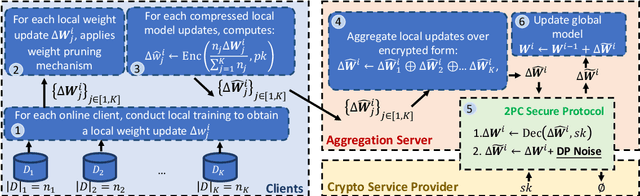
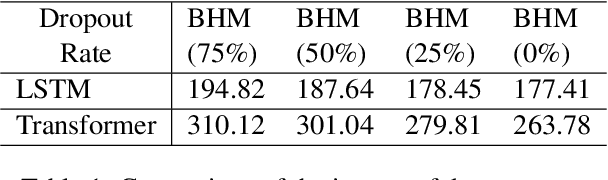
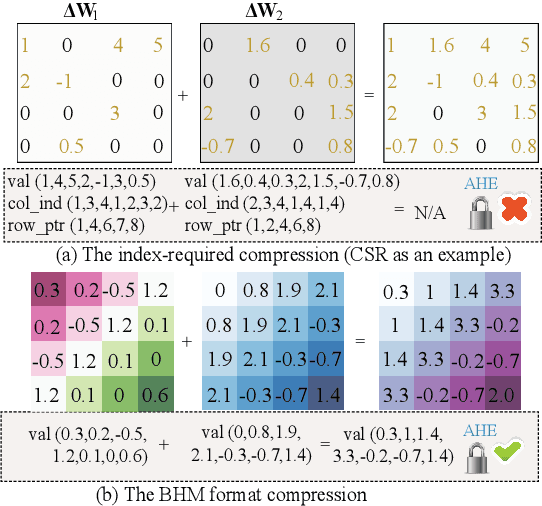
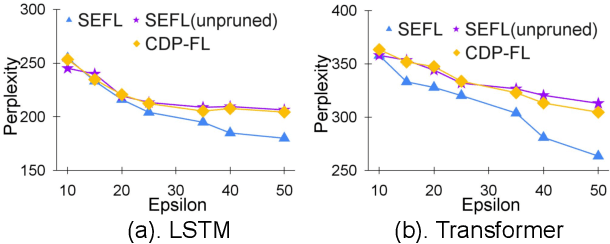
In this work, we consider the problem of designing secure and efficient federated learning (FL) frameworks. Existing solutions either involve a trusted aggregator or require heavyweight cryptographic primitives, which degrades performance significantly. Moreover, many existing secure FL designs work only under the restrictive assumption that none of the clients can be dropped out from the training protocol. To tackle these problems, we propose SEFL, a secure and efficient FL framework that (1) eliminates the need for the trusted entities; (2) achieves similar and even better model accuracy compared with existing FL designs; (3) is resilient to client dropouts. Through extensive experimental studies on natural language processing (NLP) tasks, we demonstrate that the SEFL achieves comparable accuracy compared to existing FL solutions, and the proposed pruning technique can improve runtime performance up to 13.7x.
SAPAG: A Self-Adaptive Privacy Attack From Gradients
Sep 14, 2020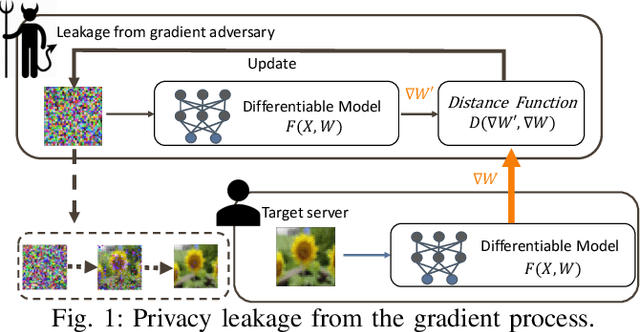

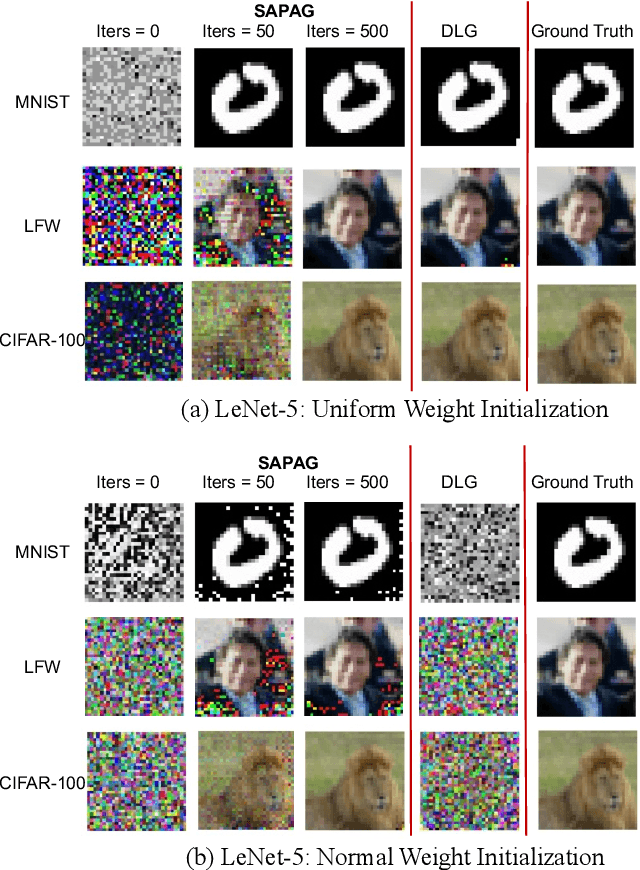
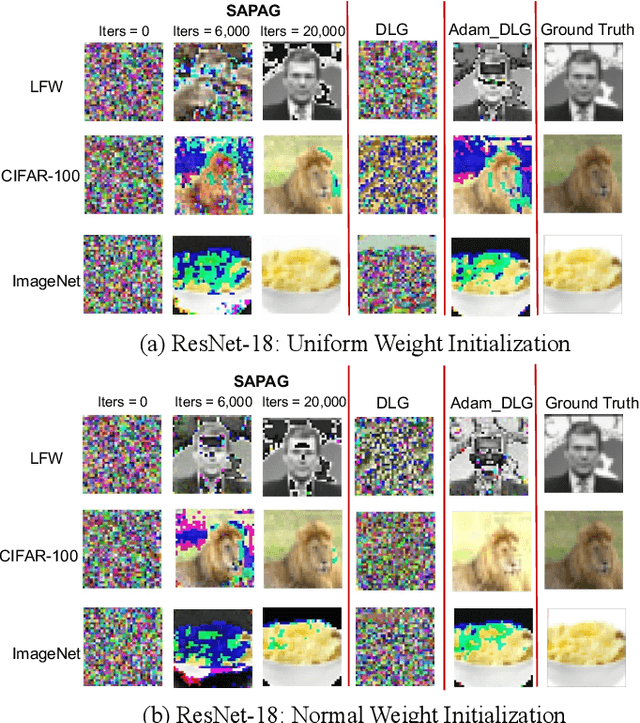
Distributed learning such as federated learning or collaborative learning enables model training on decentralized data from users and only collects local gradients, where data is processed close to its sources for data privacy. The nature of not centralizing the training data addresses the privacy issue of privacy-sensitive data. Recent studies show that a third party can reconstruct the true training data in the distributed machine learning system through the publicly-shared gradients. However, existing reconstruction attack frameworks lack generalizability on different Deep Neural Network (DNN) architectures and different weight distribution initialization, and can only succeed in the early training phase. To address these limitations, in this paper, we propose a more general privacy attack from gradient, SAPAG, which uses a Gaussian kernel based of gradient difference as a distance measure. Our experiments demonstrate that SAPAG can construct the training data on different DNNs with different weight initializations and on DNNs in any training phases.
MCMIA: Model Compression Against Membership Inference Attack in Deep Neural Networks
Aug 28, 2020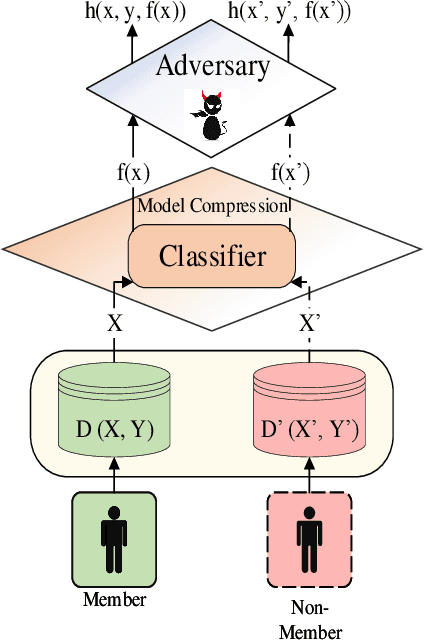
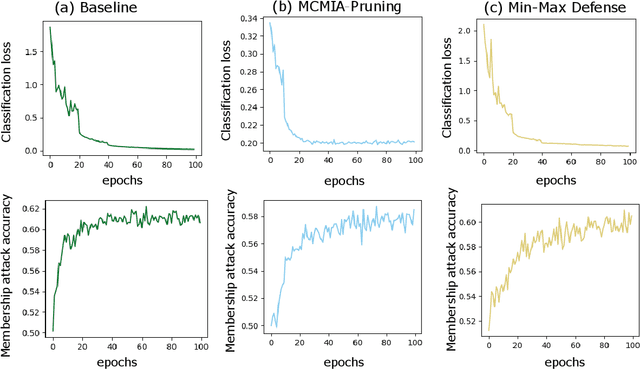
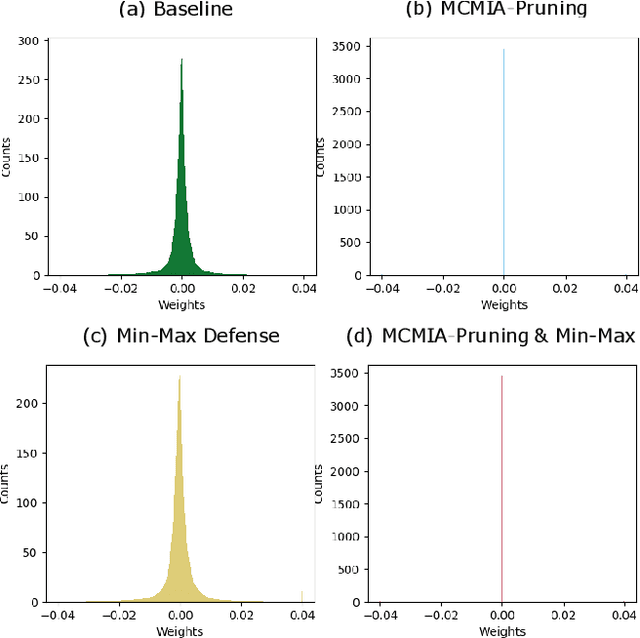
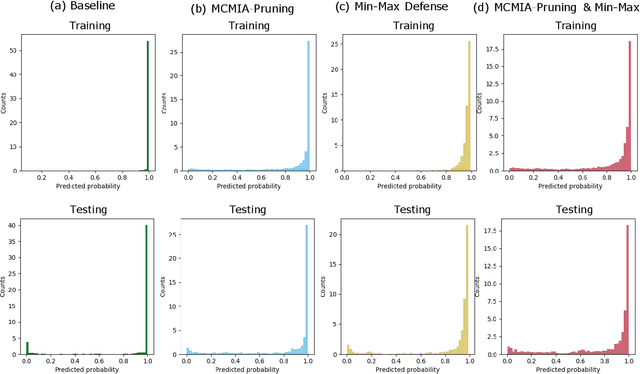
Deep learning or deep neural networks (DNNs) have nowadays enabled high performance, including but not limited to fraud detection, recommendations, and different kinds of analytical transactions. However, the large model size, high computational cost, and vulnerability against membership inference attack (MIA) have impeded its popularity, especially on resource-constrained edge devices. As the first attempt to simultaneously address these challenges, we envision that DNN model compression technique will help deep learning models against MIA while reducing model storage and computational cost. We jointly formulate model compression and MIA as MCMIA, and provide an analytic method of solving the problem. We evaluate our method on LeNet-5, VGG16, MobileNetV2, ResNet18 on different datasets including MNIST, CIFAR-10, CIFAR-100, and ImageNet. Experimental results show that our MCMIA model can reduce the attack accuracy, therefore reduce the information leakage from MIA. Our proposed method significantly outperforms differential privacy (DP) on MIA. Compared with our MCMIA--Pruning, our MCMIA--Pruning \& Min-Max game can achieve the lowest attack accuracy, therefore maximally enhance DNN model privacy. Thanks to the hardware-friendly characteristic of model compression, our proposed MCMIA is especially useful in deploying DNNs on resource-constrained platforms in a privacy-preserving manner.