 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransportAgents: a multi-agents LLM framework for traffic accident severity prediction
Jan 21, 2026Accurate prediction of traffic crash severity is critical for improving emergency response and public safety planning. Although recent large language models (LLMs) exhibit strong reasoning capabilities, their single-agent architectures often struggle with heterogeneous, domain-specific crash data and tend to generate biased or unstable predictions. To address these limitations, this paper proposes TransportAgents, a hybrid multi-agent framework that integrates category-specific LLM reasoning with a multilayer perceptron (MLP) integration module. Each specialized agent focuses on a particular subset of traffic information, such as demographics, environmental context, or incident details, to produce intermediate severity assessments that are subsequently fused into a unified prediction. Extensive experiments on two complementary U.S. datasets, the Consumer Product Safety Risk Management System (CPSRMS) and the National Electronic Injury Surveillance System (NEISS), demonstrate that TransportAgents consistently outperforms both traditional machine learning and advanced LLM-based baselines. Across three representative backbones, including closed-source models such as GPT-3.5 and GPT-4o, as well as open-source models such as LLaMA-3.3, the framework exhibits strong robustness, scalability, and cross-dataset generalizability. A supplementary distributional analysis further shows that TransportAgents produces more balanced and well-calibrated severity predictions than standard single-agent LLM approaches, highlighting its interpretability and reliability for safety-critical decision support applications.
StgcDiff: Spatial-Temporal Graph Condition Diffusion for Sign Language Transition Generation
Jun 16, 2025Sign language transition generation seeks to convert discrete sign language segments into continuous sign videos by synthesizing smooth transitions. However,most existing methods merely concatenate isolated signs, resulting in poor visual coherence and semantic accuracy in the generated videos. Unlike textual languages,sign language is inherently rich in spatial-temporal cues, making it more complex to model. To address this,we propose StgcDiff, a graph-based conditional diffusion framework that generates smooth transitions between discrete signs by capturing the unique spatial-temporal dependencies of sign language. Specifically, we first train an encoder-decoder architecture to learn a structure-aware representation of spatial-temporal skeleton sequences. Next, we optimize a diffusion denoiser conditioned on the representations learned by the pre-trained encoder, which is tasked with predicting transition frames from noise. Additionally, we design the Sign-GCN module as the key component in our framework, which effectively models the spatial-temporal features. Extensive experiments conducted on the PHOENIX14T, USTC-CSL100,and USTC-SLR500 datasets demonstrate the superior performance of our method.
E-bike agents: Large Language Model-Driven E-Bike Accident Analysis and Severity Prediction
Jun 05, 2025



Electric bicycles (e-bikes) are rapidly increasing in use, raising safety concerns due to a rise in accident reports. However, e-bike incident reports often use unstructured narrative formats, which hinders quantitative safety analysis. This study introduces E-bike agents, a framework that uses large language models (LLM) powered agents to classify and extract safety variables from unstructured incident reports. Our framework consists of four LLM agents, handling data classification, information extraction, injury cause determination, and component linkage, to extract the key factors that could lead to E-bike accidents and cause varying severity levels. Furthermore, we used an ordered logit model to examine the relationship between the severity of the incident and the factors retrieved, such as gender, the type of cause, and environmental conditions. Our research shows that equipment issues are slightly more common than human-related ones, but human-related incidents are more often fatal. Specifically, pedals, tires, and brakes are frequent contributors to accidents. The model achieves a high weighted F1 score of 0.87 in classification accuracy, highlighting the potential of using LLMs to extract unstructured data in niche domains, such as transportation. Our method offers a scalable solution to improve e-bike safety analytics and provides actionable information for policy makers, designers, and regulators.
Self-GIVE: Associative Thinking from Limited Structured Knowledge for Enhanced Large Language Model Reasoning
May 21, 2025When addressing complex questions that require new information, people often associate the question with existing knowledge to derive a sensible answer. For instance, when evaluating whether melatonin aids insomnia, one might associate "hormones helping mental disorders" with "melatonin being a hormone and insomnia a mental disorder" to complete the reasoning. Large Language Models (LLMs) also require such associative thinking, particularly in resolving scientific inquiries when retrieved knowledge is insufficient and does not directly answer the question. Graph Inspired Veracity Extrapolation (GIVE) addresses this by using a knowledge graph (KG) to extrapolate structured knowledge. However, it involves the construction and pruning of many hypothetical triplets, which limits efficiency and generalizability. We propose Self-GIVE, a retrieve-RL framework that enhances LLMs with automatic associative thinking through reinforcement learning. Self-GIVE extracts structured information and entity sets to assist the model in linking to the queried concepts. We address GIVE's key limitations: (1) extensive LLM calls and token overhead for knowledge extrapolation, (2) difficulty in deploying on smaller LLMs (3B or 7B) due to complex instructions, and (3) inaccurate knowledge from LLM pruning. Specifically, after fine-tuning using self-GIVE with a 135 node UMLS KG, it improves the performance of the Qwen2.5 3B and 7B models by up to $\textbf{28.5%$\rightarrow$71.4%}$ and $\textbf{78.6$\rightarrow$90.5%}$ in samples $\textbf{unseen}$ in challenging biomedical QA tasks. In particular, Self-GIVE allows the 7B model to match or outperform GPT3.5 turbo with GIVE, while cutting token usage by over 90\%. Self-GIVE enhances the scalable integration of structured retrieval and reasoning with associative thinking.
GeoGrid-Bench: Can Foundation Models Understand Multimodal Gridded Geo-Spatial Data?
May 15, 2025We present GeoGrid-Bench, a benchmark designed to evaluate the ability of foundation models to understand geo-spatial data in the grid structure. Geo-spatial datasets pose distinct challenges due to their dense numerical values, strong spatial and temporal dependencies, and unique multimodal representations including tabular data, heatmaps, and geographic visualizations. To assess how foundation models can support scientific research in this domain, GeoGrid-Bench features large-scale, real-world data covering 16 climate variables across 150 locations and extended time frames. The benchmark includes approximately 3,200 question-answer pairs, systematically generated from 8 domain expert-curated templates to reflect practical tasks encountered by human scientists. These range from basic queries at a single location and time to complex spatiotemporal comparisons across regions and periods. Our evaluation reveals that vision-language models perform best overall, and we provide a fine-grained analysis of the strengths and limitations of different foundation models in different geo-spatial tasks. This benchmark offers clearer insights into how foundation models can be effectively applied to geo-spatial data analysis and used to support scientific research.
GIVE: Structured Reasoning with Knowledge Graph Inspired Veracity Extrapolation
Oct 11, 2024



Existing retrieval-based reasoning approaches for large language models (LLMs) heavily rely on the density and quality of the non-parametric knowledge source to provide domain knowledge and explicit reasoning chain. However, inclusive knowledge sources are expensive and sometimes infeasible to build for scientific or corner domains. To tackle the challenges, we introduce Graph Inspired Veracity Extrapolation (GIVE), a novel reasoning framework that integrates the parametric and non-parametric memories to enhance both knowledge retrieval and faithful reasoning processes on very sparse knowledge graphs. By leveraging the external structured knowledge to inspire LLM to model the interconnections among relevant concepts, our method facilitates a more logical and step-wise reasoning approach akin to experts' problem-solving, rather than gold answer retrieval. Specifically, the framework prompts LLMs to decompose the query into crucial concepts and attributes, construct entity groups with relevant entities, and build an augmented reasoning chain by probing potential relationships among node pairs across these entity groups. Our method incorporates both factual and extrapolated linkages to enable comprehensive understanding and response generation. Extensive experiments on reasoning-intense benchmarks on biomedical and commonsense QA demonstrate the effectiveness of our proposed method. Specifically, GIVE enables GPT3.5-turbo to outperform advanced models like GPT4 without any additional training cost, thereby underscoring the efficacy of integrating structured information and internal reasoning ability of LLMs for tackling specialized tasks with limited external resources.
Network Alignment with Transferable Graph Autoencoders
Oct 05, 2023Network alignment is the task of establishing one-to-one correspondences between the nodes of different graphs and finds a plethora of applications in high-impact domains. However, this task is known to be NP-hard in its general form, and existing algorithms do not scale up as the size of the graphs increases. To tackle both challenges we propose a novel generalized graph autoencoder architecture, designed to extract powerful and robust node embeddings, that are tailored to the alignment task. We prove that the generated embeddings are associated with the eigenvalues and eigenvectors of the graphs and can achieve more accurate alignment compared to classical spectral methods. Our proposed framework also leverages transfer learning and data augmentation to achieve efficient network alignment at a very large scale without retraining. Extensive experiments on both network and sub-network alignment with real-world graphs provide corroborating evidence supporting the effectiveness and scalability of the proposed approach.
Performance analysis of facial recognition: A critical review through glass factor
Apr 04, 2021
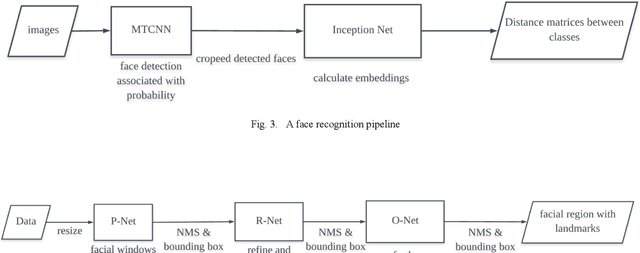
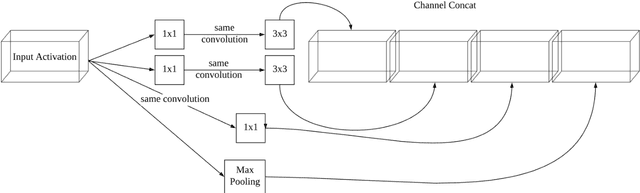

COVID-19 pandemic and social distancing urge a reliable human face recognition system in different abnormal situations. However, there is no research which studies the influence of glass factor in facial recognition system. This paper provides a comprehensive review of glass factor. The study contains two steps: data collection and accuracy test. Data collection includes collecting human face images through different situations, such as clear glasses, glass with water and glass with mist. Based on the collected data, an existing state-of-the-art face detection and recognition system built upon MTCNN and Inception V1 deep nets is tested for further analysis. Experimental data supports that 1) the system is robust for classification when comparing real-time images and 2) it fails at determining if two images are of same person by comparing real-time disturbed image with the frontal ones.