 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Sound Localization in the Wild by Cross-Modal Interference Erasing
Feb 13, 2022
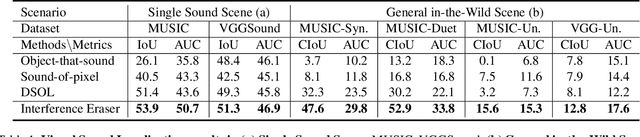
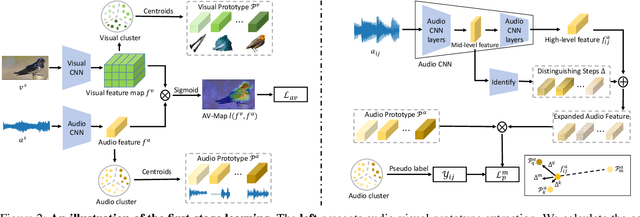

The task of audio-visual sound source localization has been well studied under constrained scenes, where the audio recordings are clean. However, in real-world scenarios, audios are usually contaminated by off-screen sound and background noise. They will interfere with the procedure of identifying desired sources and building visual-sound connections, making previous studies non-applicable. In this work, we propose the Interference Eraser (IEr) framework, which tackles the problem of audio-visual sound source localization in the wild. The key idea is to eliminate the interference by redefining and carving discriminative audio representations. Specifically, we observe that the previous practice of learning only a single audio representation is insufficient due to the additive nature of audio signals. We thus extend the audio representation with our Audio-Instance-Identifier module, which clearly distinguishes sounding instances when audio signals of different volumes are unevenly mixed. Then we erase the influence of the audible but off-screen sounds and the silent but visible objects by a Cross-modal Referrer module with cross-modality distillation. Quantitative and qualitative evaluations demonstrate that our proposed framework achieves superior results on sound localization tasks, especially under real-world scenarios. Code is available at https://github.com/alvinliu0/Visual-Sound-Localization-in-the-Wild.
Semantic-Aware Implicit Neural Audio-Driven Video Portrait Generation
Jan 19, 2022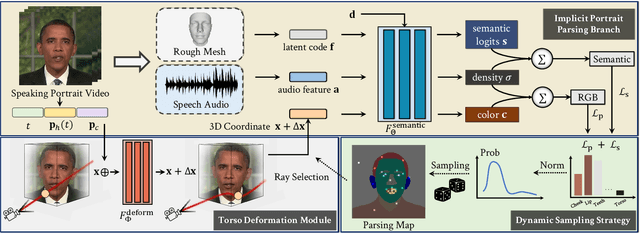
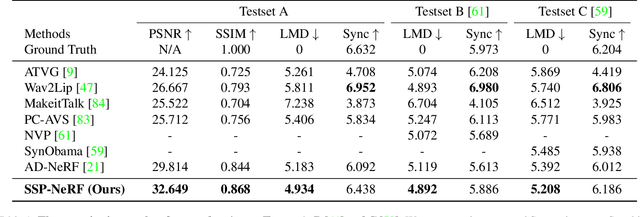
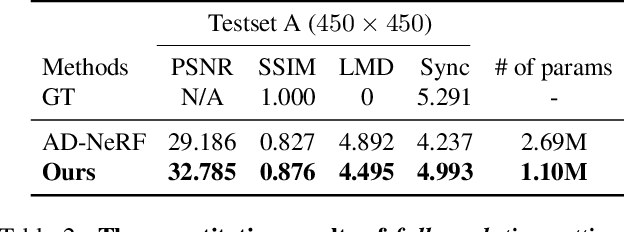

Animating high-fidelity video portrait with speech audio is crucial for virtual reality and digital entertainment. While most previous studies rely on accurate explicit structural information, recent works explore the implicit scene representation of Neural Radiance Fields (NeRF) for realistic generation. In order to capture the inconsistent motions as well as the semantic difference between human head and torso, some work models them via two individual sets of NeRF, leading to unnatural results. In this work, we propose Semantic-aware Speaking Portrait NeRF (SSP-NeRF), which creates delicate audio-driven portraits using one unified set of NeRF. The proposed model can handle the detailed local facial semantics and the global head-torso relationship through two semantic-aware modules. Specifically, we first propose a Semantic-Aware Dynamic Ray Sampling module with an additional parsing branch that facilitates audio-driven volume rendering. Moreover, to enable portrait rendering in one unified neural radiance field, a Torso Deformation module is designed to stabilize the large-scale non-rigid torso motions. Extensive evaluations demonstrate that our proposed approach renders more realistic video portraits compared to previous methods. Project page: https://alvinliu0.github.io/projects/SSP-NeRF
AutoAlign: Pixel-Instance Feature Aggregation for Multi-Modal 3D Object Detection
Jan 17, 2022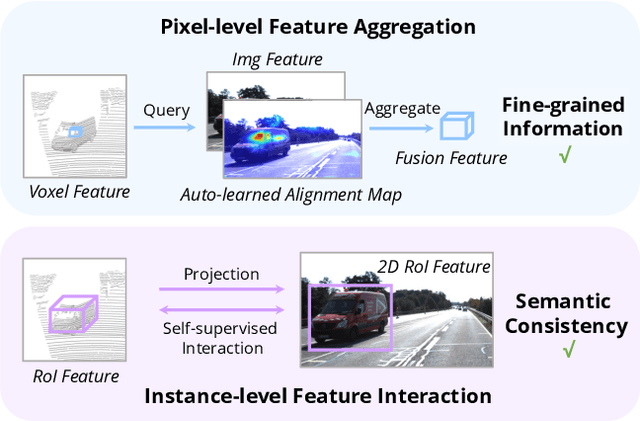
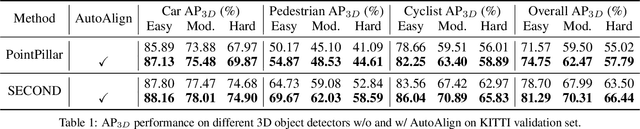
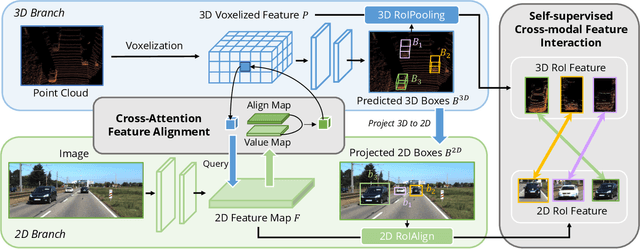

Object detection through either RGB images or the LiDAR point clouds has been extensively explored in autonomous driving. However, it remains challenging to make these two data sources complementary and beneficial to each other. In this paper, we propose \textit{AutoAlign}, an automatic feature fusion strategy for 3D object detection. Instead of establishing deterministic correspondence with camera projection matrix, we model the mapping relationship between the image and point clouds with a learnable alignment map. This map enables our model to automate the alignment of non-homogenous features in a dynamic and data-driven manner. Specifically, a cross-attention feature alignment module is devised to adaptively aggregate \textit{pixel-level} image features for each voxel. To enhance the semantic consistency during feature alignment, we also design a self-supervised cross-modal feature interaction module, through which the model can learn feature aggregation with \textit{instance-level} feature guidance. Extensive experimental results show that our approach can lead to 2.3 mAP and 7.0 mAP improvements on the KITTI and nuScenes datasets, respectively. Notably, our best model reaches 70.9 NDS on the nuScenes testing leaderboard, achieving competitive performance among various state-of-the-arts.
3D-aware Image Synthesis via Learning Structural and Textural Representations
Dec 20, 2021

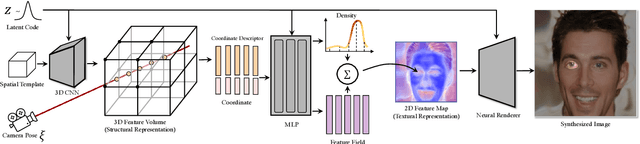
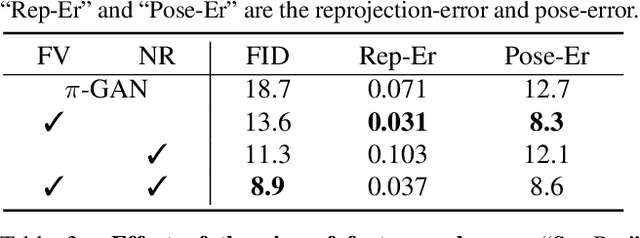
Making generative models 3D-aware bridges the 2D image space and the 3D physical world yet remains challenging. Recent attempts equip a Generative Adversarial Network (GAN) with a Neural Radiance Field (NeRF), which maps 3D coordinates to pixel values, as a 3D prior. However, the implicit function in NeRF has a very local receptive field, making the generator hard to become aware of the global structure. Meanwhile, NeRF is built on volume rendering which can be too costly to produce high-resolution results, increasing the optimization difficulty. To alleviate these two problems, we propose a novel framework, termed as VolumeGAN, for high-fidelity 3D-aware image synthesis, through explicitly learning a structural representation and a textural representation. We first learn a feature volume to represent the underlying structure, which is then converted to a feature field using a NeRF-like model. The feature field is further accumulated into a 2D feature map as the textural representation, followed by a neural renderer for appearance synthesis. Such a design enables independent control of the shape and the appearance. Extensive experiments on a wide range of datasets show that our approach achieves sufficiently higher image quality and better 3D control than the previous methods.
Cross-Model Pseudo-Labeling for Semi-Supervised Action Recognition
Dec 17, 2021
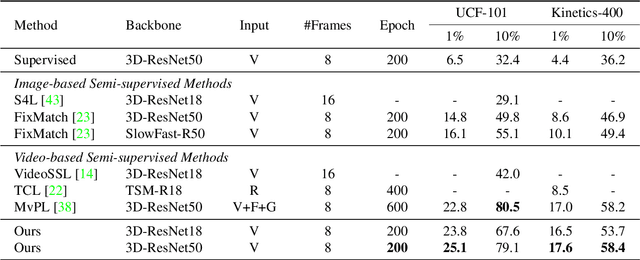
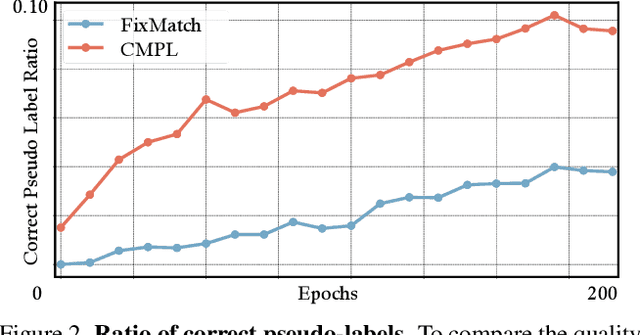
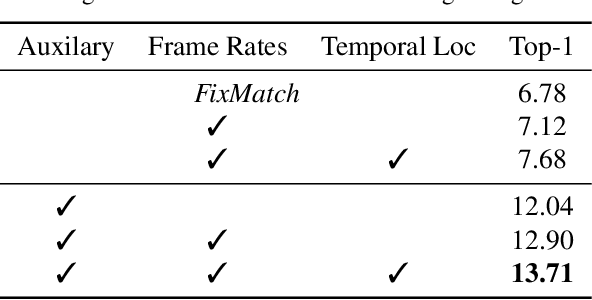
Semi-supervised action recognition is a challenging but important task due to the high cost of data annotation. A common approach to this problem is to assign unlabeled data with pseudo-labels, which are then used as additional supervision in training. Typically in recent work, the pseudo-labels are obtained by training a model on the labeled data, and then using confident predictions from the model to teach itself. In this work, we propose a more effective pseudo-labeling scheme, called Cross-Model Pseudo-Labeling (CMPL). Concretely, we introduce a lightweight auxiliary network in addition to the primary backbone, and ask them to predict pseudo-labels for each other. We observe that, due to their different structural biases, these two models tend to learn complementary representations from the same video clips. Each model can thus benefit from its counterpart by utilizing cross-model predictions as supervision. Experiments on different data partition protocols demonstrate the significant improvement of our framework over existing alternatives. For example, CMPL achieves $17.6\%$ and $25.1\%$ Top-1 accuracy on Kinetics-400 and UCF-101 using only the RGB modality and $1\%$ labeled data, outperforming our baseline model, FixMatch, by $9.0\%$ and $10.3\%$, respectively.
SimIPU: Simple 2D Image and 3D Point Cloud Unsupervised Pre-Training for Spatial-Aware Visual Representations
Dec 09, 2021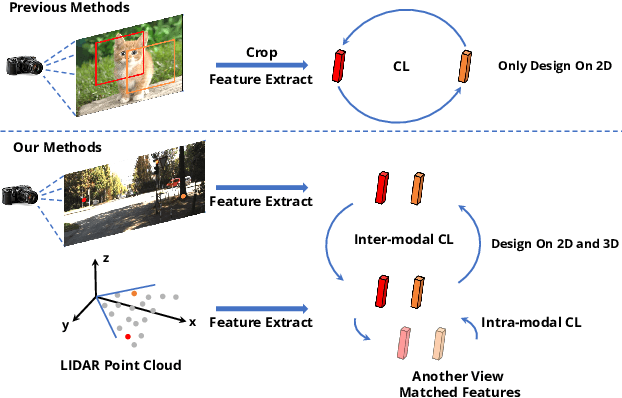
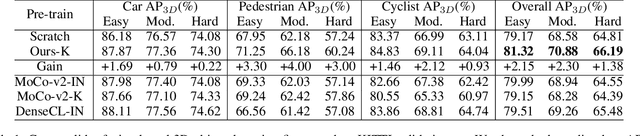
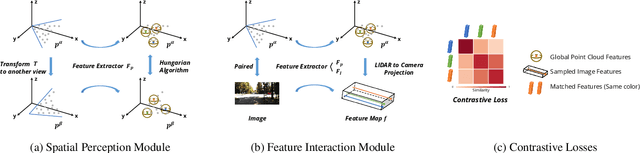

Pre-training has become a standard paradigm in many computer vision tasks. However, most of the methods are generally designed on the RGB image domain. Due to the discrepancy between the two-dimensional image plane and the three-dimensional space, such pre-trained models fail to perceive spatial information and serve as sub-optimal solutions for 3D-related tasks. To bridge this gap, we aim to learn a spatial-aware visual representation that can describe the three-dimensional space and is more suitable and effective for these tasks. To leverage point clouds, which are much more superior in providing spatial information compared to images, we propose a simple yet effective 2D Image and 3D Point cloud Unsupervised pre-training strategy, called SimIPU. Specifically, we develop a multi-modal contrastive learning framework that consists of an intra-modal spatial perception module to learn a spatial-aware representation from point clouds and an inter-modal feature interaction module to transfer the capability of perceiving spatial information from the point cloud encoder to the image encoder, respectively. Positive pairs for contrastive losses are established by the matching algorithm and the projection matrix. The whole framework is trained in an unsupervised end-to-end fashion. To the best of our knowledge, this is the first study to explore contrastive learning pre-training strategies for outdoor multi-modal datasets, containing paired camera images and LIDAR point clouds. Codes and models are available at https://github.com/zhyever/SimIPU.
Improving GAN Equilibrium by Raising Spatial Awareness
Dec 01, 2021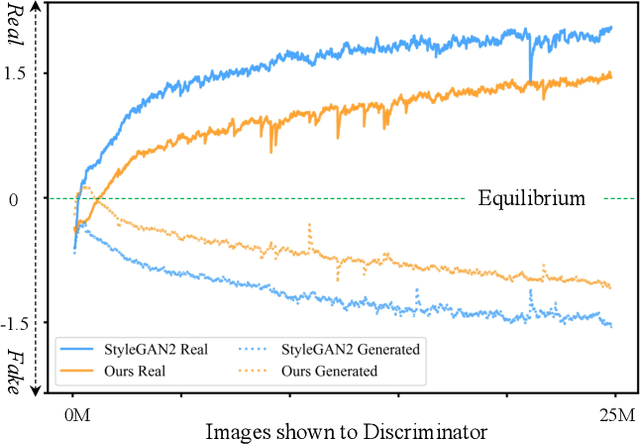
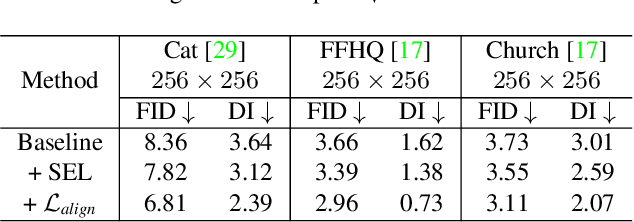
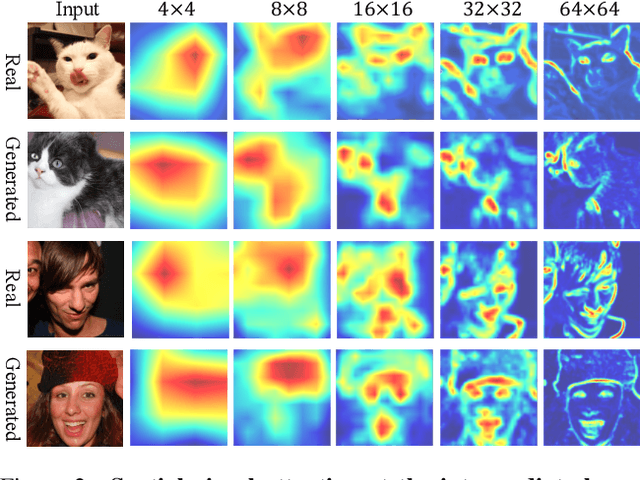

The success of Generative Adversarial Networks (GANs) is largely built upon the adversarial training between a generator (G) and a discriminator (D). They are expected to reach a certain equilibrium where D cannot distinguish the generated images from the real ones. However, in practice it is difficult to achieve such an equilibrium in GAN training, instead, D almost always surpasses G. We attribute this phenomenon to the information asymmetry between D and G. Specifically, we observe that D learns its own visual attention when determining whether an image is real or fake, but G has no explicit clue on which regions to focus on for a particular synthesis. To alleviate the issue of D dominating the competition in GANs, we aim to raise the spatial awareness of G. Randomly sampled multi-level heatmaps are encoded into the intermediate layers of G as an inductive bias. Thus G can purposefully improve the synthesis of certain image regions. We further propose to align the spatial awareness of G with the attention map induced from D. Through this way we effectively lessen the information gap between D and G. Extensive results show that our method pushes the two-player game in GANs closer to the equilibrium, leading to a better synthesis performance. As a byproduct, the introduced spatial awareness facilitates interactive editing over the output synthesis. Demo video and more results are at https://genforce.github.io/eqgan/.
One-Shot Generative Domain Adaptation
Nov 18, 2021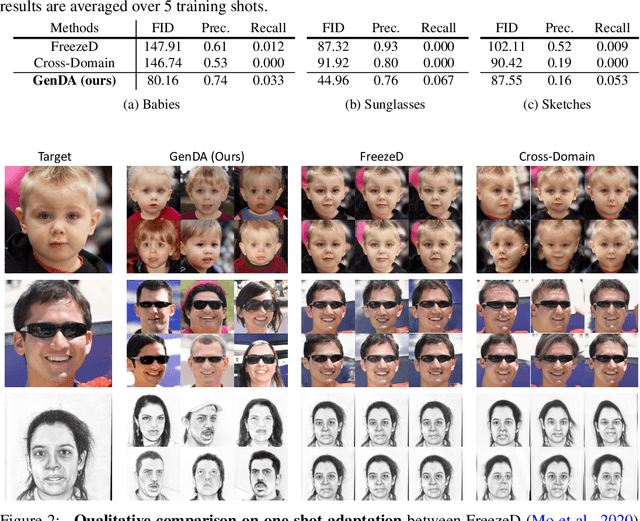
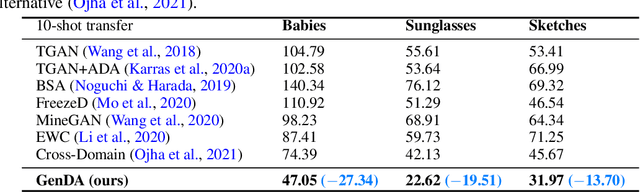


This work aims at transferring a Generative Adversarial Network (GAN) pre-trained on one image domain to a new domain referring to as few as just one target image. The main challenge is that, under limited supervision, it is extremely difficult to synthesize photo-realistic and highly diverse images, while acquiring representative characters of the target. Different from existing approaches that adopt the vanilla fine-tuning strategy, we import two lightweight modules to the generator and the discriminator respectively. Concretely, we introduce an attribute adaptor into the generator yet freeze its original parameters, through which it can reuse the prior knowledge to the most extent and hence maintain the synthesis quality and diversity. We then equip the well-learned discriminator backbone with an attribute classifier to ensure that the generator captures the appropriate characters from the reference. Furthermore, considering the poor diversity of the training data (i.e., as few as only one image), we propose to also constrain the diversity of the generative domain in the training process, alleviating the optimization difficulty. Our approach brings appealing results under various settings, substantially surpassing state-of-the-art alternatives, especially in terms of synthesis diversity. Noticeably, our method works well even with large domain gaps, and robustly converges within a few minutes for each experiment.
Safe Driving via Expert Guided Policy Optimization
Oct 30, 2021
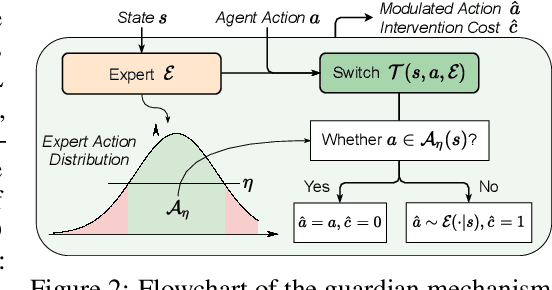
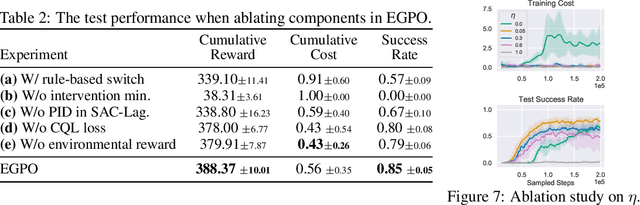

When learning common skills like driving, beginners usually have domain experts standing by to ensure the safety of the learning process. We formulate such learning scheme under the Expert-in-the-loop Reinforcement Learning where a guardian is introduced to safeguard the exploration of the learning agent. While allowing the sufficient exploration in the uncertain environment, the guardian intervenes under dangerous situations and demonstrates the correct actions to avoid potential accidents. Thus ERL enables both exploration and expert's partial demonstration as two training sources. Following such a setting, we develop a novel Expert Guided Policy Optimization (EGPO) method which integrates the guardian in the loop of reinforcement learning. The guardian is composed of an expert policy to generate demonstration and a switch function to decide when to intervene. Particularly, a constrained optimization technique is used to tackle the trivial solution that the agent deliberately behaves dangerously to deceive the expert into taking over. Offline RL technique is further used to learn from the partial demonstration generated by the expert. Safe driving experiments show that our method achieves superior training and test-time safety, outperforms baselines with a substantial margin in sample efficiency, and preserves the generalizabiliy to unseen environments in test-time. Demo video and source code are available at: https://decisionforce.github.io/EGPO/
Learning to Simulate Self-Driven Particles System with Coordinated Policy Optimization
Oct 26, 2021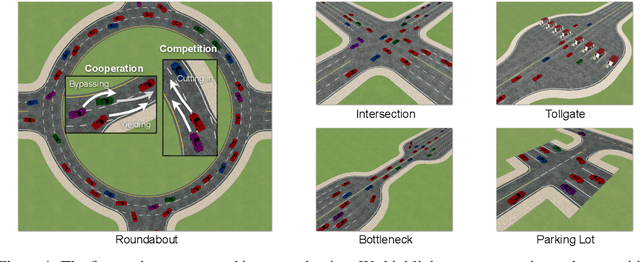
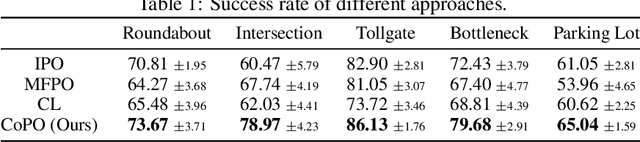
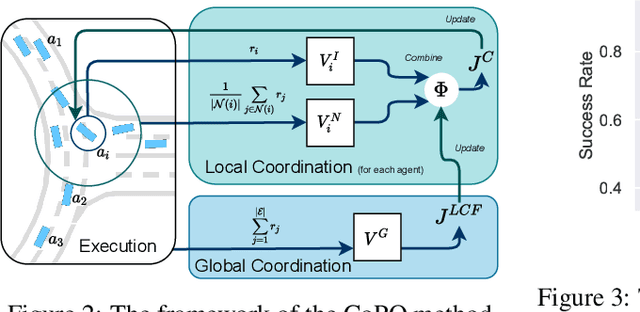

Self-Driven Particles (SDP) describe a category of multi-agent systems common in everyday life, such as flocking birds and traffic flows. In a SDP system, each agent pursues its own goal and constantly changes its cooperative or competitive behaviors with its nearby agents. Manually designing the controllers for such SDP system is time-consuming, while the resulting emergent behaviors are often not realistic nor generalizable. Thus the realistic simulation of SDP systems remains challenging. Reinforcement learning provides an appealing alternative for automating the development of the controller for SDP. However, previous multi-agent reinforcement learning (MARL) methods define the agents to be teammates or enemies before hand, which fail to capture the essence of SDP where the role of each agent varies to be cooperative or competitive even within one episode. To simulate SDP with MARL, a key challenge is to coordinate agents' behaviors while still maximizing individual objectives. Taking traffic simulation as the testing bed, in this work we develop a novel MARL method called Coordinated Policy Optimization (CoPO), which incorporates social psychology principle to learn neural controller for SDP. Experiments show that the proposed method can achieve superior performance compared to MARL baselines in various metrics. Noticeably the trained vehicles exhibit complex and diverse social behaviors that improve performance and safety of the population as a whole. Demo video and source code are available at: https://decisionforce.github.io/CoPO/