 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving GANs with A Dynamic Discriminator
Sep 20, 2022
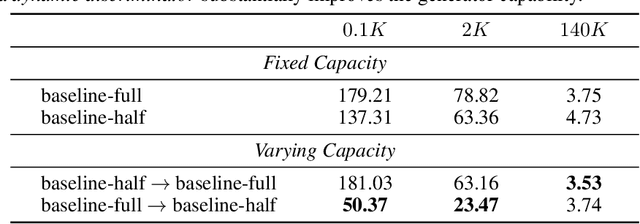

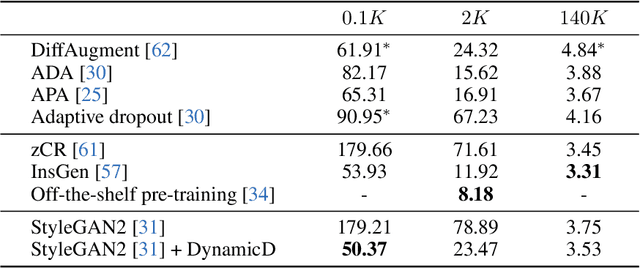
Discriminator plays a vital role in training generative adversarial networks (GANs) via distinguishing real and synthesized samples. While the real data distribution remains the same, the synthesis distribution keeps varying because of the evolving generator, and thus effects a corresponding change to the bi-classification task for the discriminator. We argue that a discriminator with an on-the-fly adjustment on its capacity can better accommodate such a time-varying task. A comprehensive empirical study confirms that the proposed training strategy, termed as DynamicD, improves the synthesis performance without incurring any additional computation cost or training objectives. Two capacity adjusting schemes are developed for training GANs under different data regimes: i) given a sufficient amount of training data, the discriminator benefits from a progressively increased learning capacity, and ii) when the training data is limited, gradually decreasing the layer width mitigates the over-fitting issue of the discriminator. Experiments on both 2D and 3D-aware image synthesis tasks conducted on a range of datasets substantiate the generalizability of our DynamicD as well as its substantial improvement over the baselines. Furthermore, DynamicD is synergistic to other discriminator-improving approaches (including data augmentation, regularizers, and pre-training), and brings continuous performance gain when combined for learning GANs.
Exploiting Reward Shifting in Value-Based Deep RL
Sep 15, 2022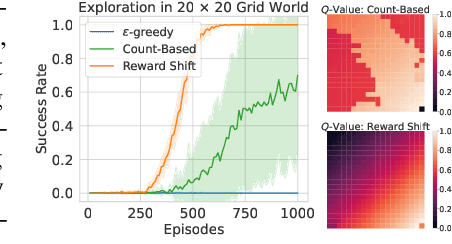
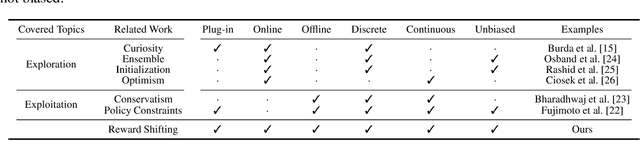

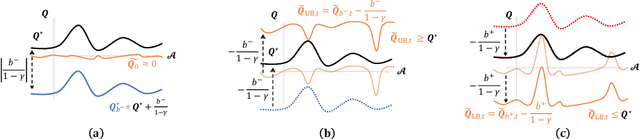
In this work, we study the simple yet universally applicable case of reward shaping in value-based Deep Reinforcement Learning (DRL). We show that reward shifting in the form of the linear transformation is equivalent to changing the initialization of the $Q$-function in function approximation. Based on such an equivalence, we bring the key insight that a positive reward shifting leads to conservative exploitation, while a negative reward shifting leads to curiosity-driven exploration. Accordingly, conservative exploitation improves offline RL value estimation, and optimistic value estimation improves exploration for online RL. We validate our insight on a range of RL tasks and show its improvement over baselines: (1) In offline RL, the conservative exploitation leads to improved performance based on off-the-shelf algorithms; (2) In online continuous control, multiple value functions with different shifting constants can be used to tackle the exploration-exploitation dilemma for better sample efficiency; (3) In discrete control tasks, a negative reward shifting yields an improvement over the curiosity-based exploration method.
CoBEVT: Cooperative Bird's Eye View Semantic Segmentation with Sparse Transformers
Jul 05, 2022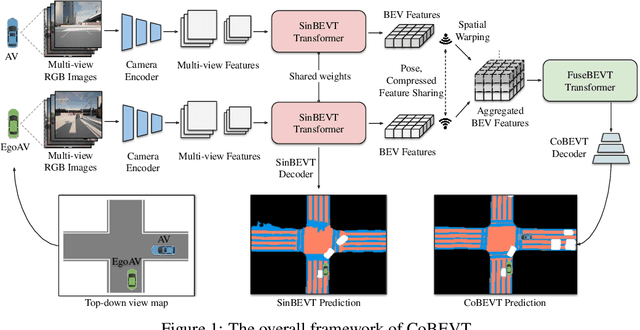

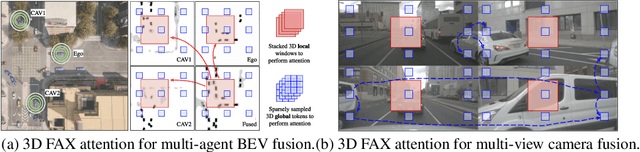
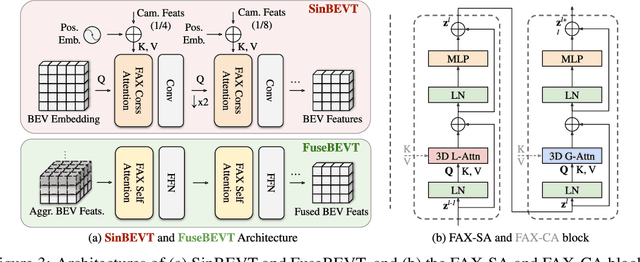
Bird's eye view (BEV) semantic segmentation plays a crucial role in spatial sensing for autonomous driving. Although recent literature has made significant progress on BEV map understanding, they are all based on single-agent camera-based systems which are difficult to handle occlusions and detect distant objects in complex traffic scenes. Vehicle-to-Vehicle (V2V) communication technologies have enabled autonomous vehicles to share sensing information, which can dramatically improve the perception performance and range as compared to single-agent systems. In this paper, we propose CoBEVT, the first generic multi-agent multi-camera perception framework that can cooperatively generate BEV map predictions. To efficiently fuse camera features from multi-view and multi-agent data in an underlying Transformer architecture, we design a fused axial attention or FAX module, which can capture sparsely local and global spatial interactions across views and agents. The extensive experiments on the V2V perception dataset, OPV2V, demonstrate that CoBEVT achieves state-of-the-art performance for cooperative BEV semantic segmentation. Moreover, CoBEVT is shown to be generalizable to other tasks, including 1) BEV segmentation with single-agent multi-camera and 2) 3D object detection with multi-agent LiDAR systems, and achieves state-of-the-art performance with real-time inference speed.
Human-AI Shared Control via Frequency-based Policy Dissection
May 31, 2022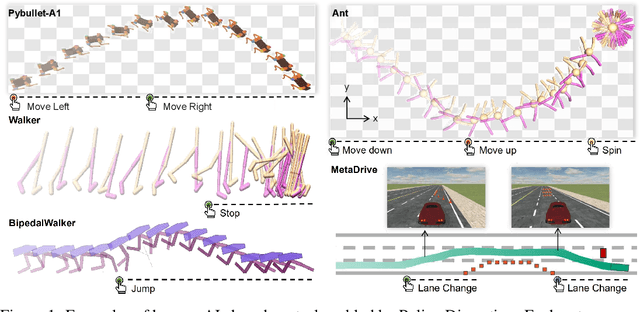
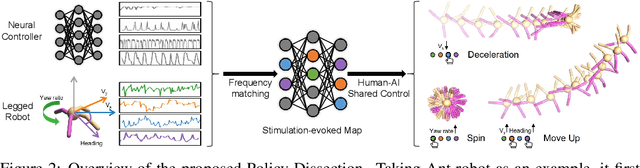

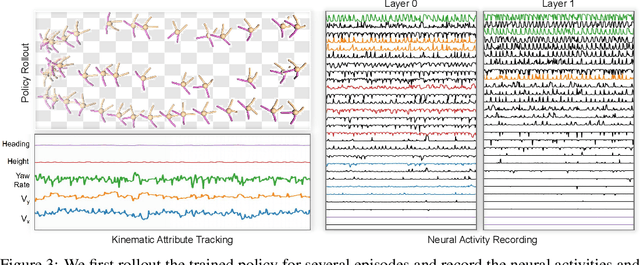
Human-AI shared control allows human to interact and collaborate with AI to accomplish control tasks in complex environments. Previous Reinforcement Learning (RL) methods attempt the goal-conditioned design to achieve human-controllable policies at the cost of redesigning the reward function and training paradigm. Inspired by the neuroscience approach to investigate the motor cortex in primates, we develop a simple yet effective frequency-based approach called \textit{Policy Dissection} to align the intermediate representation of the learned neural controller with the kinematic attributes of the agent behavior. Without modifying the neural controller or retraining the model, the proposed approach can convert a given RL-trained policy into a human-interactive policy. We evaluate the proposed approach on the RL tasks of autonomous driving and locomotion. The experiments show that human-AI shared control achieved by Policy Dissection in driving task can substantially improve the performance and safety in unseen traffic scenes. With human in the loop, the locomotion robots also exhibit versatile controllable motion skills even though they are only trained to move forward. Our results suggest the promising direction of implementing human-AI shared autonomy through interpreting the learned representation of the autonomous agents. Demo video and code will be made available at https://metadriverse.github.io/policydissect.
Action-Conditioned Contrastive Policy Pretraining
Apr 05, 2022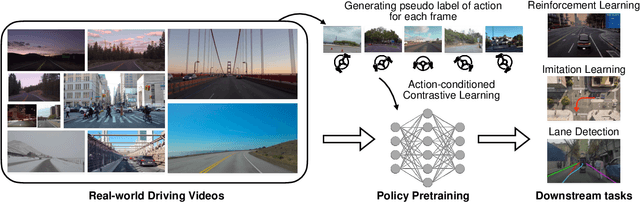
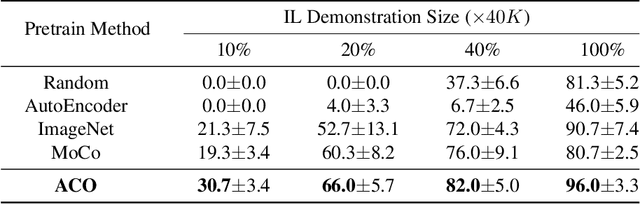
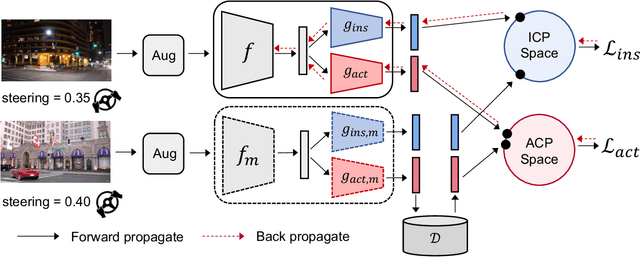
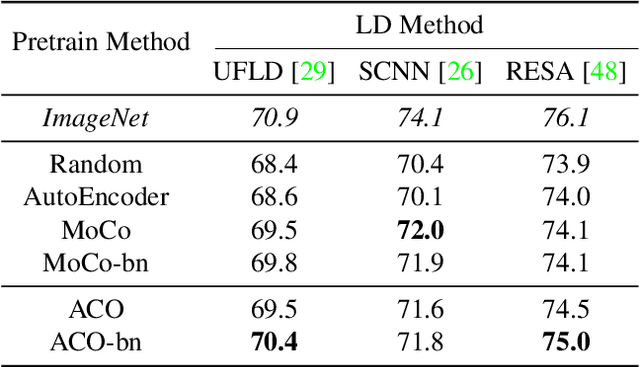
Deep visuomotor policy learning achieves promising results in control tasks such as robotic manipulation and autonomous driving, where the action is generated from the visual input by the neural policy. However, it requires a huge number of online interactions with the training environment, which limits its real-world application. Compared to the popular unsupervised feature learning for visual recognition, feature pretraining for visuomotor control tasks is much less explored. In this work, we aim to pretrain policy representations for driving tasks using hours-long uncurated YouTube videos. A new contrastive policy pretraining method is developed to learn action-conditioned features from video frames with action pseudo labels. Experiments show that the resulting action-conditioned features bring substantial improvements to the downstream reinforcement learning and imitation learning tasks, outperforming the weights pretrained from previous unsupervised learning methods. Code and models will be made publicly available.
Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation
Mar 24, 2022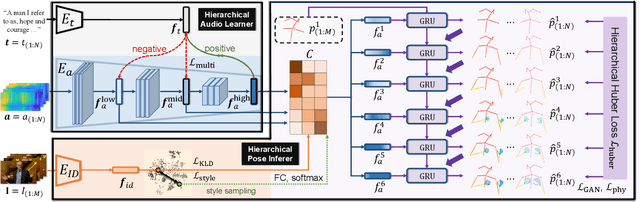
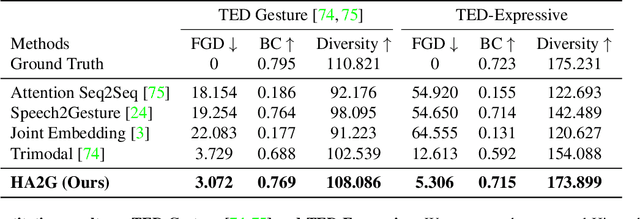
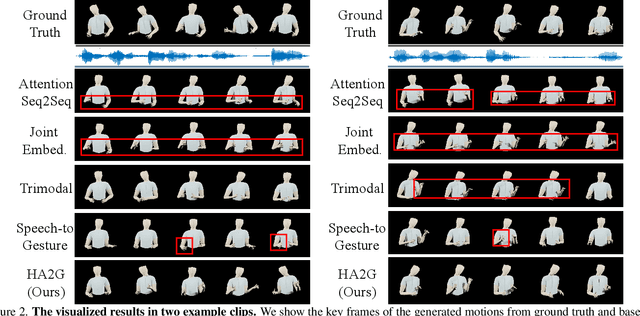

Generating speech-consistent body and gesture movements is a long-standing problem in virtual avatar creation. Previous studies often synthesize pose movement in a holistic manner, where poses of all joints are generated simultaneously. Such a straightforward pipeline fails to generate fine-grained co-speech gestures. One observation is that the hierarchical semantics in speech and the hierarchical structures of human gestures can be naturally described into multiple granularities and associated together. To fully utilize the rich connections between speech audio and human gestures, we propose a novel framework named Hierarchical Audio-to-Gesture (HA2G) for co-speech gesture generation. In HA2G, a Hierarchical Audio Learner extracts audio representations across semantic granularities. A Hierarchical Pose Inferer subsequently renders the entire human pose gradually in a hierarchical manner. To enhance the quality of synthesized gestures, we develop a contrastive learning strategy based on audio-text alignment for better audio representations. Extensive experiments and human evaluation demonstrate that the proposed method renders realistic co-speech gestures and outperforms previous methods in a clear margin. Project page: https://alvinliu0.github.io/projects/HA2G
LocATe: End-to-end Localization of Actions in 3D with Transformers
Mar 21, 2022

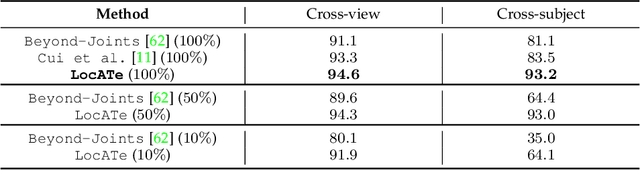
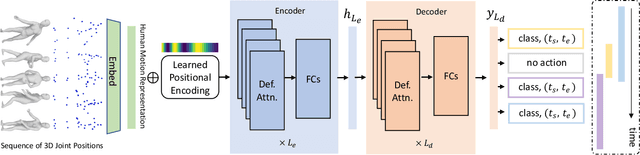
Understanding a person's behavior from their 3D motion is a fundamental problem in computer vision with many applications. An important component of this problem is 3D Temporal Action Localization (3D-TAL), which involves recognizing what actions a person is performing, and when. State-of-the-art 3D-TAL methods employ a two-stage approach in which the action span detection task and the action recognition task are implemented as a cascade. This approach, however, limits the possibility of error-correction. In contrast, we propose LocATe, an end-to-end approach that jointly localizes and recognizes actions in a 3D sequence. Further, unlike existing autoregressive models that focus on modeling the local context in a sequence, LocATe's transformer model is capable of capturing long-term correlations between actions in a sequence. Unlike transformer-based object-detection and classification models which consider image or patch features as input, the input in 3D-TAL is a long sequence of highly correlated frames. To handle the high-dimensional input, we implement an effective input representation, and overcome the diffuse attention across long time horizons by introducing sparse attention in the model. LocATe outperforms previous approaches on the existing PKU-MMD 3D-TAL benchmark (mAP=93.2%). Finally, we argue that benchmark datasets are most useful where there is clear room for performance improvement. To that end, we introduce a new, challenging, and more realistic benchmark dataset, BABEL-TAL-20 (BT20), where the performance of state-of-the-art methods is significantly worse. The dataset and code for the method will be available for research purposes.
Efficient Learning of Safe Driving Policy via Human-AI Copilot Optimization
Feb 17, 2022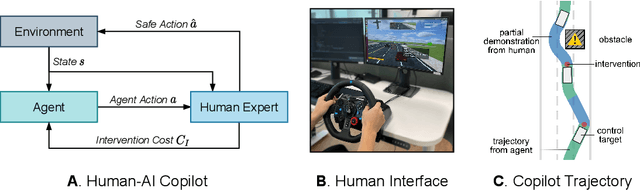
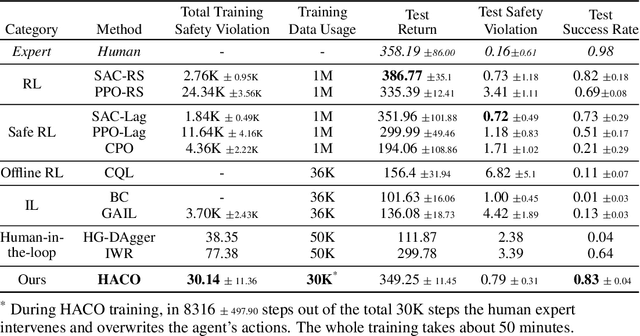

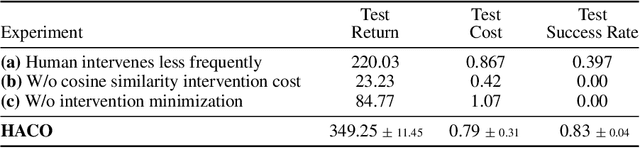
Human intervention is an effective way to inject human knowledge into the training loop of reinforcement learning, which can bring fast learning and ensured training safety. Given the very limited budget of human intervention, it remains challenging to design when and how human expert interacts with the learning agent in the training. In this work, we develop a novel human-in-the-loop learning method called Human-AI Copilot Optimization (HACO).To allow the agent's sufficient exploration in the risky environments while ensuring the training safety, the human expert can take over the control and demonstrate how to avoid probably dangerous situations or trivial behaviors. The proposed HACO then effectively utilizes the data both from the trial-and-error exploration and human's partial demonstration to train a high-performing agent. HACO extracts proxy state-action values from partial human demonstration and optimizes the agent to improve the proxy values meanwhile reduce the human interventions. The experiments show that HACO achieves a substantially high sample efficiency in the safe driving benchmark. HACO can train agents to drive in unseen traffic scenarios with a handful of human intervention budget and achieve high safety and generalizability, outperforming both reinforcement learning and imitation learning baselines with a large margin. Code and demo videos are available at: https://decisionforce.github.io/HACO/.
Visual Sound Localization in the Wild by Cross-Modal Interference Erasing
Feb 13, 2022
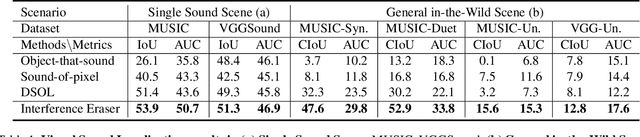
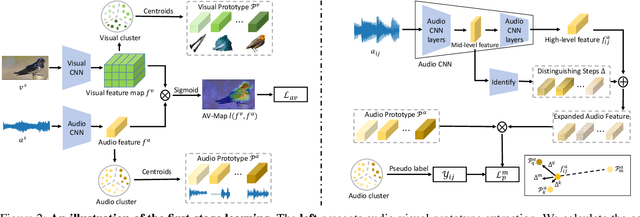

The task of audio-visual sound source localization has been well studied under constrained scenes, where the audio recordings are clean. However, in real-world scenarios, audios are usually contaminated by off-screen sound and background noise. They will interfere with the procedure of identifying desired sources and building visual-sound connections, making previous studies non-applicable. In this work, we propose the Interference Eraser (IEr) framework, which tackles the problem of audio-visual sound source localization in the wild. The key idea is to eliminate the interference by redefining and carving discriminative audio representations. Specifically, we observe that the previous practice of learning only a single audio representation is insufficient due to the additive nature of audio signals. We thus extend the audio representation with our Audio-Instance-Identifier module, which clearly distinguishes sounding instances when audio signals of different volumes are unevenly mixed. Then we erase the influence of the audible but off-screen sounds and the silent but visible objects by a Cross-modal Referrer module with cross-modality distillation. Quantitative and qualitative evaluations demonstrate that our proposed framework achieves superior results on sound localization tasks, especially under real-world scenarios. Code is available at https://github.com/alvinliu0/Visual-Sound-Localization-in-the-Wild.
Semantic-Aware Implicit Neural Audio-Driven Video Portrait Generation
Jan 19, 2022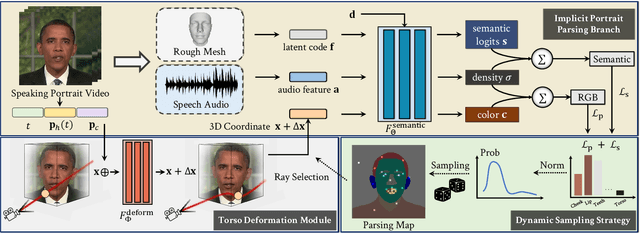
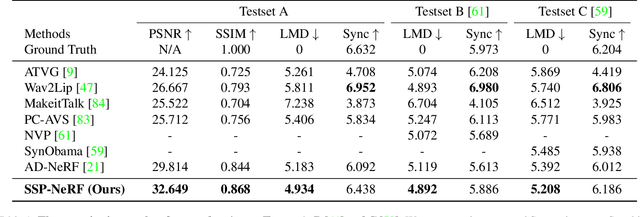
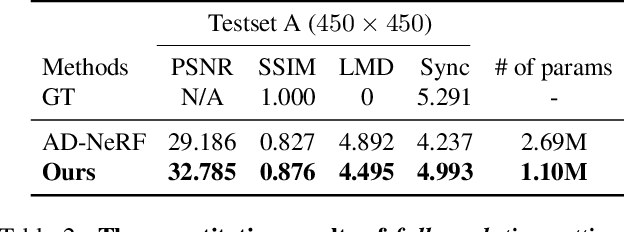

Animating high-fidelity video portrait with speech audio is crucial for virtual reality and digital entertainment. While most previous studies rely on accurate explicit structural information, recent works explore the implicit scene representation of Neural Radiance Fields (NeRF) for realistic generation. In order to capture the inconsistent motions as well as the semantic difference between human head and torso, some work models them via two individual sets of NeRF, leading to unnatural results. In this work, we propose Semantic-aware Speaking Portrait NeRF (SSP-NeRF), which creates delicate audio-driven portraits using one unified set of NeRF. The proposed model can handle the detailed local facial semantics and the global head-torso relationship through two semantic-aware modules. Specifically, we first propose a Semantic-Aware Dynamic Ray Sampling module with an additional parsing branch that facilitates audio-driven volume rendering. Moreover, to enable portrait rendering in one unified neural radiance field, a Torso Deformation module is designed to stabilize the large-scale non-rigid torso motions. Extensive evaluations demonstrate that our proposed approach renders more realistic video portraits compared to previous methods. Project page: https://alvinliu0.github.io/projects/SSP-NeRF