 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext Steps for Human-Centered Generative AI: A Technical Perspective
Jun 27, 2023



Through iterative, cross-disciplinary discussions, we define and propose next-steps for Human-centered Generative AI (HGAI) from a technical perspective. We contribute a roadmap that lays out future directions of Generative AI spanning three levels: Aligning with human values; Accommodating humans' expression of intents; and Augmenting humans' abilities in a collaborative workflow. This roadmap intends to draw interdisciplinary research teams to a comprehensive list of emergent ideas in HGAI, identifying their interested topics while maintaining a coherent big picture of the future work landscape.
V2V4Real: A Real-world Large-scale Dataset for Vehicle-to-Vehicle Cooperative Perception
Mar 19, 2023



Modern perception systems of autonomous vehicles are known to be sensitive to occlusions and lack the capability of long perceiving range. It has been one of the key bottlenecks that prevents Level 5 autonomy. Recent research has demonstrated that the Vehicle-to-Vehicle (V2V) cooperative perception system has great potential to revolutionize the autonomous driving industry. However, the lack of a real-world dataset hinders the progress of this field. To facilitate the development of cooperative perception, we present V2V4Real, the first large-scale real-world multi-modal dataset for V2V perception. The data is collected by two vehicles equipped with multi-modal sensors driving together through diverse scenarios. Our V2V4Real dataset covers a driving area of 410 km, comprising 20K LiDAR frames, 40K RGB frames, 240K annotated 3D bounding boxes for 5 classes, and HDMaps that cover all the driving routes. V2V4Real introduces three perception tasks, including cooperative 3D object detection, cooperative 3D object tracking, and Sim2Real domain adaptation for cooperative perception. We provide comprehensive benchmarks of recent cooperative perception algorithms on three tasks. The V2V4Real dataset can be found at https://research.seas.ucla.edu/mobility-lab/v2v4real/.
Guarded Policy Optimization with Imperfect Online Demonstrations
Mar 03, 2023The Teacher-Student Framework (TSF) is a reinforcement learning setting where a teacher agent guards the training of a student agent by intervening and providing online demonstrations. Assuming optimal, the teacher policy has the perfect timing and capability to intervene in the learning process of the student agent, providing safety guarantee and exploration guidance. Nevertheless, in many real-world settings it is expensive or even impossible to obtain a well-performing teacher policy. In this work, we relax the assumption of a well-performing teacher and develop a new method that can incorporate arbitrary teacher policies with modest or inferior performance. We instantiate an Off-Policy Reinforcement Learning algorithm, termed Teacher-Student Shared Control (TS2C), which incorporates teacher intervention based on trajectory-based value estimation. Theoretical analysis validates that the proposed TS2C algorithm attains efficient exploration and substantial safety guarantee without being affected by the teacher's own performance. Experiments on various continuous control tasks show that our method can exploit teacher policies at different performance levels while maintaining a low training cost. Moreover, the student policy surpasses the imperfect teacher policy in terms of higher accumulated reward in held-out testing environments. Code is available at https://metadriverse.github.io/TS2C.
Spatial Steerability of GANs via Self-Supervision from Discriminator
Jan 20, 2023Generative models make huge progress to the photorealistic image synthesis in recent years. To enable human to steer the image generation process and customize the output, many works explore the interpretable dimensions of the latent space in GANs. Existing methods edit the attributes of the output image such as orientation or color scheme by varying the latent code along certain directions. However, these methods usually require additional human annotations for each pretrained model, and they mostly focus on editing global attributes. In this work, we propose a self-supervised approach to improve the spatial steerability of GANs without searching for steerable directions in the latent space or requiring extra annotations. Specifically, we design randomly sampled Gaussian heatmaps to be encoded into the intermediate layers of generative models as spatial inductive bias. Along with training the GAN model from scratch, these heatmaps are being aligned with the emerging attention of the GAN's discriminator in a self-supervised learning manner. During inference, human users can intuitively interact with the spatial heatmaps to edit the output image, such as varying the scene layout or moving objects in the scene. Extensive experiments show that the proposed method not only enables spatial editing over human faces, animal faces, outdoor scenes, and complicated indoor scenes, but also brings improvement in synthesis quality.
Street-View Image Generation from a Bird's-Eye View Layout
Jan 16, 2023

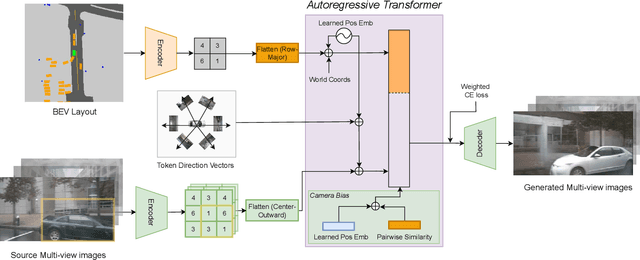

Bird's-Eye View (BEV) Perception has received increasing attention in recent years as it provides a concise and unified spatial representation across views and benefits a diverse set of downstream driving applications. While the focus has been placed on discriminative tasks such as BEV segmentation, the dual generative task of creating street-view images from a BEV layout has rarely been explored. The ability to generate realistic street-view images that align with a given HD map and traffic layout is critical for visualizing complex traffic scenarios and developing robust perception models for autonomous driving. In this paper, we propose BEVGen, a conditional generative model that synthesizes a set of realistic and spatially consistent surrounding images that match the BEV layout of a traffic scenario. BEVGen incorporates a novel cross-view transformation and spatial attention design which learn the relationship between cameras and map views to ensure their consistency. Our model can accurately render road and lane lines, as well as generate traffic scenes under different weather conditions and times of day. The code will be made publicly available.
GH-Feat: Learning Versatile Generative Hierarchical Features from GANs
Jan 12, 2023Recent years witness the tremendous success of generative adversarial networks (GANs) in synthesizing photo-realistic images. GAN generator learns to compose realistic images and reproduce the real data distribution. Through that, a hierarchical visual feature with multi-level semantics spontaneously emerges. In this work we investigate that such a generative feature learned from image synthesis exhibits great potentials in solving a wide range of computer vision tasks, including both generative ones and more importantly discriminative ones. We first train an encoder by considering the pretrained StyleGAN generator as a learned loss function. The visual features produced by our encoder, termed as Generative Hierarchical Features (GH-Feat), highly align with the layer-wise GAN representations, and hence describe the input image adequately from the reconstruction perspective. Extensive experiments support the versatile transferability of GH-Feat across a range of applications, such as image editing, image processing, image harmonization, face verification, landmark detection, layout prediction, image retrieval, etc. We further show that, through a proper spatial expansion, our developed GH-Feat can also facilitate fine-grained semantic segmentation using only a few annotations. Both qualitative and quantitative results demonstrate the appealing performance of GH-Feat.
DisCoScene: Spatially Disentangled Generative Radiance Fields for Controllable 3D-aware Scene Synthesis
Dec 22, 2022Existing 3D-aware image synthesis approaches mainly focus on generating a single canonical object and show limited capacity in composing a complex scene containing a variety of objects. This work presents DisCoScene: a 3Daware generative model for high-quality and controllable scene synthesis. The key ingredient of our method is a very abstract object-level representation (i.e., 3D bounding boxes without semantic annotation) as the scene layout prior, which is simple to obtain, general to describe various scene contents, and yet informative to disentangle objects and background. Moreover, it serves as an intuitive user control for scene editing. Based on such a prior, the proposed model spatially disentangles the whole scene into object-centric generative radiance fields by learning on only 2D images with the global-local discrimination. Our model obtains the generation fidelity and editing flexibility of individual objects while being able to efficiently compose objects and the background into a complete scene. We demonstrate state-of-the-art performance on many scene datasets, including the challenging Waymo outdoor dataset. Project page: https://snap-research.github.io/discoscene/
Towards Smooth Video Composition
Dec 14, 2022Video generation requires synthesizing consistent and persistent frames with dynamic content over time. This work investigates modeling the temporal relations for composing video with arbitrary length, from a few frames to even infinite, using generative adversarial networks (GANs). First, towards composing adjacent frames, we show that the alias-free operation for single image generation, together with adequately pre-learned knowledge, brings a smooth frame transition without compromising the per-frame quality. Second, by incorporating the temporal shift module (TSM), originally designed for video understanding, into the discriminator, we manage to advance the generator in synthesizing more consistent dynamics. Third, we develop a novel B-Spline based motion representation to ensure temporal smoothness to achieve infinite-length video generation. It can go beyond the frame number used in training. A low-rank temporal modulation is also proposed to alleviate repeating contents for long video generation. We evaluate our approach on various datasets and show substantial improvements over video generation baselines. Code and models will be publicly available at https://genforce.github.io/StyleSV.
TrafficGen: Learning to Generate Diverse and Realistic Traffic Scenarios
Oct 12, 2022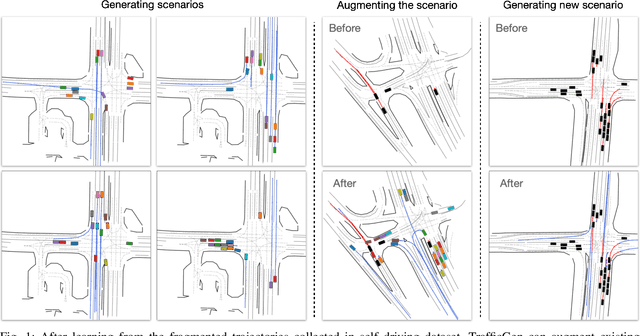
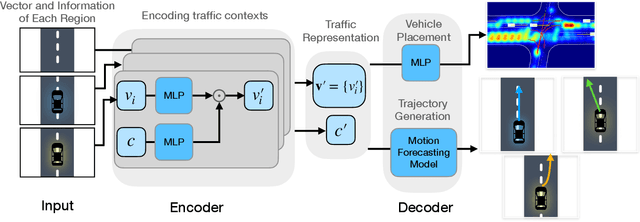
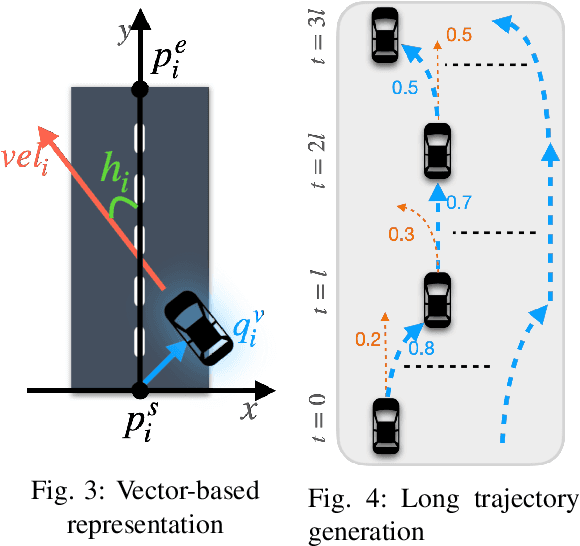
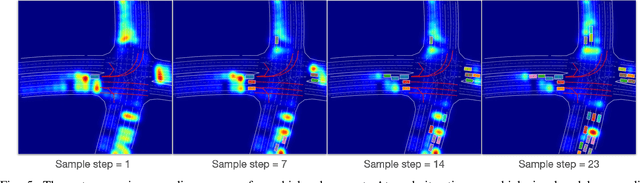
Diverse and realistic traffic scenarios are crucial for evaluating the AI safety of autonomous driving systems in simulation. This work introduces a data-driven method called TrafficGen for traffic scenario generation. It learns from the fragmented human driving data collected in the real world and then can generate realistic traffic scenarios. TrafficGen is an autoregressive generative model with an encoder-decoder architecture. In each autoregressive iteration, it first encodes the current traffic context with the attention mechanism and then decodes a vehicle's initial state followed by generating its long trajectory. We evaluate the trained model in terms of vehicle placement and trajectories and show substantial improvements over baselines. TrafficGen can be also used to augment existing traffic scenarios, by adding new vehicles and extending the fragmented trajectories. We further demonstrate that importing the generated scenarios into a simulator as interactive training environments improves the performance and the safety of driving policy learned from reinforcement learning. More project resource is available at https://metadriverse.github.io/trafficgen
V2XP-ASG: Generating Adversarial Scenes for Vehicle-to-Everything Perception
Sep 27, 2022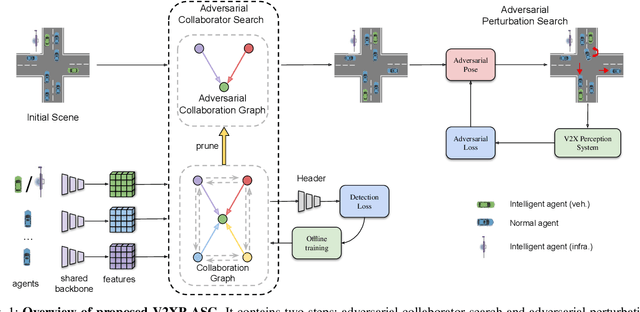
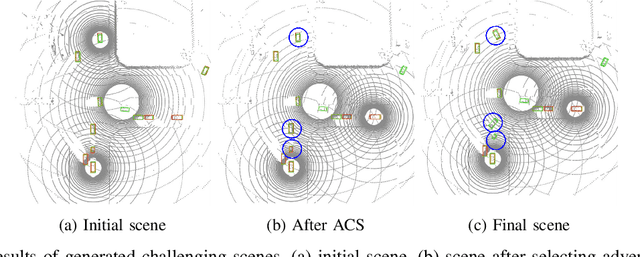
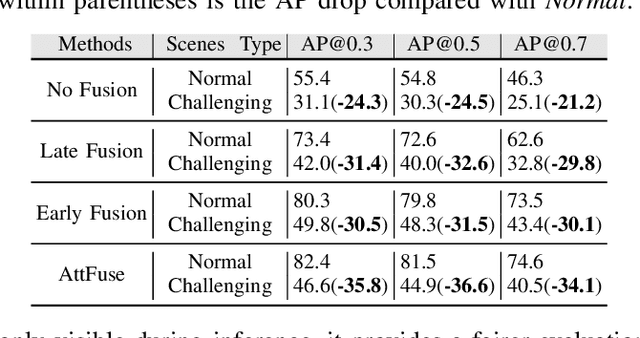

Recent advancements in Vehicle-to-Everything communication technology have enabled autonomous vehicles to share sensory information to obtain better perception performance. With the rapid growth of autonomous vehicles and intelligent infrastructure, the V2X perception systems will soon be deployed at scale, which raises a safety-critical question: how can we evaluate and improve its performance under challenging traffic scenarios before the real-world deployment? Collecting diverse large-scale real-world test scenes seems to be the most straightforward solution, but it is expensive and time-consuming, and the collections can only cover limited scenarios. To this end, we propose the first open adversarial scene generator V2XP-ASG that can produce realistic, challenging scenes for modern LiDAR-based multi-agent perception system. V2XP-ASG learns to construct an adversarial collaboration graph and simultaneously perturb multiple agents' poses in an adversarial and plausible manner. The experiments demonstrate that V2XP-ASG can effectively identify challenging scenes for a large range of V2X perception systems. Meanwhile, by training on the limited number of generated challenging scenes, the accuracy of V2X perception systems can be further improved by 12.3% on challenging and 4% on normal scenes.