 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI as intermediary in modern-day ritual: An immersive, interactive production of the roller disco musical Xanadu at UCLA
Nov 09, 2025Interfaces for contemporary large language, generative media, and perception AI models are often engineered for single user interaction. We investigate ritual as a design scaffold for developing collaborative, multi-user human-AI engagement. We consider the specific case of an immersive staging of the musical Xanadu performed at UCLA in Spring 2025. During a two-week run, over five hundred audience members contributed sketches and jazzercise moves that vision language models translated to virtual scenery elements and from choreographic prompts. This paper discusses four facets of interaction-as-ritual within the show: audience input as offerings that AI transforms into components of the ritual; performers as ritual guides, demonstrating how to interact with technology and sorting audience members into cohorts; AI systems as instruments "played" by the humans, in which sensing, generative components, and stagecraft create systems that can be mastered over time; and reciprocity of interaction, in which the show's AI machinery guides human behavior as well as being guided by humans, completing a human-AI feedback loop that visibly reshapes the virtual world. Ritual served as a frame for integrating linear narrative, character identity, music and interaction. The production explored how AI systems can support group creativity and play, addressing a critical gap in prevailing single user AI design paradigms.
Next Steps for Human-Centered Generative AI: A Technical Perspective
Jun 27, 2023



Through iterative, cross-disciplinary discussions, we define and propose next-steps for Human-centered Generative AI (HGAI) from a technical perspective. We contribute a roadmap that lays out future directions of Generative AI spanning three levels: Aligning with human values; Accommodating humans' expression of intents; and Augmenting humans' abilities in a collaborative workflow. This roadmap intends to draw interdisciplinary research teams to a comprehensive list of emergent ideas in HGAI, identifying their interested topics while maintaining a coherent big picture of the future work landscape.
Real-time marker-less multi-person 3D pose estimation in RGB-Depth camera networks
Oct 17, 2017
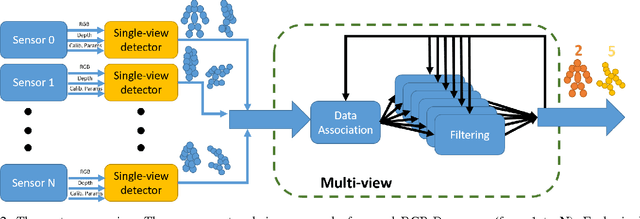
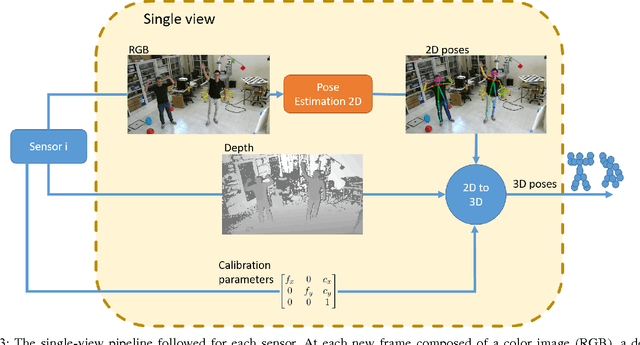
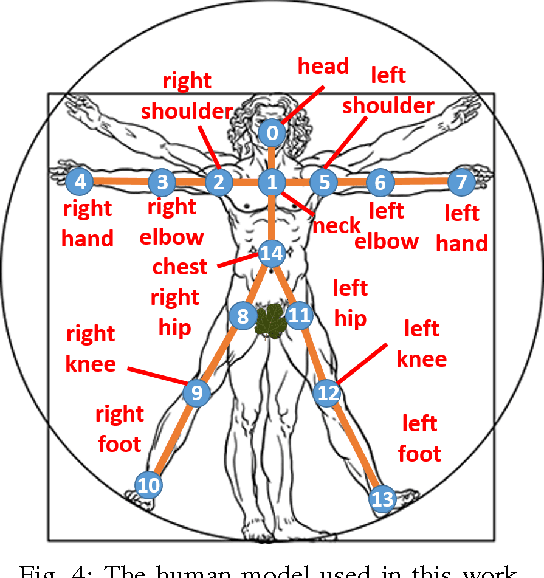
This paper proposes a novel system to estimate and track the 3D poses of multiple persons in calibrated RGB-Depth camera networks. The multi-view 3D pose of each person is computed by a central node which receives the single-view outcomes from each camera of the network. Each single-view outcome is computed by using a CNN for 2D pose estimation and extending the resulting skeletons to 3D by means of the sensor depth. The proposed system is marker-less, multi-person, independent of background and does not make any assumption on people appearance and initial pose. The system provides real-time outcomes, thus being perfectly suited for applications requiring user interaction. Experimental results show the effectiveness of this work with respect to a baseline multi-view approach in different scenarios. To foster research and applications based on this work, we released the source code in OpenPTrack, an open source project for RGB-D people tracking.