 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Landmark Learning from Unpaired Data
Jun 29, 2020
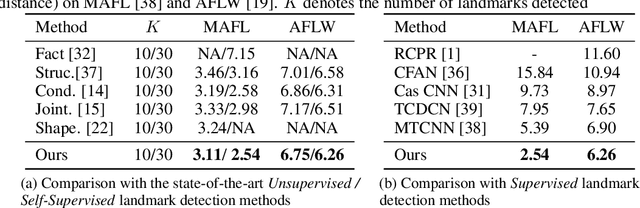
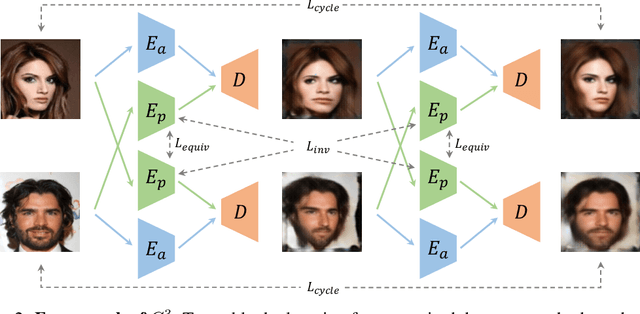
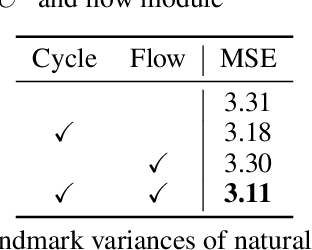
Recent attempts for unsupervised landmark learning leverage synthesized image pairs that are similar in appearance but different in poses. These methods learn landmarks by encouraging the consistency between the original images and the images reconstructed from swapped appearances and poses. While synthesized image pairs are created by applying pre-defined transformations, they can not fully reflect the real variances in both appearances and poses. In this paper, we aim to open the possibility of learning landmarks on unpaired data (i.e. unaligned image pairs) sampled from a natural image collection, so that they can be different in both appearances and poses. To this end, we propose a cross-image cycle consistency framework ($C^3$) which applies the swapping-reconstruction strategy twice to obtain the final supervision. Moreover, a cross-image flow module is further introduced to impose the equivariance between estimated landmarks across images. Through comprehensive experiments, our proposed framework is shown to outperform strong baselines by a large margin. Besides quantitative results, we also provide visualization and interpretation on our learned models, which not only verifies the effectiveness of the learned landmarks, but also leads to important insights that are beneficial for future research.
Video Representation Learning with Visual Tempo Consistency
Jun 28, 2020
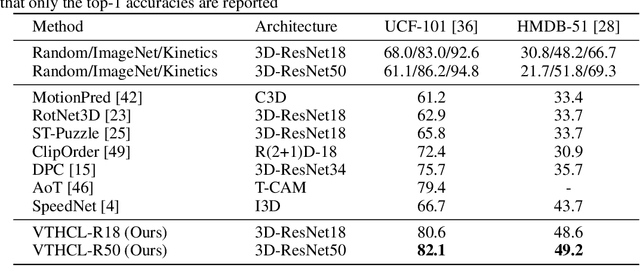


Visual tempo, which describes how fast an action goes, has shown its potential in supervised action recognition. In this work, we demonstrate that visual tempo can also serve as a self-supervision signal for video representation learning. We propose to maximize the mutual information between representations of slow and fast videos via hierarchical contrastive learning (VTHCL). Specifically, by sampling the same instance at slow and fast frame rates respectively, we can obtain slow and fast video frames which share the same semantics but contain different visual tempos. Video representations learned from VTHCL achieve the competitive performances under the self-supervision evaluation protocol for action recognition on UCF-101 (82.1\%) and HMDB-51 (49.2\%). Moreover, we show that the learned representations are also generalized well to other downstream tasks including action detection on AVA and action anticipation on Epic-Kitchen. Finally, our empirical analysis suggests that a more thorough evaluation protocol is needed to verify the effectiveness of the self-supervised video representations across network structures and downstream tasks.
Non-local Policy Optimization via Diversity-regularized Collaborative Exploration
Jun 14, 2020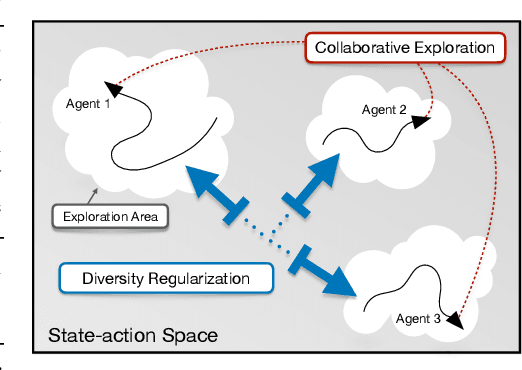
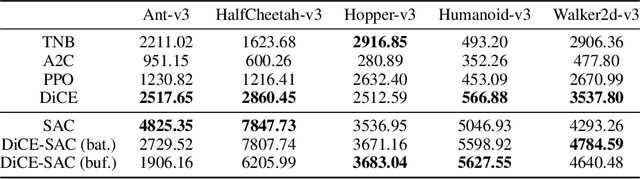
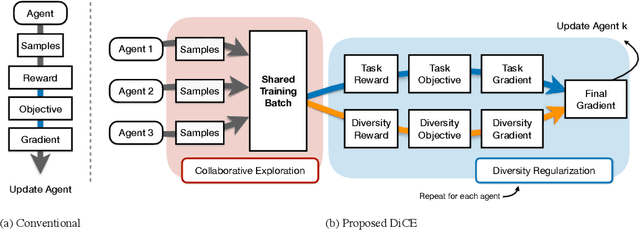
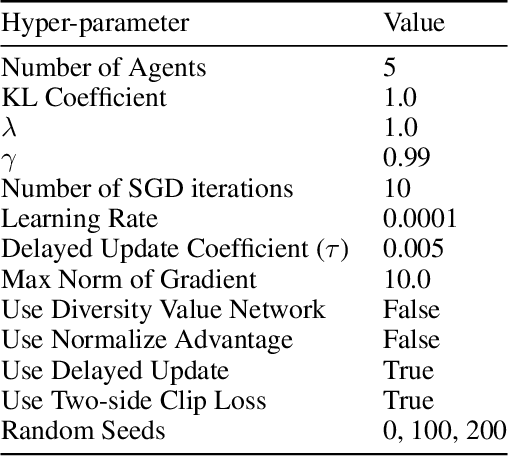
Conventional Reinforcement Learning (RL) algorithms usually have one single agent learning to solve the task independently. As a result, the agent can only explore a limited part of the state-action space while the learned behavior is highly correlated to the agent's previous experience, making the training prone to a local minimum. In this work, we empower RL with the capability of teamwork and propose a novel non-local policy optimization framework called Diversity-regularized Collaborative Exploration (DiCE). DiCE utilizes a group of heterogeneous agents to explore the environment simultaneously and share the collected experiences. A regularization mechanism is further designed to maintain the diversity of the team and modulate the exploration. We implement the framework in both on-policy and off-policy settings and the experimental results show that DiCE can achieve substantial improvement over the baselines in the MuJoCo locomotion tasks.
Zeroth-Order Supervised Policy Improvement
Jun 11, 2020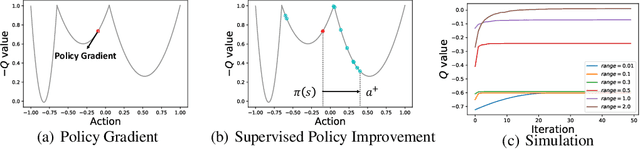
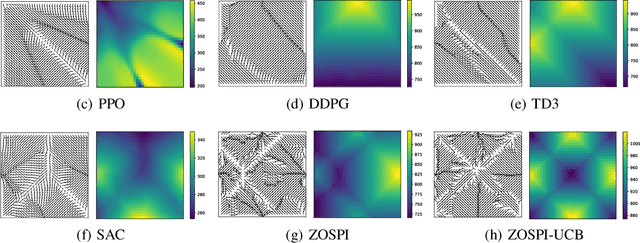
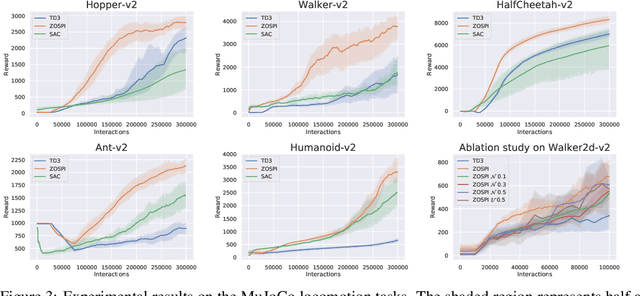
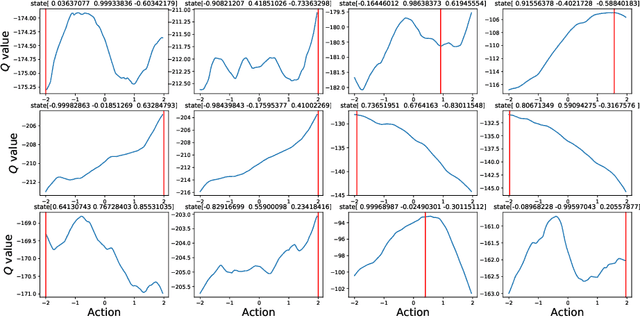
Despite the remarkable progress made by the policy gradient algorithms in reinforcement learning (RL), sub-optimal policies usually result from the local exploration property of the policy gradient update. In this work, we propose a method referred to as Zeroth-Order Supervised Policy Improvement (ZOSPI) that exploits the estimated value function Q globally while preserves the local exploitation of the policy gradient methods. We prove that with a good function structure, the zeroth-order optimization strategy combining both local and global samplings can find the global minima within a polynomial number of samples. To improve the exploration efficiency in unknown environments, ZOSPI is further combined with bootstrapped Q networks. Different from the standard policy gradient methods, the policy learning of ZOSPI is conducted in a self-supervision manner so that the policy can be implemented with gradient-free non-parametric models besides the neural network approximator. Experiments show that ZOSPI achieves competitive results on MuJoCo locomotion tasks with a remarkable sample efficiency.
Novel Policy Seeking with Constrained Optimization
May 21, 2020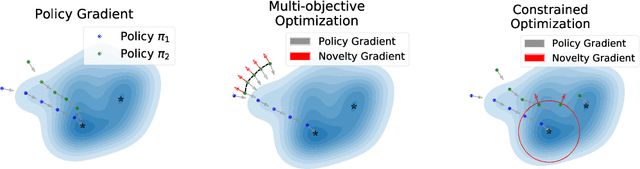
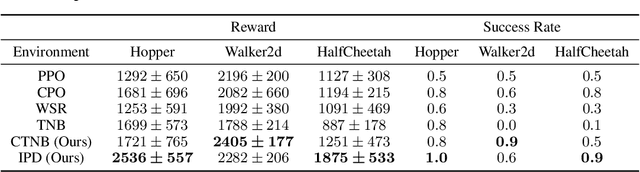
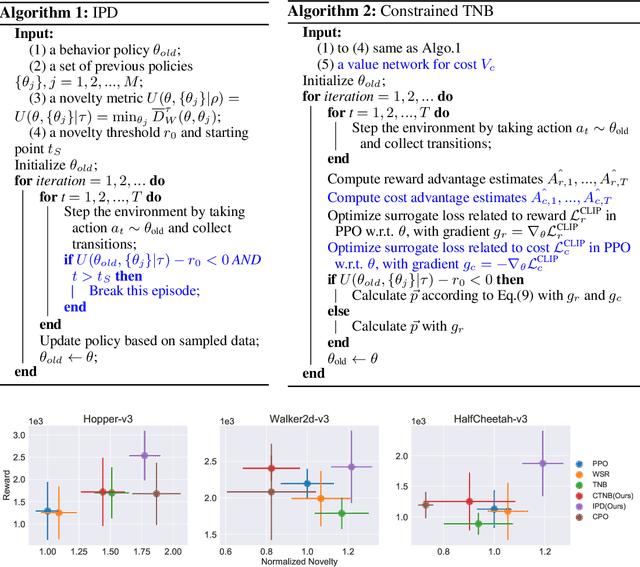
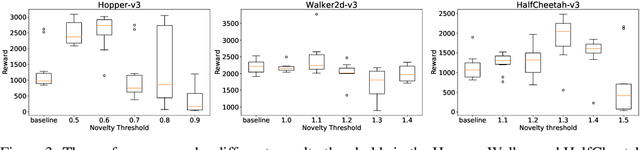
In this work, we address the problem of learning to seek novel policies in reinforcement learning tasks. Instead of following the multi-objective framework used in previous methods, we propose to rethink the problem under a novel perspective of constrained optimization. We first introduce a new metric to evaluate the difference between policies, and then design two practical novel policy seeking methods following the new perspective, namely the Constrained Task Novel Bisector (CTNB), and the Interior Policy Differentiation (IPD), corresponding to the feasible direction method and the interior point method commonly known in constrained optimization problems. Experimental comparisons on the MuJuCo control suite show our methods achieve substantial improvements over previous novelty-seeking methods in terms of both novelty and primal task performance.
InterFaceGAN: Interpreting the Disentangled Face Representation Learned by GANs
May 18, 2020
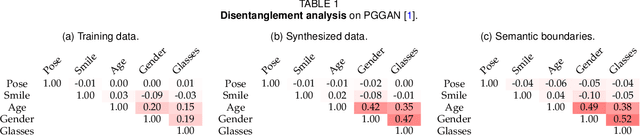
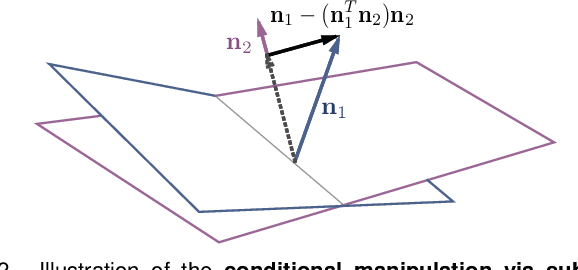
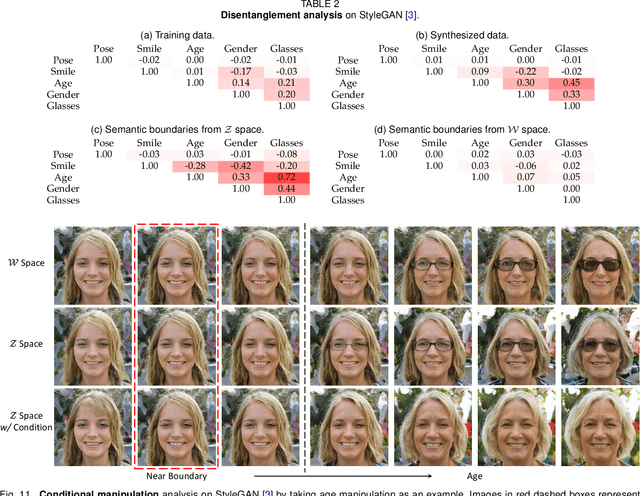
Although Generative Adversarial Networks (GANs) have made significant progress in face synthesis, there lacks enough understanding of what GANs have learned in the latent representation to map a randomly sampled code to a photo-realistic face image. In this work, we propose a framework, called InterFaceGAN, to interpret the disentangled face representation learned by the state-of-the-art GAN models and thoroughly analyze the properties of the facial semantics in the latent space. We first find that GANs actually learn various semantics in some linear subspaces of the latent space when being trained to synthesize high-quality faces. After identifying the subspaces of the corresponding latent semantics, we are able to realistically manipulate the facial attributes occurring in the synthesized images without retraining the model. We then conduct a detailed study on the correlation between different semantics and manage to better disentangle them via subspace projection, resulting in more precise control of the attribute manipulation. Besides manipulating gender, age, expression, and the presence of eyeglasses, we can even alter the face pose as well as fix the artifacts accidentally generated by GANs. Furthermore, we perform in-depth face identity analysis and layer-wise analysis to quantitatively evaluate the editing results. Finally, we apply our approach to real face editing by involving GAN inversion approaches as well as explicitly training additional feed-forward models based on the synthetic data established by InterFaceGAN. Extensive experimental results suggest that learning to synthesize faces spontaneously brings a disentangled and controllable face representation.
Semantic Photo Manipulation with a Generative Image Prior
May 15, 2020

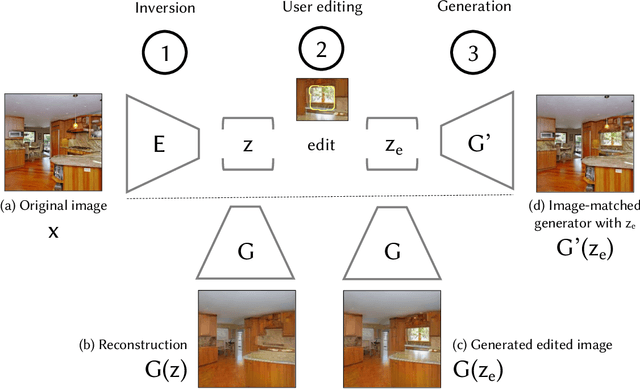
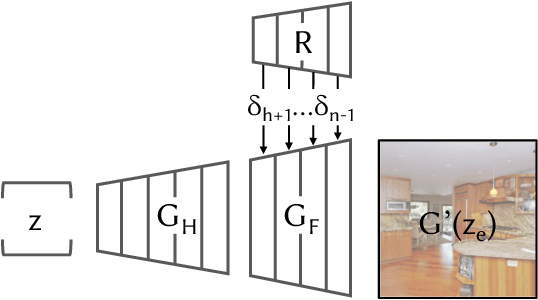
Despite the recent success of GANs in synthesizing images conditioned on inputs such as a user sketch, text, or semantic labels, manipulating the high-level attributes of an existing natural photograph with GANs is challenging for two reasons. First, it is hard for GANs to precisely reproduce an input image. Second, after manipulation, the newly synthesized pixels often do not fit the original image. In this paper, we address these issues by adapting the image prior learned by GANs to image statistics of an individual image. Our method can accurately reconstruct the input image and synthesize new content, consistent with the appearance of the input image. We demonstrate our interactive system on several semantic image editing tasks, including synthesizing new objects consistent with background, removing unwanted objects, and changing the appearance of an object. Quantitative and qualitative comparisons against several existing methods demonstrate the effectiveness of our method.
* SIGGRAPH 2019
Evolutionary Stochastic Policy Distillation
Apr 30, 2020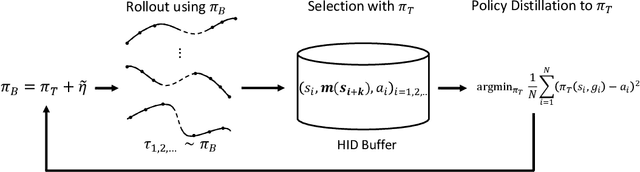


Solving the Goal-Conditioned Reward Sparse (GCRS) task is a challenging reinforcement learning problem due to the sparsity of reward signals. In this work, we propose a new formulation of GCRS tasks from the perspective of the drifted random walk on the state space, and design a novel method called Evolutionary Stochastic Policy Distillation (ESPD) to solve them based on the insight of reducing the First Hitting Time of the stochastic process. As a self-imitate approach, ESPD enables a target policy to learn from a series of its stochastic variants through the technique of policy distillation (PD). The learning mechanism of ESPD can be considered as an Evolution Strategy (ES) that applies perturbations upon policy directly on the action space, with a SELECT function to check the superiority of stochastic variants and then use PD to update the policy. The experiments based on the MuJoCo robotics control suite show the high learning efficiency of the proposed method.
A Local-to-Global Approach to Multi-modal Movie Scene Segmentation
Apr 28, 2020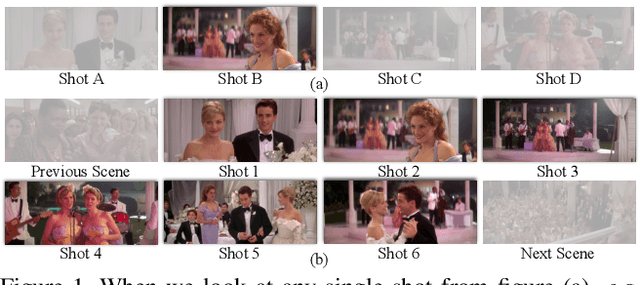
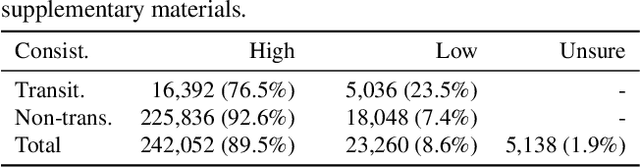


Scene, as the crucial unit of storytelling in movies, contains complex activities of actors and their interactions in a physical environment. Identifying the composition of scenes serves as a critical step towards semantic understanding of movies. This is very challenging -- compared to the videos studied in conventional vision problems, e.g. action recognition, as scenes in movies usually contain much richer temporal structures and more complex semantic information. Towards this goal, we scale up the scene segmentation task by building a large-scale video dataset MovieScenes, which contains 21K annotated scene segments from 150 movies. We further propose a local-to-global scene segmentation framework, which integrates multi-modal information across three levels, i.e. clip, segment, and movie. This framework is able to distill complex semantics from hierarchical temporal structures over a long movie, providing top-down guidance for scene segmentation. Our experiments show that the proposed network is able to segment a movie into scenes with high accuracy, consistently outperforming previous methods. We also found that pretraining on our MovieScenes can bring significant improvements to the existing approaches.
TPNet: Trajectory Proposal Network for Motion Prediction
Apr 26, 2020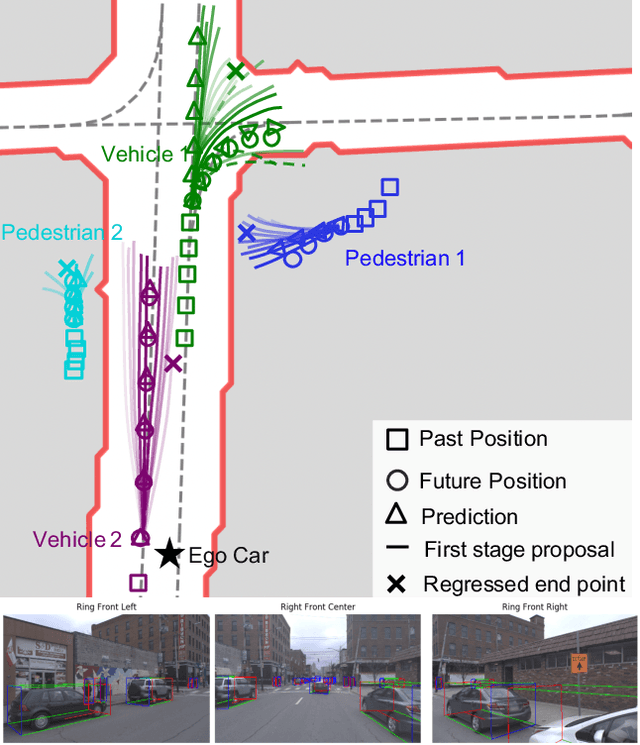
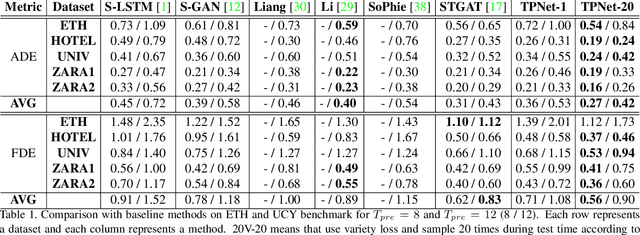
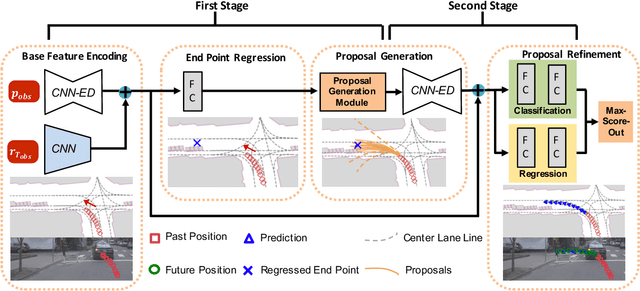
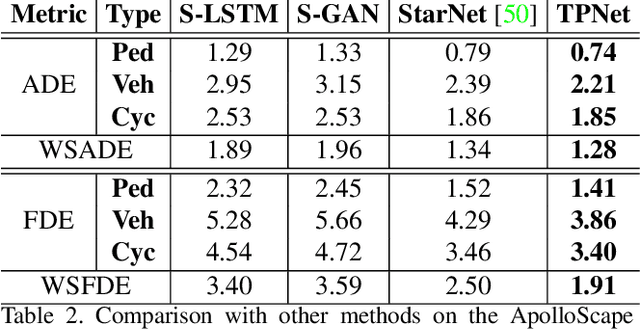
Making accurate motion prediction of the surrounding traffic agents such as pedestrians, vehicles, and cyclists is crucial for autonomous driving. Recent data-driven motion prediction methods have attempted to learn to directly regress the exact future position or its distribution from massive amount of trajectory data. However, it remains difficult for these methods to provide multimodal predictions as well as integrate physical constraints such as traffic rules and movable areas. In this work we propose a novel two-stage motion prediction framework, Trajectory Proposal Network (TPNet). TPNet first generates a candidate set of future trajectories as hypothesis proposals, then makes the final predictions by classifying and refining the proposals which meets the physical constraints. By steering the proposal generation process, safe and multimodal predictions are realized. Thus this framework effectively mitigates the complexity of motion prediction problem while ensuring the multimodal output. Experiments on four large-scale trajectory prediction datasets, i.e. the ETH, UCY, Apollo and Argoverse datasets, show that TPNet achieves the state-of-the-art results both quantitatively and qualitatively.