 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Situation Hyper-Graphs for Video Question Answering
Apr 18, 2023



Answering questions about complex situations in videos requires not only capturing the presence of actors, objects, and their relations but also the evolution of these relationships over time. A situation hyper-graph is a representation that describes situations as scene sub-graphs for video frames and hyper-edges for connected sub-graphs and has been proposed to capture all such information in a compact structured form. In this work, we propose an architecture for Video Question Answering (VQA) that enables answering questions related to video content by predicting situation hyper-graphs, coined Situation Hyper-Graph based Video Question Answering (SHG-VQA). To this end, we train a situation hyper-graph decoder to implicitly identify graph representations with actions and object/human-object relationships from the input video clip. and to use cross-attention between the predicted situation hyper-graphs and the question embedding to predict the correct answer. The proposed method is trained in an end-to-end manner and optimized by a VQA loss with the cross-entropy function and a Hungarian matching loss for the situation graph prediction. The effectiveness of the proposed architecture is extensively evaluated on two challenging benchmarks: AGQA and STAR. Our results show that learning the underlying situation hyper-graphs helps the system to significantly improve its performance for novel challenges of video question-answering tasks.
Visual Fault Detection of Multi-scale Key Components in Freight Trains
Nov 26, 2022



Fault detection for key components in the braking system of freight trains is critical for ensuring railway transportation safety. Despite the frequently employed methods based on deep learning, these fault detectors are highly reliant on hardware resources and are complex to implement. In addition, no train fault detectors consider the drop in accuracy induced by scale variation of fault parts. This paper proposes a lightweight anchor-free framework to solve the above problems. Specifically, to reduce the amount of computation and model size, we introduce a lightweight backbone and adopt an anchor-free method for localization and regression. To improve detection accuracy for multi-scale parts, we design a feature pyramid network to generate rectangular layers of different sizes to map parts with similar aspect ratios. Experiments on four fault datasets show that our framework achieves 98.44% accuracy while the model size is only 22.5 MB, outperforming state-of-the-art detectors.
Personalized Dialogue Generation with Persona-Adaptive Attention
Oct 27, 2022Persona-based dialogue systems aim to generate consistent responses based on historical context and predefined persona. Unlike conventional dialogue generation, the persona-based dialogue needs to consider both dialogue context and persona, posing a challenge for coherent training. Specifically, this requires a delicate weight balance between context and persona. To achieve that, in this paper, we propose an effective framework with Persona-Adaptive Attention (PAA), which adaptively integrates the weights from the persona and context information via our designed attention. In addition, a dynamic masking mechanism is applied to the PAA to not only drop redundant information in context and persona but also serve as a regularization mechanism to avoid overfitting. Experimental results demonstrate the superiority of the proposed PAA framework compared to the strong baselines in both automatic and human evaluation. Moreover, the proposed PAA approach can perform equivalently well in a low-resource regime compared to models trained in a full-data setting, which achieve a similar result with only 20% to 30% of data compared to the larger models trained in the full-data setting. To fully exploit the effectiveness of our design, we designed several variants for handling the weighted information in different ways, showing the necessity and sufficiency of our weighting and masking designs.
Compressing Pre-trained Transformers via Low-Bit NxM Sparsity for Natural Language Understanding
Jun 30, 2022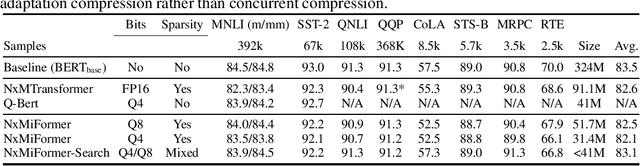
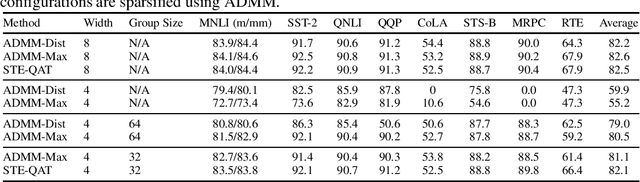
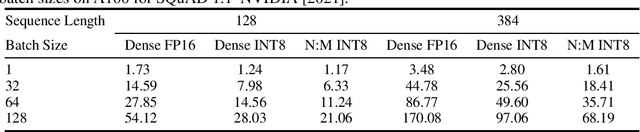

In recent years, large pre-trained Transformer networks have demonstrated dramatic improvements in many natural language understanding tasks. However, the huge size of these models brings significant challenges to their fine-tuning and online deployment due to latency and cost constraints. New hardware supporting both N:M semi-structured sparsity and low-precision integer computation is a promising solution to boost DNN model serving efficiency. However, there have been very few studies that systematically investigate to what extent pre-trained Transformer networks benefit from the combination of these techniques, as well as how to best compress each component of the Transformer. We propose a flexible compression framework NxMiFormer that performs simultaneous sparsification and quantization using ADMM and STE-based QAT. Furthermore, we present and inexpensive, heuristic-driven search algorithm that identifies promising heterogeneous compression configurations that meet a compression ratio constraint. When evaluated across the GLUE suite of NLU benchmarks, our approach can achieve up to 93% compression of the encoders of a BERT model while retaining 98.2% of the original model accuracy and taking full advantage of the hardware's capabilities. Heterogeneous configurations found the by the search heuristic maintain 99.5% of the baseline accuracy while still compressing the model by 87.5%.
A Lightweight NMS-free Framework for Real-time Visual Fault Detection System of Freight Trains
May 25, 2022
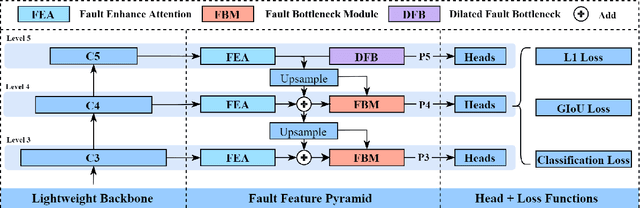
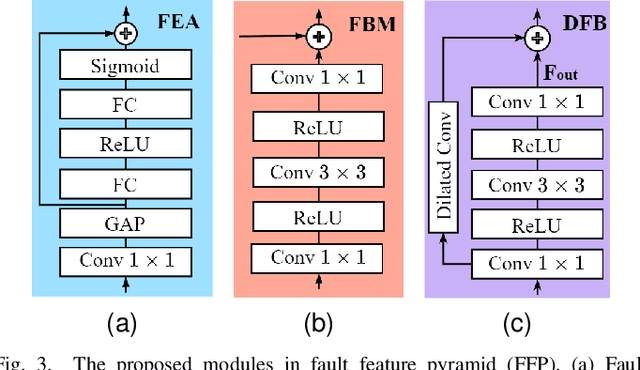

Real-time vision-based system of fault detection (RVBS-FD) for freight trains is an essential part of ensuring railway transportation safety. Most existing vision-based methods still have high computational costs based on convolutional neural networks. The computational cost is mainly reflected in the backbone, neck, and post-processing, i.e., non-maximum suppression (NMS). In this paper, we propose a lightweight NMS-free framework to achieve real-time detection and high accuracy simultaneously. First, we use a lightweight backbone for feature extraction and design a fault detection pyramid to process features. This fault detection pyramid includes three novel individual modules using attention mechanism, bottleneck, and dilated convolution for feature enhancement and computation reduction. Instead of using NMS, we calculate different loss functions, including classification and location costs in the detection head, to further reduce computation. Experimental results show that our framework achieves over 83 frames per second speed with a smaller model size and higher accuracy than the state-of-the-art detectors. Meanwhile, the hardware resource requirements of our method are low during the training and testing process.
DeepFD: Automated Fault Diagnosis and Localization for Deep Learning Programs
May 04, 2022
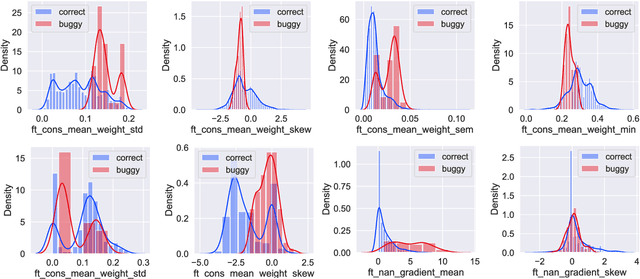

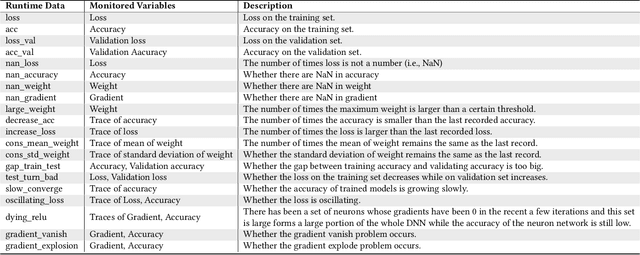
As Deep Learning (DL) systems are widely deployed for mission-critical applications, debugging such systems becomes essential. Most existing works identify and repair suspicious neurons on the trained Deep Neural Network (DNN), which, unfortunately, might be a detour. Specifically, several existing studies have reported that many unsatisfactory behaviors are actually originated from the faults residing in DL programs. Besides, locating faulty neurons is not actionable for developers, while locating the faulty statements in DL programs can provide developers with more useful information for debugging. Though a few recent studies were proposed to pinpoint the faulty statements in DL programs or the training settings (e.g. too large learning rate), they were mainly designed based on predefined rules, leading to many false alarms or false negatives, especially when the faults are beyond their capabilities. In view of these limitations, in this paper, we proposed DeepFD, a learning-based fault diagnosis and localization framework which maps the fault localization task to a learning problem. In particular, it infers the suspicious fault types via monitoring the runtime features extracted during DNN model training and then locates the diagnosed faults in DL programs. It overcomes the limitations by identifying the root causes of faults in DL programs instead of neurons and diagnosing the faults by a learning approach instead of a set of hard-coded rules. The evaluation exhibits the potential of DeepFD. It correctly diagnoses 52% faulty DL programs, compared with around half (27%) achieved by the best state-of-the-art works. Besides, for fault localization, DeepFD also outperforms the existing works, correctly locating 42% faulty programs, which almost doubles the best result (23%) achieved by the existing works.
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
Mar 15, 2022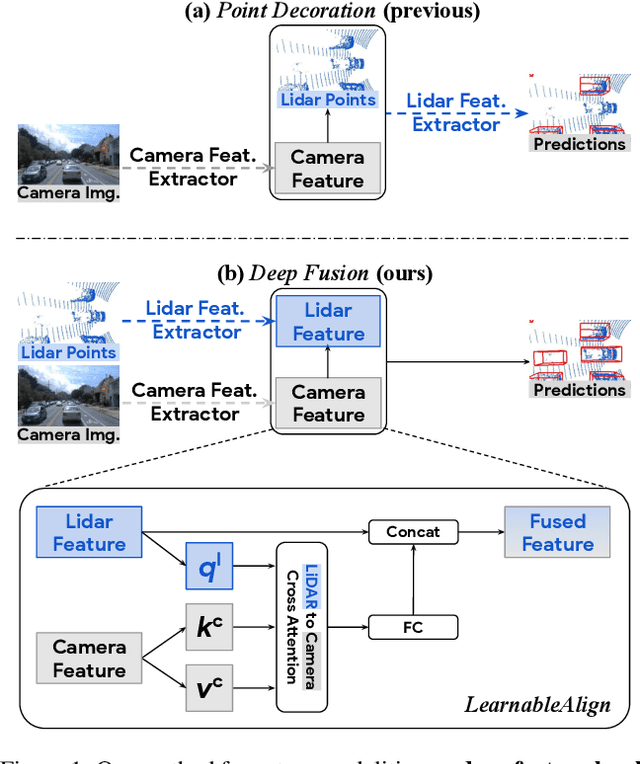
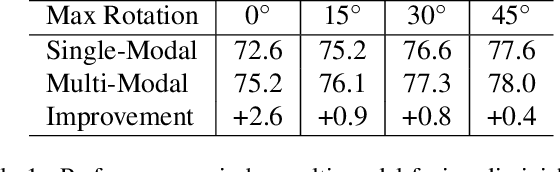
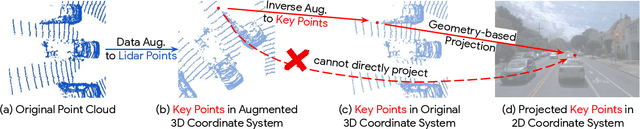
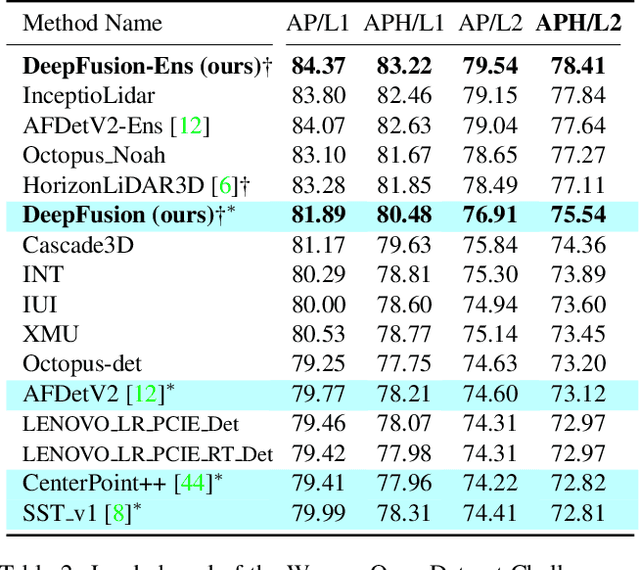
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While prevalent multi-modal methods simply decorate raw lidar point clouds with camera features and feed them directly to existing 3D detection models, our study shows that fusing camera features with deep lidar features instead of raw points, can lead to better performance. However, as those features are often augmented and aggregated, a key challenge in fusion is how to effectively align the transformed features from two modalities. In this paper, we propose two novel techniques: InverseAug that inverses geometric-related augmentations, e.g., rotation, to enable accurate geometric alignment between lidar points and image pixels, and LearnableAlign that leverages cross-attention to dynamically capture the correlations between image and lidar features during fusion. Based on InverseAug and LearnableAlign, we develop a family of generic multi-modal 3D detection models named DeepFusion, which is more accurate than previous methods. For example, DeepFusion improves PointPillars, CenterPoint, and 3D-MAN baselines on Pedestrian detection for 6.7, 8.9, and 6.2 LEVEL_2 APH, respectively. Notably, our models achieve state-of-the-art performance on Waymo Open Dataset, and show strong model robustness against input corruptions and out-of-distribution data. Code will be publicly available at https://github.com/tensorflow/lingvo/tree/master/lingvo/.
NxMTransformer: Semi-Structured Sparsification for Natural Language Understanding via ADMM
Oct 28, 2021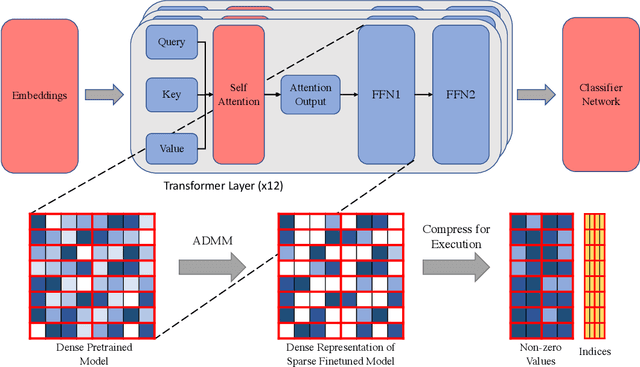
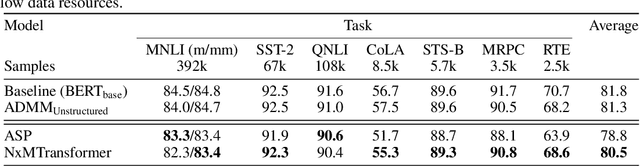
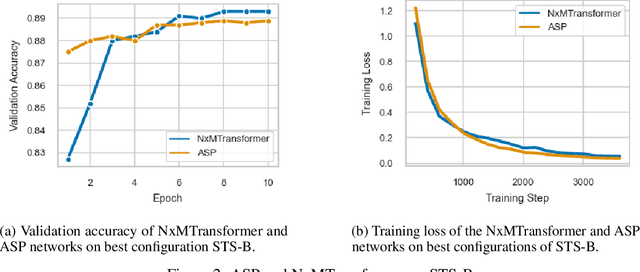

Natural Language Processing (NLP) has recently achieved success by using huge pre-trained Transformer networks. However, these models often contain hundreds of millions or even billions of parameters, bringing challenges to online deployment due to latency constraints. Recently, hardware manufacturers have introduced dedicated hardware for NxM sparsity to provide the flexibility of unstructured pruning with the runtime efficiency of structured approaches. NxM sparsity permits arbitrarily selecting M parameters to retain from a contiguous group of N in the dense representation. However, due to the extremely high complexity of pre-trained models, the standard sparse fine-tuning techniques often fail to generalize well on downstream tasks, which have limited data resources. To address such an issue in a principled manner, we introduce a new learning framework, called NxMTransformer, to induce NxM semi-structured sparsity on pretrained language models for natural language understanding to obtain better performance. In particular, we propose to formulate the NxM sparsity as a constrained optimization problem and use Alternating Direction Method of Multipliers (ADMM) to optimize the downstream tasks while taking the underlying hardware constraints into consideration. ADMM decomposes the NxM sparsification problem into two sub-problems that can be solved sequentially, generating sparsified Transformer networks that achieve high accuracy while being able to effectively execute on newly released hardware. We apply our approach to a wide range of NLP tasks, and our proposed method is able to achieve 1.7 points higher accuracy in GLUE score than current practices. Moreover, we perform detailed analysis on our approach and shed light on how ADMM affects fine-tuning accuracy for downstream tasks. Finally, we illustrate how NxMTransformer achieves performance improvement with knowledge distillation.
IGNNITION: Bridging the Gap Between Graph Neural Networks and Networking Systems
Sep 14, 2021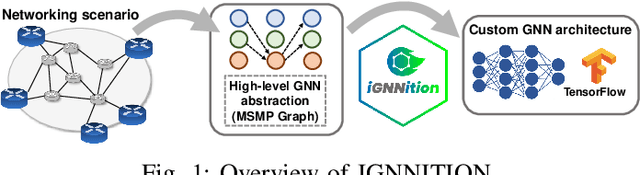
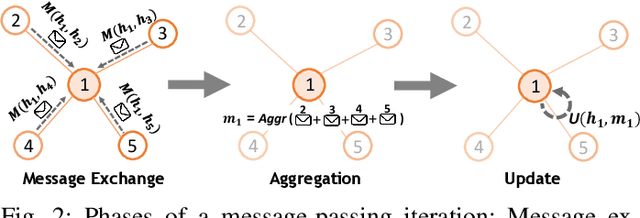
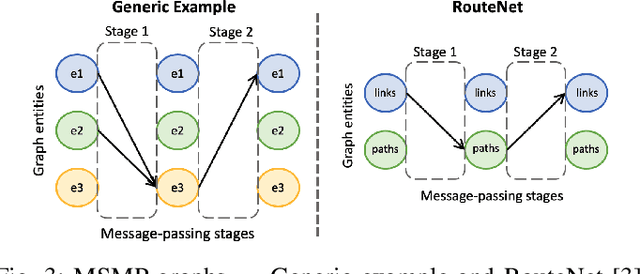

Recent years have seen the vast potential of Graph Neural Networks (GNN) in many fields where data is structured as graphs (e.g., chemistry, recommender systems). In particular, GNNs are becoming increasingly popular in the field of networking, as graphs are intrinsically present at many levels (e.g., topology, routing). The main novelty of GNNs is their ability to generalize to other networks unseen during training, which is an essential feature for developing practical Machine Learning (ML) solutions for networking. However, implementing a functional GNN prototype is currently a cumbersome task that requires strong skills in neural network programming. This poses an important barrier to network engineers that often do not have the necessary ML expertise. In this article, we present IGNNITION, a novel open-source framework that enables fast prototyping of GNNs for networking systems. IGNNITION is based on an intuitive high-level abstraction that hides the complexity behind GNNs, while still offering great flexibility to build custom GNN architectures. To showcase the versatility and performance of this framework, we implement two state-of-the-art GNN models applied to different networking use cases. Our results show that the GNN models produced by IGNNITION are equivalent in terms of accuracy and performance to their native implementations in TensorFlow.
Is Machine Learning Ready for Traffic Engineering Optimization?
Sep 03, 2021
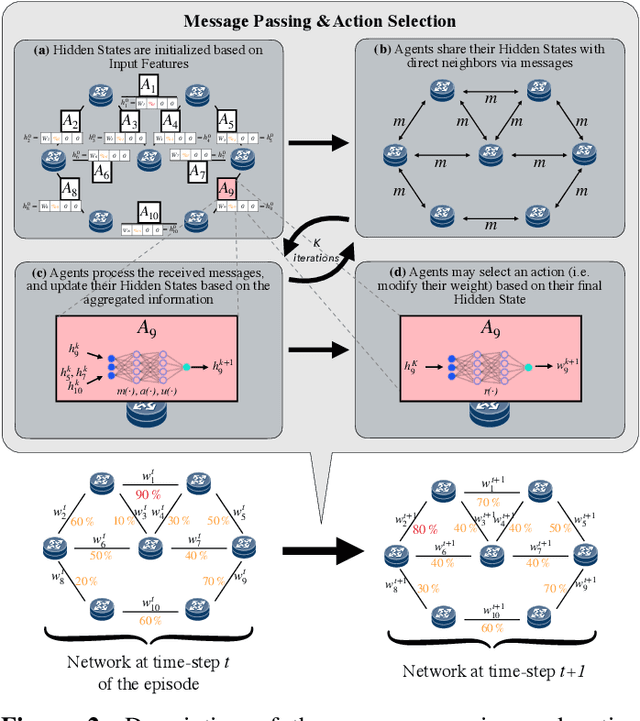
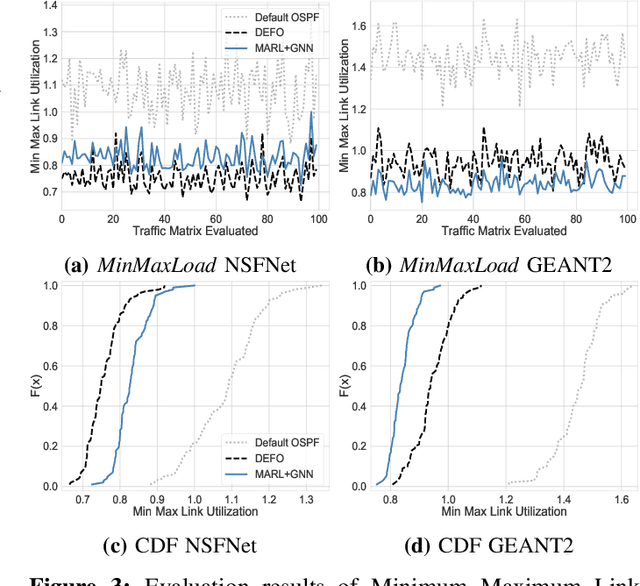
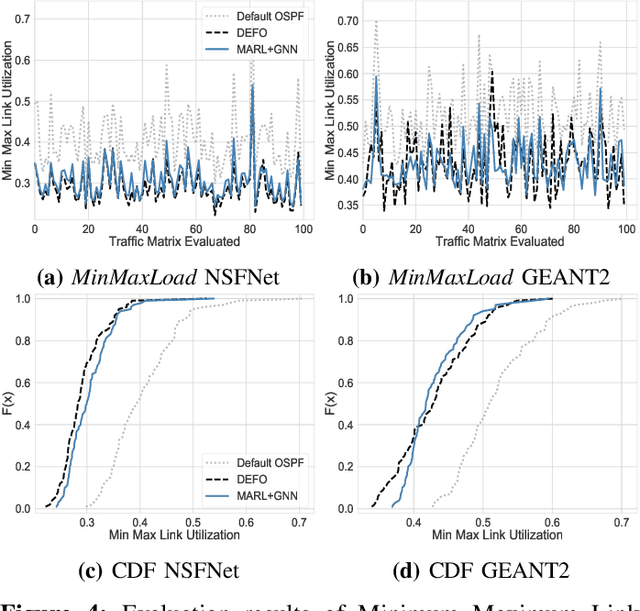
Traffic Engineering (TE) is a basic building block of the Internet. In this paper, we analyze whether modern Machine Learning (ML) methods are ready to be used for TE optimization. We address this open question through a comparative analysis between the state of the art in ML and the state of the art in TE. To this end, we first present a novel distributed system for TE that leverages the latest advancements in ML. Our system implements a novel architecture that combines Multi-Agent Reinforcement Learning (MARL) and Graph Neural Networks (GNN) to minimize network congestion. In our evaluation, we compare our MARL+GNN system with DEFO, a network optimizer based on Constraint Programming that represents the state of the art in TE. Our experimental results show that the proposed MARL+GNN solution achieves equivalent performance to DEFO in a wide variety of network scenarios including three real-world network topologies. At the same time, we show that MARL+GNN can achieve significant reductions in execution time (from the scale of minutes with DEFO to a few seconds with our solution).