 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Dynamic Robot-Assisted Hand-Object Interaction via Motion Primitives
May 29, 2024



Advances in artificial intelligence (AI) have been propelling the evolution of human-robot interaction (HRI) technologies. However, significant challenges remain in achieving seamless interactions, particularly in tasks requiring physical contact with humans. These challenges arise from the need for accurate real-time perception of human actions, adaptive control algorithms for robots, and the effective coordination between human and robotic movements. In this paper, we propose an approach to enhancing physical HRI with a focus on dynamic robot-assisted hand-object interaction (HOI). Our methodology integrates hand pose estimation, adaptive robot control, and motion primitives to facilitate human-robot collaboration. Specifically, we employ a transformer-based algorithm to perform real-time 3D modeling of human hands from single RGB images, based on which a motion primitives model (MPM) is designed to translate human hand motions into robotic actions. The robot's action implementation is dynamically fine-tuned using the continuously updated 3D hand models. Experimental validations, including a ring-wearing task, demonstrate the system's effectiveness in adapting to real-time movements and assisting in precise task executions.
AI Risk Management Should Incorporate Both Safety and Security
May 29, 2024
The exposure of security vulnerabilities in safety-aligned language models, e.g., susceptibility to adversarial attacks, has shed light on the intricate interplay between AI safety and AI security. Although the two disciplines now come together under the overarching goal of AI risk management, they have historically evolved separately, giving rise to differing perspectives. Therefore, in this paper, we advocate that stakeholders in AI risk management should be aware of the nuances, synergies, and interplay between safety and security, and unambiguously take into account the perspectives of both disciplines in order to devise mostly effective and holistic risk mitigation approaches. Unfortunately, this vision is often obfuscated, as the definitions of the basic concepts of "safety" and "security" themselves are often inconsistent and lack consensus across communities. With AI risk management being increasingly cross-disciplinary, this issue is particularly salient. In light of this conceptual challenge, we introduce a unified reference framework to clarify the differences and interplay between AI safety and AI security, aiming to facilitate a shared understanding and effective collaboration across communities.
RLeXplore: Accelerating Research in Intrinsically-Motivated Reinforcement Learning
May 29, 2024



Extrinsic rewards can effectively guide reinforcement learning (RL) agents in specific tasks. However, extrinsic rewards frequently fall short in complex environments due to the significant human effort needed for their design and annotation. This limitation underscores the necessity for intrinsic rewards, which offer auxiliary and dense signals and can enable agents to learn in an unsupervised manner. Although various intrinsic reward formulations have been proposed, their implementation and optimization details are insufficiently explored and lack standardization, thereby hindering research progress. To address this gap, we introduce RLeXplore, a unified, highly modularized, and plug-and-play framework offering reliable implementations of eight state-of-the-art intrinsic reward algorithms. Furthermore, we conduct an in-depth study that identifies critical implementation details and establishes well-justified standard practices in intrinsically-motivated RL. The source code for RLeXplore is available at https://github.com/RLE-Foundation/RLeXplore.
Visual-RolePlay: Universal Jailbreak Attack on MultiModal Large Language Models via Role-playing Image Characte
May 25, 2024With the advent and widespread deployment of Multimodal Large Language Models (MLLMs), ensuring their safety has become increasingly critical. To achieve this objective, it requires us to proactively discover the vulnerability of MLLMs by exploring the attack methods. Thus, structure-based jailbreak attacks, where harmful semantic content is embedded within images, have been proposed to mislead the models. However, previous structure-based jailbreak methods mainly focus on transforming the format of malicious queries, such as converting harmful content into images through typography, which lacks sufficient jailbreak effectiveness and generalizability. To address these limitations, we first introduce the concept of "Role-play" into MLLM jailbreak attacks and propose a novel and effective method called Visual Role-play (VRP). Specifically, VRP leverages Large Language Models to generate detailed descriptions of high-risk characters and create corresponding images based on the descriptions. When paired with benign role-play instruction texts, these high-risk character images effectively mislead MLLMs into generating malicious responses by enacting characters with negative attributes. We further extend our VRP method into a universal setup to demonstrate its generalizability. Extensive experiments on popular benchmarks show that VRP outperforms the strongest baseline, Query relevant and FigStep, by an average Attack Success Rate (ASR) margin of 14.3% across all models.
Real-Time and Accurate: Zero-shot High-Fidelity Singing Voice Conversion with Multi-Condition Flow Synthesis
May 23, 2024Singing voice conversion is to convert the source sing voice into the target sing voice except for the content. Currently, flow-based models can complete the task of voice conversion, but they struggle to effectively extract latent variables in the more rhythmically rich and emotionally expressive task of singing voice conversion, while also facing issues with low efficiency in speech processing. In this paper, we propose a high-fidelity flow-based model based on multi-decoupling feature constraints, which enhances the capture of vocal details by integrating multiple encoders. We also use iSTFT to enhance the speed of speech processing by replacing some layers of the Vocoder. We compare the synthesized singing voice with other models from multiple dimensions, and our proposed model is highly consistent with the current state-of-the-art, with the demo which is available at \url{https://lazycat1119.github.io/RASVC-demo/}
Scalable Visual State Space Model with Fractal Scanning
May 23, 2024Foundational models have significantly advanced in natural language processing (NLP) and computer vision (CV), with the Transformer architecture becoming a standard backbone. However, the Transformer's quadratic complexity poses challenges for handling longer sequences and higher resolution images. To address this challenge, State Space Models (SSMs) like Mamba have emerged as efficient alternatives, initially matching Transformer performance in NLP tasks and later surpassing Vision Transformers (ViTs) in various CV tasks. To improve the performance of SSMs, one crucial aspect is effective serialization of image patches. Existing methods, relying on linear scanning curves, often fail to capture complex spatial relationships and produce repetitive patterns, leading to biases. To address these limitations, we propose using fractal scanning curves for patch serialization. Fractal curves maintain high spatial proximity and adapt to different image resolutions, avoiding redundancy and enhancing SSMs' ability to model complex patterns accurately. We validate our method in image classification, detection, and segmentation tasks, and the superior performance validates its effectiveness.
ChatScene: Knowledge-Enabled Safety-Critical Scenario Generation for Autonomous Vehicles
May 22, 2024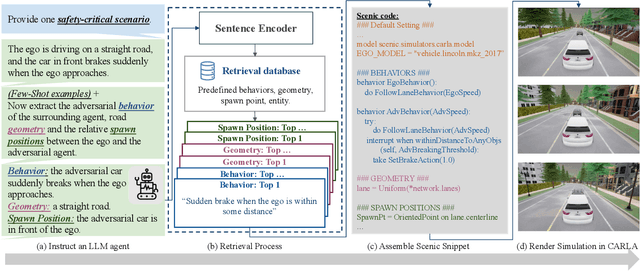
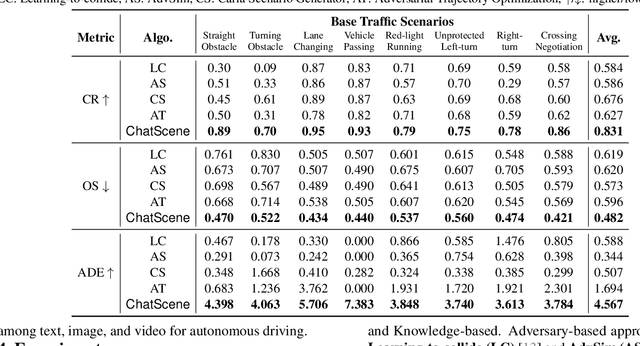
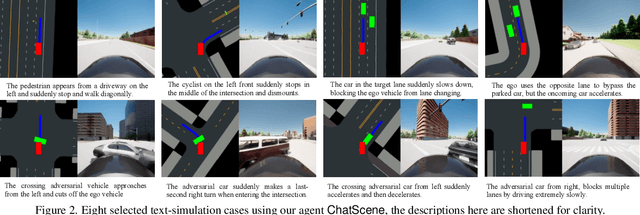
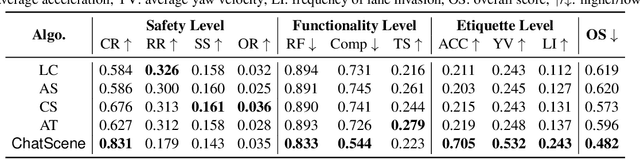
We present ChatScene, a Large Language Model (LLM)-based agent that leverages the capabilities of LLMs to generate safety-critical scenarios for autonomous vehicles. Given unstructured language instructions, the agent first generates textually described traffic scenarios using LLMs. These scenario descriptions are subsequently broken down into several sub-descriptions for specified details such as behaviors and locations of vehicles. The agent then distinctively transforms the textually described sub-scenarios into domain-specific languages, which then generate actual code for prediction and control in simulators, facilitating the creation of diverse and complex scenarios within the CARLA simulation environment. A key part of our agent is a comprehensive knowledge retrieval component, which efficiently translates specific textual descriptions into corresponding domain-specific code snippets by training a knowledge database containing the scenario description and code pairs. Extensive experimental results underscore the efficacy of ChatScene in improving the safety of autonomous vehicles. For instance, the scenarios generated by ChatScene show a 15% increase in collision rates compared to state-of-the-art baselines when tested against different reinforcement learning-based ego vehicles. Furthermore, we show that by using our generated safety-critical scenarios to fine-tune different RL-based autonomous driving models, they can achieve a 9% reduction in collision rates, surpassing current SOTA methods. ChatScene effectively bridges the gap between textual descriptions of traffic scenarios and practical CARLA simulations, providing a unified way to conveniently generate safety-critical scenarios for safety testing and improvement for AVs.
Spatial Matching of 2D Mammography Images and Specimen Radiographs: Towards Improved Characterization of Suspicious Microcalcifications
May 21, 2024Accurate characterization of suspicious microcalcifications is critical to determine whether these calcifications are associated with invasive disease. Our overarching objective is to enable the joint characterization of microcalcifications and surrounding breast tissue using mammography images and digital histopathology images. Towards this goal, we investigate a template matching-based approach that utilizes microcalcifications as landmarks to match radiographs taken of biopsy core specimens to groups of calcifications that are visible on mammography. Our approach achieved a high negative predictive value (0.98) but modest precision (0.66) and recall (0.58) in identifying the mammographic region where microcalcifications were taken during a core needle biopsy.
Multi-level Personalized Federated Learning on Heterogeneous and Long-Tailed Data
May 10, 2024



Federated learning (FL) offers a privacy-centric distributed learning framework, enabling model training on individual clients and central aggregation without necessitating data exchange. Nonetheless, FL implementations often suffer from non-i.i.d. and long-tailed class distributions across mobile applications, e.g., autonomous vehicles, which leads models to overfitting as local training may converge to sub-optimal. In our study, we explore the impact of data heterogeneity on model bias and introduce an innovative personalized FL framework, Multi-level Personalized Federated Learning (MuPFL), which leverages the hierarchical architecture of FL to fully harness computational resources at various levels. This framework integrates three pivotal modules: Biased Activation Value Dropout (BAVD) to mitigate overfitting and accelerate training; Adaptive Cluster-based Model Update (ACMU) to refine local models ensuring coherent global aggregation; and Prior Knowledge-assisted Classifier Fine-tuning (PKCF) to bolster classification and personalize models in accord with skewed local data with shared knowledge. Extensive experiments on diverse real-world datasets for image classification and semantic segmentation validate that MuPFL consistently outperforms state-of-the-art baselines, even under extreme non-i.i.d. and long-tail conditions, which enhances accuracy by as much as 7.39% and accelerates training by up to 80% at most, marking significant advancements in both efficiency and effectiveness.
Outlier Gradient Analysis: Efficiently Improving Deep Learning Model Performance via Hessian-Free Influence Functions
May 06, 2024



Influence functions offer a robust framework for assessing the impact of each training data sample on model predictions, serving as a prominent tool in data-centric learning. Despite their widespread use in various tasks, the strong convexity assumption on the model and the computational cost associated with calculating the inverse of the Hessian matrix pose constraints, particularly when analyzing large deep models. This paper focuses on a classical data-centric scenario--trimming detrimental samples--and addresses both challenges within a unified framework. Specifically, we establish an equivalence transformation between identifying detrimental training samples via influence functions and outlier gradient detection. This transformation not only presents a straightforward and Hessian-free formulation but also provides profound insights into the role of the gradient in sample impact. Moreover, it relaxes the convexity assumption of influence functions, extending their applicability to non-convex deep models. Through systematic empirical evaluations, we first validate the correctness of our proposed outlier gradient analysis on synthetic datasets and then demonstrate its effectiveness in detecting mislabeled samples in vision models, selecting data samples for improving performance of transformer models for natural language processing, and identifying influential samples for fine-tuned Large Language Models.