 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Balance with Asynchrony: Decoupling Exploration and Learning for Fast, Scalable LLM Post-Training
Mar 24, 2025Reinforcement learning (RL) is a critical component of large language model (LLM) post-training. However, existing on-policy algorithms used for post-training are inherently incompatible with the use of experience replay buffers, which can be populated scalably by distributed off-policy actors to enhance exploration as compute increases. We propose efficiently obtaining this benefit of replay buffers via Trajectory Balance with Asynchrony (TBA), a massively scalable LLM RL system. In contrast to existing approaches, TBA uses a larger fraction of compute on search, constantly generating off-policy data for a central replay buffer. A training node simultaneously samples data from this buffer based on reward or recency to update the policy using Trajectory Balance (TB), a diversity-seeking RL objective introduced for GFlowNets. TBA offers three key advantages: (1) decoupled training and search, speeding up training wall-clock time by 4x or more; (2) improved diversity through large-scale off-policy sampling; and (3) scalable search for sparse reward settings. On mathematical reasoning, preference-tuning, and automated red-teaming (diverse and representative post-training tasks), TBA produces speed and performance improvements over strong baselines.
TruthPrInt: Mitigating LVLM Object Hallucination Via Latent Truthful-Guided Pre-Intervention
Mar 13, 2025Object Hallucination (OH) has been acknowledged as one of the major trustworthy challenges in Large Vision-Language Models (LVLMs). Recent advancements in Large Language Models (LLMs) indicate that internal states, such as hidden states, encode the "overall truthfulness" of generated responses. However, it remains under-explored how internal states in LVLMs function and whether they could serve as "per-token" hallucination indicators, which is essential for mitigating OH. In this paper, we first conduct an in-depth exploration of LVLM internal states in relation to OH issues and discover that (1) LVLM internal states are high-specificity per-token indicators of hallucination behaviors. Moreover, (2) different LVLMs encode universal patterns of hallucinations in common latent subspaces, indicating that there exist "generic truthful directions" shared by various LVLMs. Based on these discoveries, we propose Truthful-Guided Pre-Intervention (TruthPrInt) that first learns the truthful direction of LVLM decoding and then applies truthful-guided inference-time intervention during LVLM decoding. We further propose ComnHallu to enhance both cross-LVLM and cross-data hallucination detection transferability by constructing and aligning hallucination latent subspaces. We evaluate TruthPrInt in extensive experimental settings, including in-domain and out-of-domain scenarios, over popular LVLMs and OH benchmarks. Experimental results indicate that TruthPrInt significantly outperforms state-of-the-art methods. Codes will be available at https://github.com/jinhaoduan/TruthPrInt.
Constrained Language Generation with Discrete Diffusion Models
Mar 12, 2025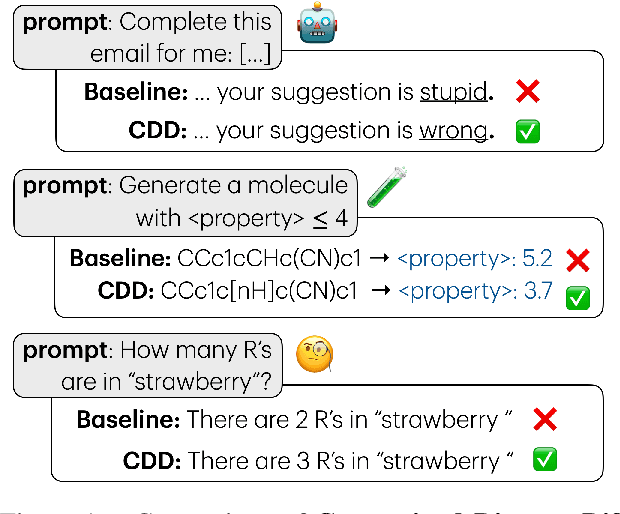



Constraints are critical in text generation as LLM outputs are often unreliable when it comes to ensuring generated outputs adhere to user defined instruction or general safety guidelines. To address this gap, we present Constrained Discrete Diffusion (CDD), a novel method for enforcing constraints on natural language by integrating discrete diffusion models with differentiable optimization. Unlike conventional text generators, which often rely on post-hoc filtering or model retraining for controllable generation, we propose imposing constraints directly into the discrete diffusion sampling process. We illustrate how this technique can be applied to satisfy a variety of natural language constraints, including (i) toxicity mitigation by preventing harmful content from emerging, (ii) character and sequence level lexical constraints, and (iii) novel molecule sequence generation with specific property adherence. Experimental results show that our constraint-aware procedure achieves high fidelity in meeting these requirements while preserving fluency and semantic coherence, outperforming auto-regressive and existing discrete diffusion approaches.
GRNFormer: A Biologically-Guided Framework for Integrating Gene Regulatory Networks into RNA Foundation Models
Mar 03, 2025Foundation models for single-cell RNA sequencing (scRNA-seq) have shown promising capabilities in capturing gene expression patterns. However, current approaches face critical limitations: they ignore biological prior knowledge encoded in gene regulatory relationships and fail to leverage multi-omics signals that could provide complementary regulatory insights. In this paper, we propose GRNFormer, a new framework that systematically integrates multi-scale Gene Regulatory Networks (GRNs) inferred from multi-omics data into RNA foundation model training. Our framework introduces two key innovations. First, we introduce a pipeline for constructing hierarchical GRNs that capture regulatory relationships at both cell-type-specific and cell-specific resolutions. Second, we design a structure-aware integration framework that addresses the information asymmetry in GRNs through two technical advances: (1) A graph topological adapter using multi-head cross-attention to weight regulatory relationships dynamically, and (2) a novel edge perturbation strategy that perturb GRNs with biologically-informed co-expression links to augment graph neural network training. Comprehensive experiments have been conducted on three representative downstream tasks across multiple model architectures to demonstrate the effectiveness of GRNFormer. It achieves consistent improvements over state-of-the-art (SoTA) baselines: $3.6\%$ increase in drug response prediction correlation, $9.6\%$ improvement in single-cell drug classification AUC, and $1.1\%$ average gain in gene perturbation prediction accuracy.
EAIRA: Establishing a Methodology for Evaluating AI Models as Scientific Research Assistants
Feb 27, 2025Recent advancements have positioned AI, and particularly Large Language Models (LLMs), as transformative tools for scientific research, capable of addressing complex tasks that require reasoning, problem-solving, and decision-making. Their exceptional capabilities suggest their potential as scientific research assistants but also highlight the need for holistic, rigorous, and domain-specific evaluation to assess effectiveness in real-world scientific applications. This paper describes a multifaceted methodology for Evaluating AI models as scientific Research Assistants (EAIRA) developed at Argonne National Laboratory. This methodology incorporates four primary classes of evaluations. 1) Multiple Choice Questions to assess factual recall; 2) Open Response to evaluate advanced reasoning and problem-solving skills; 3) Lab-Style Experiments involving detailed analysis of capabilities as research assistants in controlled environments; and 4) Field-Style Experiments to capture researcher-LLM interactions at scale in a wide range of scientific domains and applications. These complementary methods enable a comprehensive analysis of LLM strengths and weaknesses with respect to their scientific knowledge, reasoning abilities, and adaptability. Recognizing the rapid pace of LLM advancements, we designed the methodology to evolve and adapt so as to ensure its continued relevance and applicability. This paper describes the methodology state at the end of February 2025. Although developed within a subset of scientific domains, the methodology is designed to be generalizable to a wide range of scientific domains.
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Feb 07, 2025



We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling to arbitrary depth at test-time. This stands in contrast to mainstream reasoning models that scale up compute by producing more tokens. Unlike approaches based on chain-of-thought, our approach does not require any specialized training data, can work with small context windows, and can capture types of reasoning that are not easily represented in words. We scale a proof-of-concept model to 3.5 billion parameters and 800 billion tokens. We show that the resulting model can improve its performance on reasoning benchmarks, sometimes dramatically, up to a computation load equivalent to 50 billion parameters.
Extracting and Understanding the Superficial Knowledge in Alignment
Feb 07, 2025



Alignment of large language models (LLMs) with human values and preferences, often achieved through fine-tuning based on human feedback, is essential for ensuring safe and responsible AI behaviors. However, the process typically requires substantial data and computation resources. Recent studies have revealed that alignment might be attainable at lower costs through simpler methods, such as in-context learning. This leads to the question: Is alignment predominantly superficial? In this paper, we delve into this question and provide a quantitative analysis. We formalize the concept of superficial knowledge, defining it as knowledge that can be acquired through easily token restyling, without affecting the model's ability to capture underlying causal relationships between tokens. We propose a method to extract and isolate superficial knowledge from aligned models, focusing on the shallow modifications to the final token selection process. By comparing models augmented only with superficial knowledge to fully aligned models, we quantify the superficial portion of alignment. Our findings reveal that while superficial knowledge constitutes a significant portion of alignment, particularly in safety and detoxification tasks, it is not the whole story. Tasks requiring reasoning and contextual understanding still rely on deeper knowledge. Additionally, we demonstrate two practical advantages of isolated superficial knowledge: (1) it can be transferred between models, enabling efficient offsite alignment of larger models using extracted superficial knowledge from smaller models, and (2) it is recoverable, allowing for the restoration of alignment in compromised models without sacrificing performance.
Double Visual Defense: Adversarial Pre-training and Instruction Tuning for Improving Vision-Language Model Robustness
Jan 16, 2025



This paper investigates the robustness of vision-language models against adversarial visual perturbations and introduces a novel ``double visual defense" to enhance this robustness. Unlike previous approaches that resort to lightweight adversarial fine-tuning of a pre-trained CLIP model, we perform large-scale adversarial vision-language pre-training from scratch using web-scale data. We then strengthen the defense by incorporating adversarial visual instruction tuning. The resulting models from each stage, $\Delta$CLIP and $\Delta^2$LLaVA, show substantially enhanced zero-shot robustness and set a new state-of-the-art in adversarial defense for vision-language models. For example, the adversarial robustness of $\Delta$CLIP surpasses that of the previous best models on ImageNet-1k by ~20%. %For example, $\Delta$CLIP surpasses the previous best models on ImageNet-1k by ~20% in terms of adversarial robustness. Similarly, compared to prior art, $\Delta^2$LLaVA brings a ~30% robustness improvement to image captioning task and a ~20% robustness improvement to visual question answering task. Furthermore, our models exhibit stronger zero-shot recognition capability, fewer hallucinations, and superior reasoning performance compared to baselines. Our project page is https://doublevisualdefense.github.io/.
Layer-Level Self-Exposure and Patch: Affirmative Token Mitigation for Jailbreak Attack Defense
Jan 05, 2025As large language models (LLMs) are increasingly deployed in diverse applications, including chatbot assistants and code generation, aligning their behavior with safety and ethical standards has become paramount. However, jailbreak attacks, which exploit vulnerabilities to elicit unintended or harmful outputs, threaten LLMs' safety significantly. In this paper, we introduce Layer-AdvPatcher, a novel methodology designed to defend against jailbreak attacks by utilizing an unlearning strategy to patch specific layers within LLMs through self-augmented datasets. Our insight is that certain layer(s), tend to produce affirmative tokens when faced with harmful prompts. By identifying these layers and adversarially exposing them to generate more harmful data, one can understand their inherent and diverse vulnerabilities to attacks. With these exposures, we then "unlearn" these issues, reducing the impact of affirmative tokens and hence minimizing jailbreak risks while keeping the model's responses to safe queries intact. We conduct extensive experiments on two models, four benchmark datasets, and multiple state-of-the-art jailbreak benchmarks to demonstrate the efficacy of our approach. Results indicate that our framework reduces the harmfulness and attack success rate of jailbreak attacks without compromising utility for benign queries compared to recent defense methods.
Active Learning Enables Extrapolation in Molecular Generative Models
Jan 03, 2025



Although generative models hold promise for discovering molecules with optimized desired properties, they often fail to suggest synthesizable molecules that improve upon the known molecules seen in training. We find that a key limitation is not in the molecule generation process itself, but in the poor generalization capabilities of molecular property predictors. We tackle this challenge by creating an active-learning, closed-loop molecule generation pipeline, whereby molecular generative models are iteratively refined on feedback from quantum chemical simulations to improve generalization to new chemical space. Compared against other generative model approaches, only our active learning approach generates molecules with properties that extrapolate beyond the training data (reaching up to 0.44 standard deviations beyond the training data range) and out-of-distribution molecule classification accuracy is improved by 79%. By conditioning molecular generation on thermodynamic stability data from the active-learning loop, the proportion of stable molecules generated is 3.5x higher than the next-best model.