 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamCache: Finetuning-Free Lightweight Personalized Image Generation via Feature Caching
Nov 26, 2024



Personalized image generation requires text-to-image generative models that capture the core features of a reference subject to allow for controlled generation across different contexts. Existing methods face challenges due to complex training requirements, high inference costs, limited flexibility, or a combination of these issues. In this paper, we introduce DreamCache, a scalable approach for efficient and high-quality personalized image generation. By caching a small number of reference image features from a subset of layers and a single timestep of the pretrained diffusion denoiser, DreamCache enables dynamic modulation of the generated image features through lightweight, trained conditioning adapters. DreamCache achieves state-of-the-art image and text alignment, utilizing an order of magnitude fewer extra parameters, and is both more computationally effective and versatile than existing models.
Knowledge Transfer Across Modalities with Natural Language Supervision
Nov 23, 2024



We present a way to learn novel concepts by only using their textual description. We call this method Knowledge Transfer. Similarly to human perception, we leverage cross-modal interaction to introduce new concepts. We hypothesize that in a pre-trained visual encoder there are enough low-level features already learned (e.g. shape, appearance, color) that can be used to describe previously unknown high-level concepts. Provided with a textual description of the novel concept, our method works by aligning the known low-level features of the visual encoder to its high-level textual description. We show that Knowledge Transfer can successfully introduce novel concepts in multimodal models, in a very efficient manner, by only requiring a single description of the target concept. Our approach is compatible with both separate textual and visual encoders (e.g. CLIP) and shared parameters across modalities. We also show that, following the same principle, Knowledge Transfer can improve concepts already known by the model. Leveraging Knowledge Transfer we improve zero-shot performance across different tasks such as classification, segmentation, image-text retrieval, and captioning.
MotionCraft: Physics-based Zero-Shot Video Generation
May 22, 2024



Generating videos with realistic and physically plausible motion is one of the main recent challenges in computer vision. While diffusion models are achieving compelling results in image generation, video diffusion models are limited by heavy training and huge models, resulting in videos that are still biased to the training dataset. In this work we propose MotionCraft, a new zero-shot video generator to craft physics-based and realistic videos. MotionCraft is able to warp the noise latent space of an image diffusion model, such as Stable Diffusion, by applying an optical flow derived from a physics simulation. We show that warping the noise latent space results in coherent application of the desired motion while allowing the model to generate missing elements consistent with the scene evolution, which would otherwise result in artefacts or missing content if the flow was applied in the pixel space. We compare our method with the state-of-the-art Text2Video-Zero reporting qualitative and quantitative improvements, demonstrating the effectiveness of our approach to generate videos with finely-prescribed complex motion dynamics. Project page: https://mezzelfo.github.io/MotionCraft/
Jointly Training Large Autoregressive Multimodal Models
Sep 28, 2023



In recent years, advances in the large-scale pretraining of language and text-to-image models have revolutionized the field of machine learning. Yet, integrating these two modalities into a single, robust model capable of generating seamless multimodal outputs remains a significant challenge. To address this gap, we present the Joint Autoregressive Mixture (JAM) framework, a modular approach that systematically fuses existing text and image generation models. We also introduce a specialized, data-efficient instruction-tuning strategy, tailored for mixed-modal generation tasks. Our final instruct-tuned model demonstrates unparalleled performance in generating high-quality multimodal outputs and represents the first model explicitly designed for this purpose.
Fast Inference in Denoising Diffusion Models via MMD Finetuning
Jan 19, 2023



Denoising Diffusion Models (DDMs) have become a popular tool for generating high-quality samples from complex data distributions. These models are able to capture sophisticated patterns and structures in the data, and can generate samples that are highly diverse and representative of the underlying distribution. However, one of the main limitations of diffusion models is the complexity of sample generation, since a large number of inference timesteps is required to faithfully capture the data distribution. In this paper, we present MMD-DDM, a novel method for fast sampling of diffusion models. Our approach is based on the idea of using the Maximum Mean Discrepancy (MMD) to finetune the learned distribution with a given budget of timesteps. This allows the finetuned model to significantly improve the speed-quality trade-off, by substantially increasing fidelity in inference regimes with few steps or, equivalently, by reducing the required number of steps to reach a target fidelity, thus paving the way for a more practical adoption of diffusion models in a wide range of applications. We evaluate our approach on unconditional image generation with extensive experiments across the CIFAR-10, CelebA, ImageNet and LSUN-Church datasets. Our findings show that the proposed method is able to produce high-quality samples in a fraction of the time required by widely-used diffusion models, and outperforms state-of-the-art techniques for accelerated sampling. Code is available at: https://github.com/diegovalsesia/MMD-DDM.
Cross-modal Learning for Image-Guided Point Cloud Shape Completion
Sep 20, 2022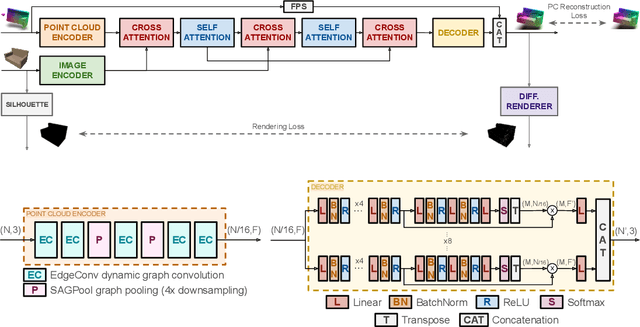
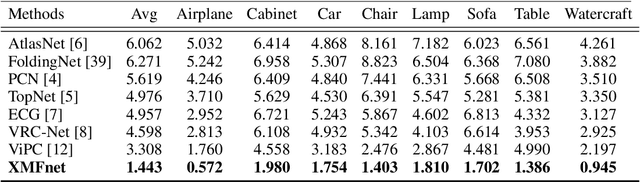
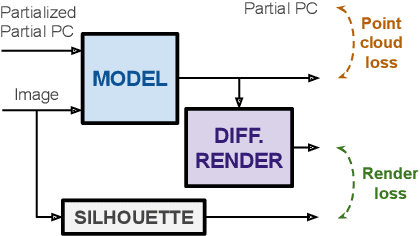
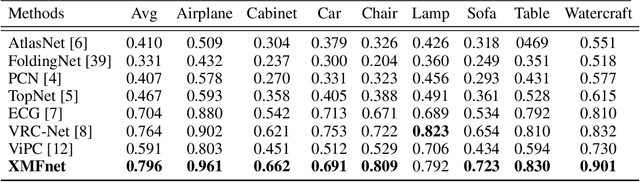
In this paper we explore the recent topic of point cloud completion, guided by an auxiliary image. We show how it is possible to effectively combine the information from the two modalities in a localized latent space, thus avoiding the need for complex point cloud reconstruction methods from single views used by the state-of-the-art. We also investigate a novel weakly-supervised setting where the auxiliary image provides a supervisory signal to the training process by using a differentiable renderer on the completed point cloud to measure fidelity in the image space. Experiments show significant improvements over state-of-the-art supervised methods for both unimodal and multimodal completion. We also show the effectiveness of the weakly-supervised approach which outperforms a number of supervised methods and is competitive with the latest supervised models only exploiting point cloud information.