 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cross-Image Object Semantic Relation in Transformer for Few-Shot Fine-Grained Image Classification
Jul 02, 2022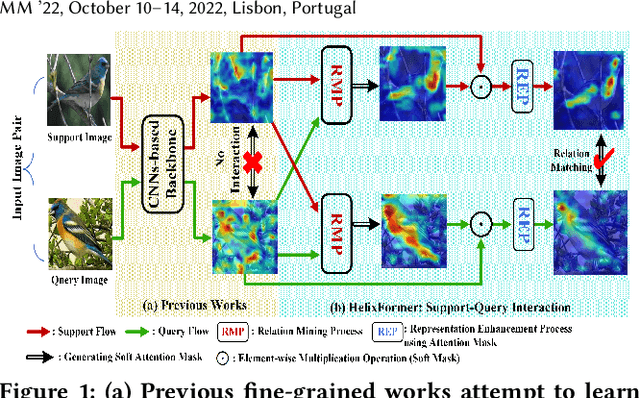
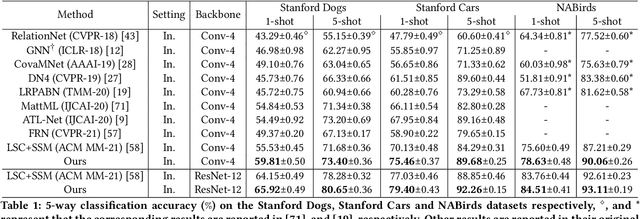
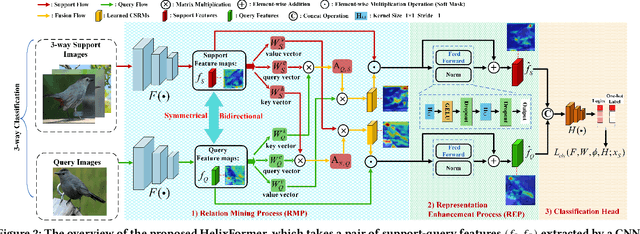
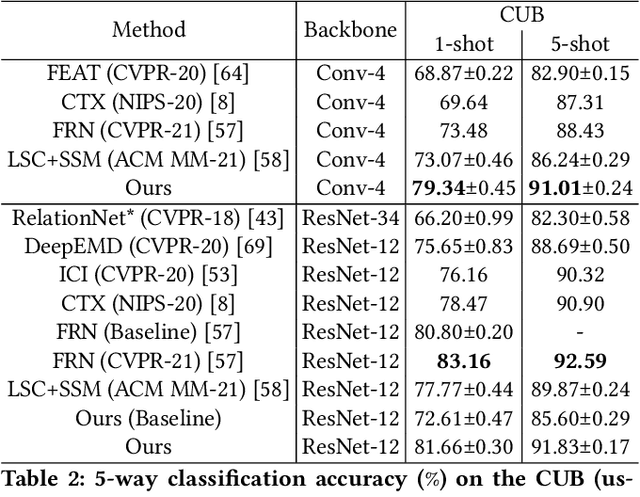
Few-shot fine-grained learning aims to classify a query image into one of a set of support categories with fine-grained differences. Although learning different objects' local differences via Deep Neural Networks has achieved success, how to exploit the query-support cross-image object semantic relations in Transformer-based architecture remains under-explored in the few-shot fine-grained scenario. In this work, we propose a Transformer-based double-helix model, namely HelixFormer, to achieve the cross-image object semantic relation mining in a bidirectional and symmetrical manner. The HelixFormer consists of two steps: 1) Relation Mining Process (RMP) across different branches, and 2) Representation Enhancement Process (REP) within each individual branch. By the designed RMP, each branch can extract fine-grained object-level Cross-image Semantic Relation Maps (CSRMs) using information from the other branch, ensuring better cross-image interaction in semantically related local object regions. Further, with the aid of CSRMs, the developed REP can strengthen the extracted features for those discovered semantically-related local regions in each branch, boosting the model's ability to distinguish subtle feature differences of fine-grained objects. Extensive experiments conducted on five public fine-grained benchmarks demonstrate that HelixFormer can effectively enhance the cross-image object semantic relation matching for recognizing fine-grained objects, achieving much better performance over most state-of-the-art methods under 1-shot and 5-shot scenarios. Our code is available at: https://github.com/JiakangYuan/HelixFormer
ShiftAddNAS: Hardware-Inspired Search for More Accurate and Efficient Neural Networks
May 17, 2022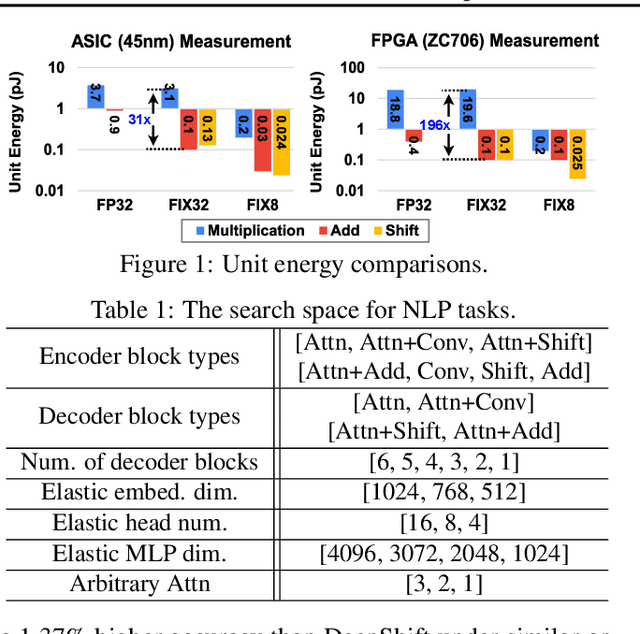
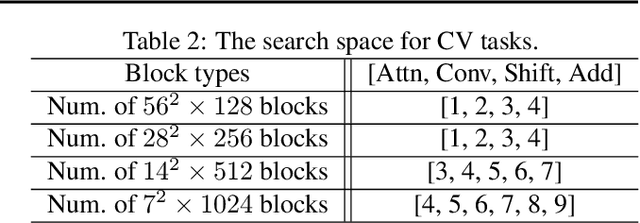
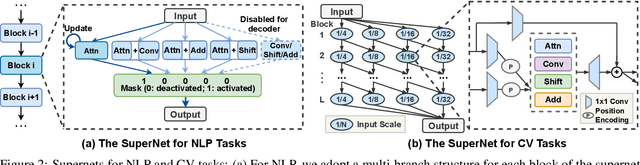
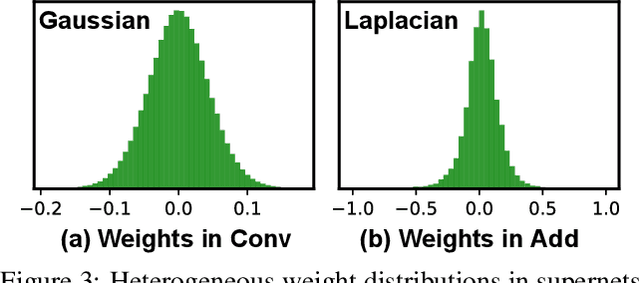
Neural networks (NNs) with intensive multiplications (e.g., convolutions and transformers) are capable yet power hungry, impeding their more extensive deployment into resource-constrained devices. As such, multiplication-free networks, which follow a common practice in energy-efficient hardware implementation to parameterize NNs with more efficient operators (e.g., bitwise shifts and additions), have gained growing attention. However, multiplication-free networks usually under-perform their vanilla counterparts in terms of the achieved accuracy. To this end, this work advocates hybrid NNs that consist of both powerful yet costly multiplications and efficient yet less powerful operators for marrying the best of both worlds, and proposes ShiftAddNAS, which can automatically search for more accurate and more efficient NNs. Our ShiftAddNAS highlights two enablers. Specifically, it integrates (1) the first hybrid search space that incorporates both multiplication-based and multiplication-free operators for facilitating the development of both accurate and efficient hybrid NNs; and (2) a novel weight sharing strategy that enables effective weight sharing among different operators that follow heterogeneous distributions (e.g., Gaussian for convolutions vs. Laplacian for add operators) and simultaneously leads to a largely reduced supernet size and much better searched networks. Extensive experiments and ablation studies on various models, datasets, and tasks consistently validate the efficacy of ShiftAddNAS, e.g., achieving up to a +7.7% higher accuracy or a +4.9 better BLEU score compared to state-of-the-art NN, while leading to up to 93% or 69% energy and latency savings, respectively. Codes and pretrained models are available at https://github.com/RICE-EIC/ShiftAddNAS.
Towards Robust Adaptive Object Detection under Noisy Annotations
Apr 06, 2022
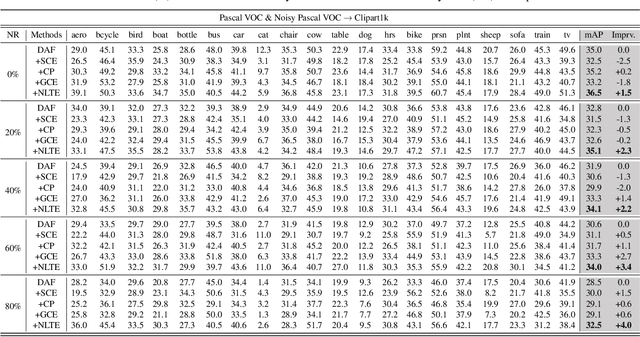
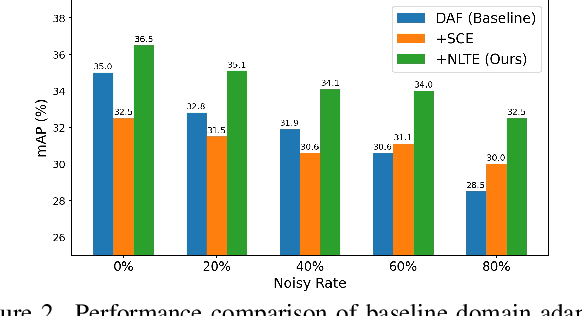
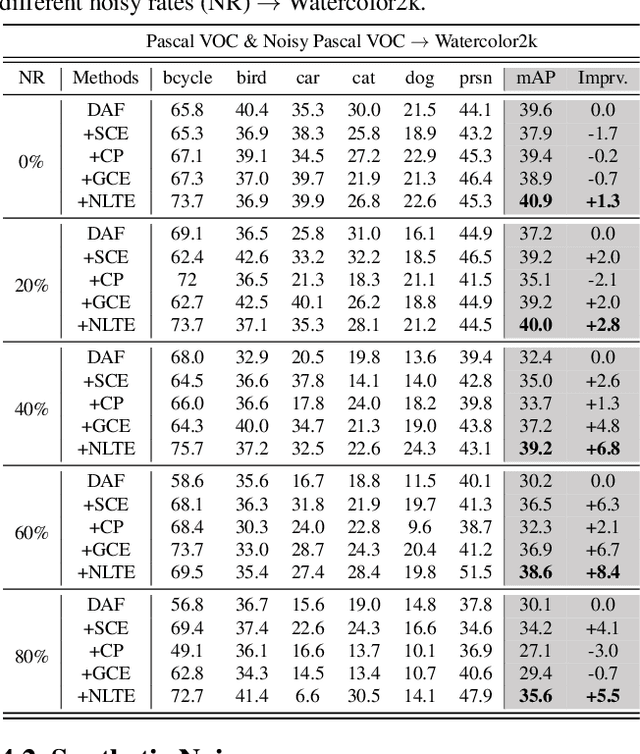
Domain Adaptive Object Detection (DAOD) models a joint distribution of images and labels from an annotated source domain and learns a domain-invariant transformation to estimate the target labels with the given target domain images. Existing methods assume that the source domain labels are completely clean, yet large-scale datasets often contain error-prone annotations due to instance ambiguity, which may lead to a biased source distribution and severely degrade the performance of the domain adaptive detector de facto. In this paper, we represent the first effort to formulate noisy DAOD and propose a Noise Latent Transferability Exploration (NLTE) framework to address this issue. It is featured with 1) Potential Instance Mining (PIM), which leverages eligible proposals to recapture the miss-annotated instances from the background; 2) Morphable Graph Relation Module (MGRM), which models the adaptation feasibility and transition probability of noisy samples with relation matrices; 3) Entropy-Aware Gradient Reconcilement (EAGR), which incorporates the semantic information into the discrimination process and enforces the gradients provided by noisy and clean samples to be consistent towards learning domain-invariant representations. A thorough evaluation on benchmark DAOD datasets with noisy source annotations validates the effectiveness of NLTE. In particular, NLTE improves the mAP by 8.4\% under 60\% corrupted annotations and even approaches the ideal upper bound of training on a clean source dataset.
Towards Bidirectional Arbitrary Image Rescaling: Joint Optimization and Cycle Idempotence
Mar 08, 2022
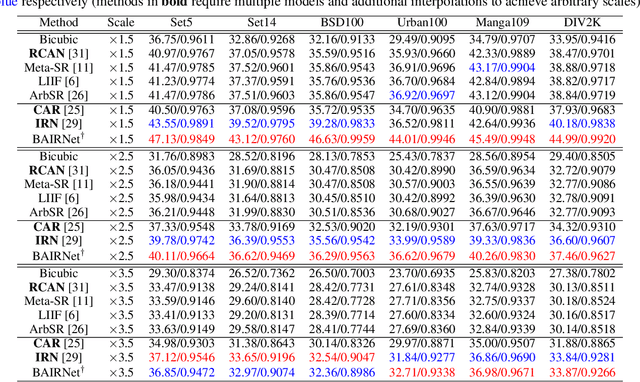
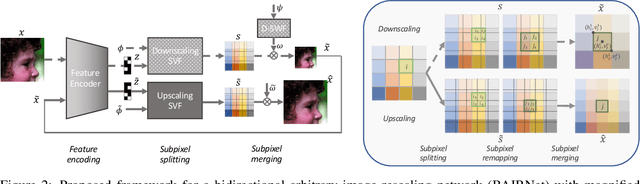

Deep learning based single image super-resolution models have been widely studied and superb results are achieved in upscaling low-resolution images with fixed scale factor and downscaling degradation kernel. To improve real world applicability of such models, there are growing interests to develop models optimized for arbitrary upscaling factors. Our proposed method is the first to treat arbitrary rescaling, both upscaling and downscaling, as one unified process. Using joint optimization of both directions, the proposed model is able to learn upscaling and downscaling simultaneously and achieve bidirectional arbitrary image rescaling. It improves the performance of current arbitrary upscaling models by a large margin while at the same time learns to maintain visual perception quality in downscaled images. The proposed model is further shown to be robust in cycle idempotence test, free of severe degradations in reconstruction accuracy when the downscaling-to-upscaling cycle is applied repetitively. This robustness is beneficial for image rescaling in the wild when this cycle could be applied to one image for multiple times. It also performs well on tests with arbitrary large scales and asymmetric scales, even when the model is not trained with such tasks. Extensive experiments are conducted to demonstrate the superior performance of our model.
$β$-DARTS: Beta-Decay Regularization for Differentiable Architecture Search
Mar 04, 2022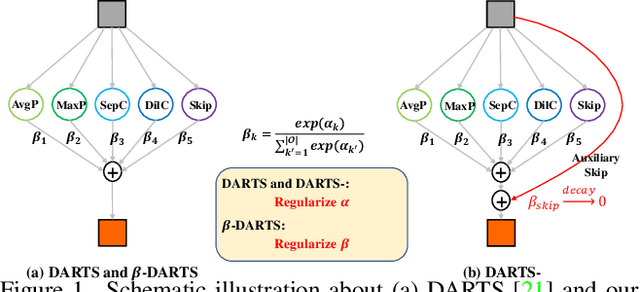
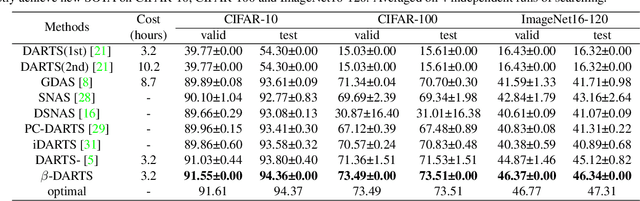
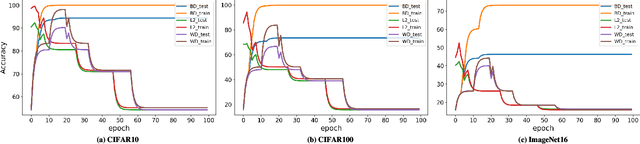
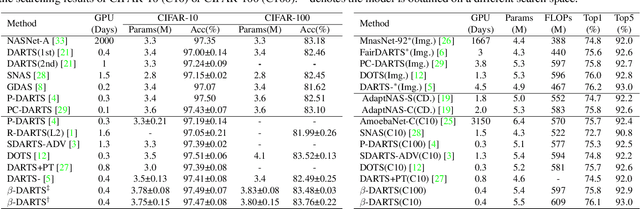
Neural Architecture Search~(NAS) has attracted increasingly more attention in recent years because of its capability to design deep neural networks automatically. Among them, differential NAS approaches such as DARTS, have gained popularity for the search efficiency. However, they suffer from two main issues, the weak robustness to the performance collapse and the poor generalization ability of the searched architectures. To solve these two problems, a simple-but-efficient regularization method, termed as Beta-Decay, is proposed to regularize the DARTS-based NAS searching process. Specifically, Beta-Decay regularization can impose constraints to keep the value and variance of activated architecture parameters from too large. Furthermore, we provide in-depth theoretical analysis on how it works and why it works. Experimental results on NAS-Bench-201 show that our proposed method can help to stabilize the searching process and makes the searched network more transferable across different datasets. In addition, our search scheme shows an outstanding property of being less dependent on training time and data. Comprehensive experiments on a variety of search spaces and datasets validate the effectiveness of the proposed method.
Exploring Gradient Flow Based Saliency for DNN Model Compression
Oct 24, 2021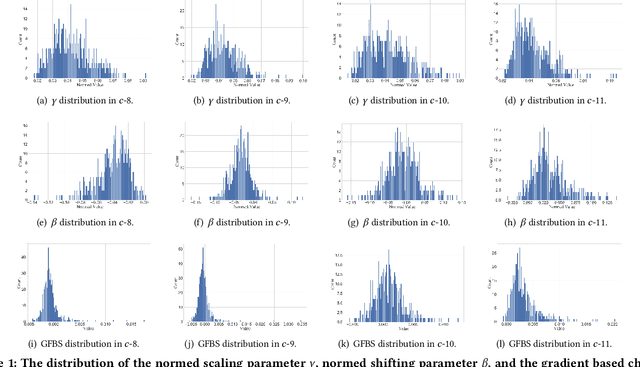
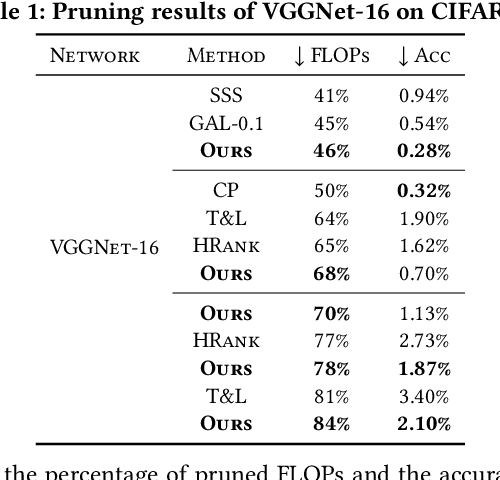
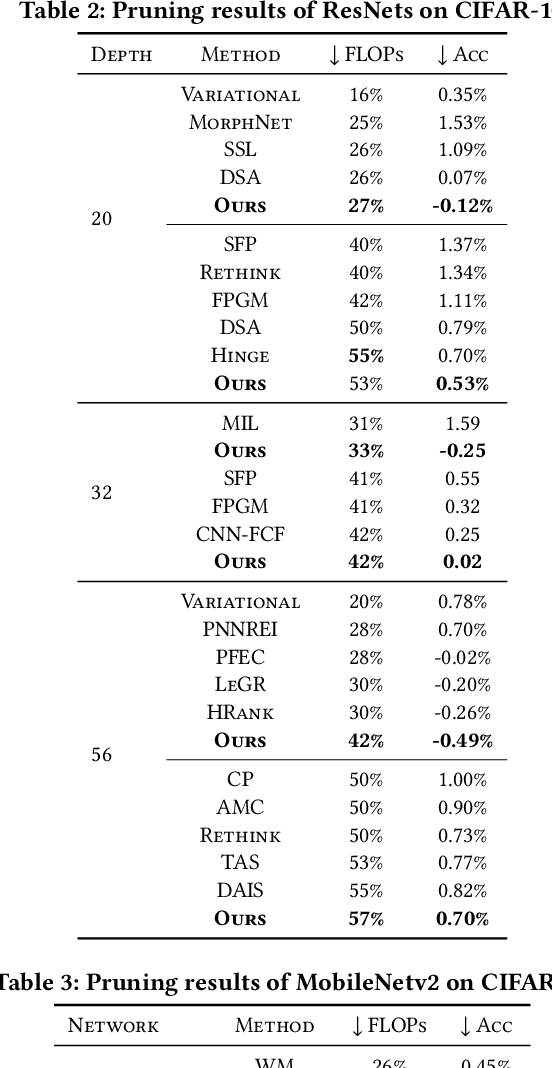

Model pruning aims to reduce the deep neural network (DNN) model size or computational overhead. Traditional model pruning methods such as l-1 pruning that evaluates the channel significance for DNN pay too much attention to the local analysis of each channel and make use of the magnitude of the entire feature while ignoring its relevance to the batch normalization (BN) and ReLU layer after each convolutional operation. To overcome these problems, we propose a new model pruning method from a new perspective of gradient flow in this paper. Specifically, we first theoretically analyze the channel's influence based on Taylor expansion by integrating the effects of BN layer and ReLU activation function. Then, the incorporation of the first-order Talyor polynomial of the scaling parameter and the shifting parameter in the BN layer is suggested to effectively indicate the significance of a channel in a DNN. Comprehensive experiments on both image classification and image denoising tasks demonstrate the superiority of the proposed novel theory and scheme. Code is available at https://github.com/CityU-AIM-Group/GFBS.
Learning-based Fast Path Planning in Complex Environments
Oct 19, 2021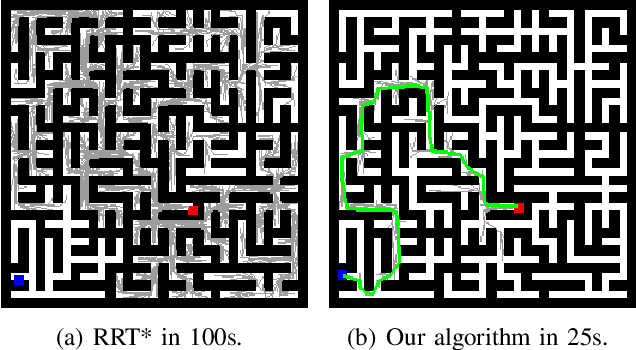
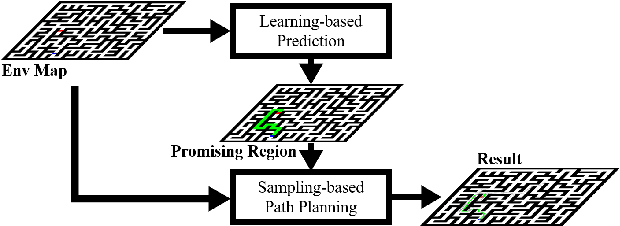
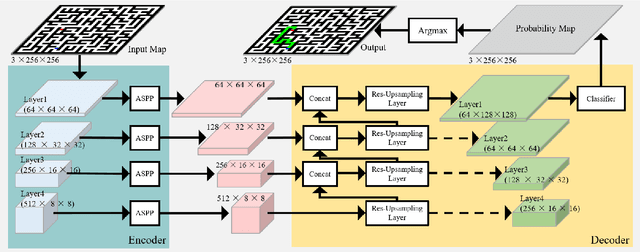
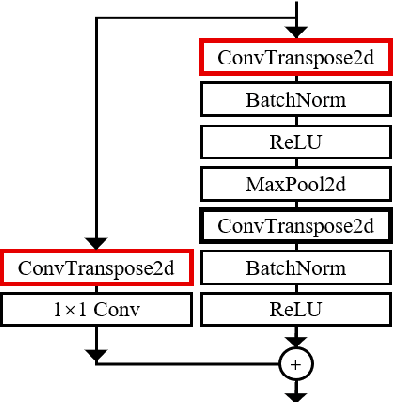
In this paper, we present a novel path planning algorithm to achieve fast path planning in complex environments. Most existing path planning algorithms are difficult to quickly find a feasible path in complex environments or even fail. However, our proposed framework can overcome this difficulty by using a learning-based prediction module and a sampling-based path planning module. The prediction module utilizes an auto-encoder-decoder-like convolutional neural network (CNN) to output a promising region where the feasible path probably lies in. In this process, the environment is treated as an RGB image to feed in our designed CNN module, and the output is also an RGB image. No extra computation is required so that we can maintain a high processing speed of 60 frames-per-second (FPS). Incorporated with a sampling-based path planner, we can extract a feasible path from the output image so that the robot can track it from start to goal. To demonstrate the advantage of the proposed algorithm, we compare it with conventional path planning algorithms in a series of simulation experiments. The results reveal that the proposed algorithm can achieve much better performance in terms of planning time, success rate, and path length.
BN-NAS: Neural Architecture Search with Batch Normalization
Aug 16, 2021
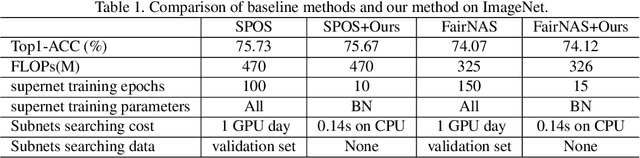
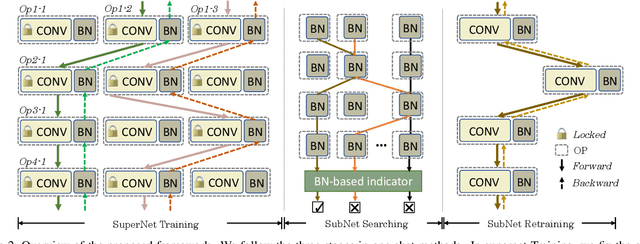
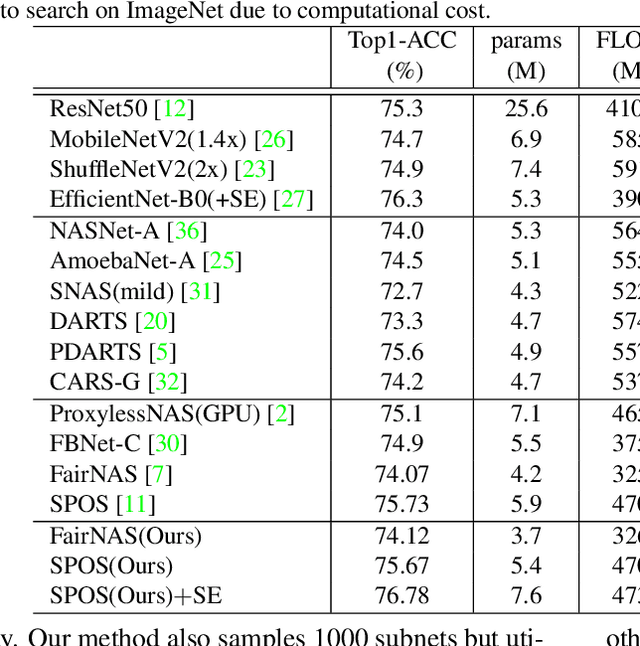
We present BN-NAS, neural architecture search with Batch Normalization (BN-NAS), to accelerate neural architecture search (NAS). BN-NAS can significantly reduce the time required by model training and evaluation in NAS. Specifically, for fast evaluation, we propose a BN-based indicator for predicting subnet performance at a very early training stage. The BN-based indicator further facilitates us to improve the training efficiency by only training the BN parameters during the supernet training. This is based on our observation that training the whole supernet is not necessary while training only BN parameters accelerates network convergence for network architecture search. Extensive experiments show that our method can significantly shorten the time of training supernet by more than 10 times and shorten the time of evaluating subnets by more than 600,000 times without losing accuracy.
PSViT: Better Vision Transformer via Token Pooling and Attention Sharing
Aug 07, 2021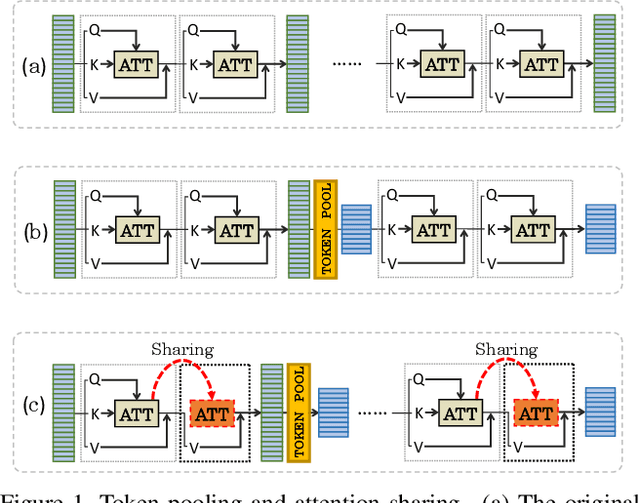
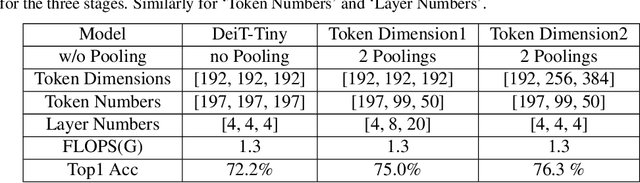
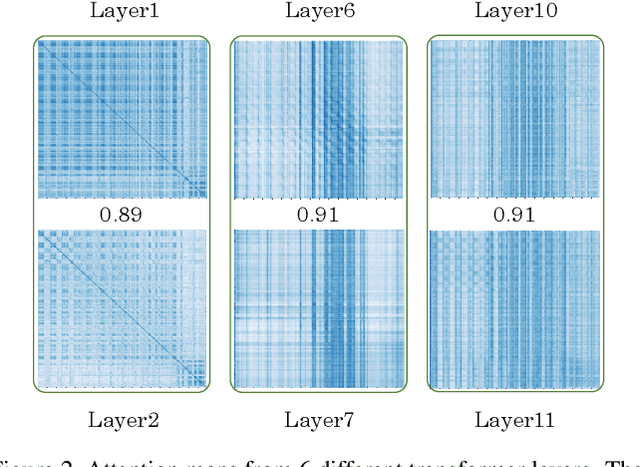
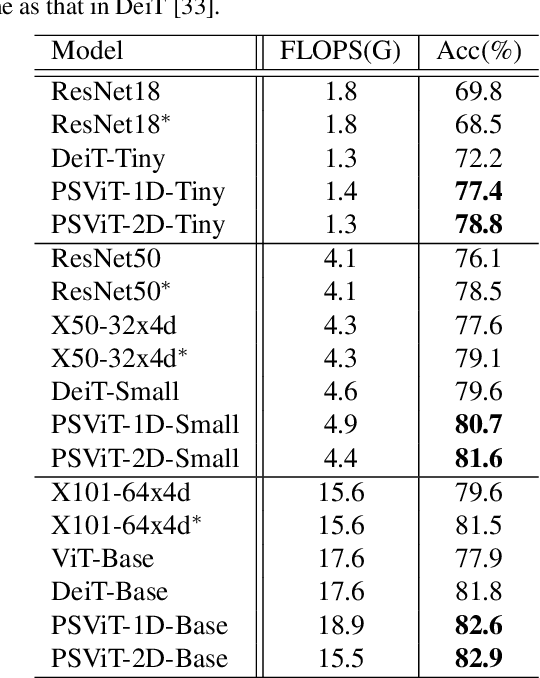
In this paper, we observe two levels of redundancies when applying vision transformers (ViT) for image recognition. First, fixing the number of tokens through the whole network produces redundant features at the spatial level. Second, the attention maps among different transformer layers are redundant. Based on the observations above, we propose a PSViT: a ViT with token Pooling and attention Sharing to reduce the redundancy, effectively enhancing the feature representation ability, and achieving a better speed-accuracy trade-off. Specifically, in our PSViT, token pooling can be defined as the operation that decreases the number of tokens at the spatial level. Besides, attention sharing will be built between the neighboring transformer layers for reusing the attention maps having a strong correlation among adjacent layers. Then, a compact set of the possible combinations for different token pooling and attention sharing mechanisms are constructed. Based on the proposed compact set, the number of tokens in each layer and the choices of layers sharing attention can be treated as hyper-parameters that are learned from data automatically. Experimental results show that the proposed scheme can achieve up to 6.6% accuracy improvement in ImageNet classification compared with the DeiT.
GLiT: Neural Architecture Search for Global and Local Image Transformer
Jul 07, 2021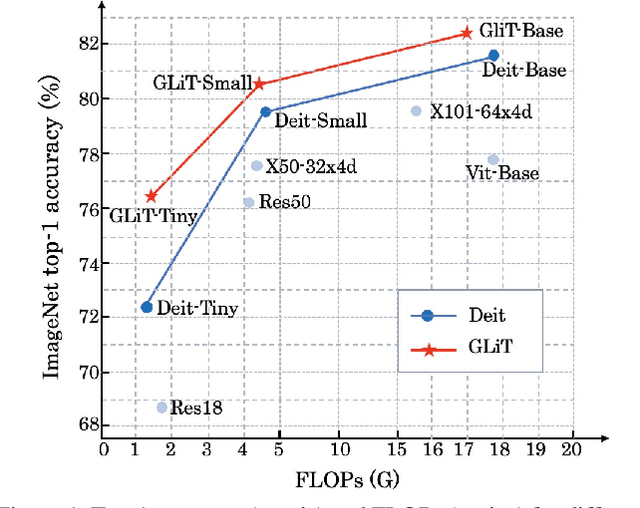
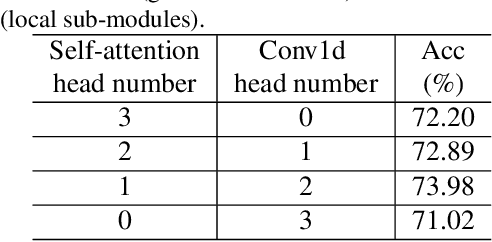
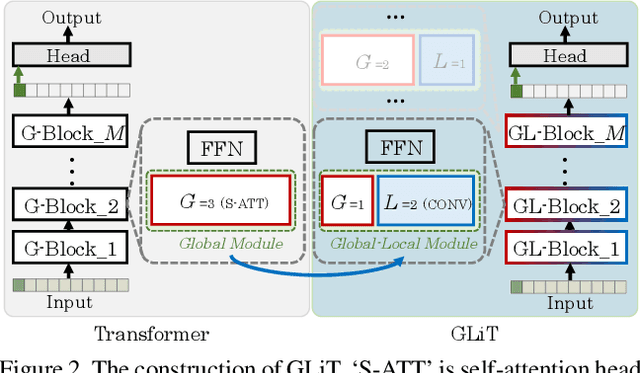

We introduce the first Neural Architecture Search (NAS) method to find a better transformer architecture for image recognition. Recently, transformers without CNN-based backbones are found to achieve impressive performance for image recognition. However, the transformer is designed for NLP tasks and thus could be sub-optimal when directly used for image recognition. In order to improve the visual representation ability for transformers, we propose a new search space and searching algorithm. Specifically, we introduce a locality module that models the local correlations in images explicitly with fewer computational cost. With the locality module, our search space is defined to let the search algorithm freely trade off between global and local information as well as optimizing the low-level design choice in each module. To tackle the problem caused by huge search space, a hierarchical neural architecture search method is proposed to search the optimal vision transformer from two levels separately with the evolutionary algorithm. Extensive experiments on the ImageNet dataset demonstrate that our method can find more discriminative and efficient transformer variants than the ResNet family (e.g., ResNet101) and the baseline ViT for image classification.