 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptFusion: Open-set Multimodal 3D Mapping
Feb 15, 2023Building 3D maps of the environment is central to robot navigation, planning, and interaction with objects in a scene. Most existing approaches that integrate semantic concepts with 3D maps largely remain confined to the closed-set setting: they can only reason about a finite set of concepts, pre-defined at training time. Further, these maps can only be queried using class labels, or in recent work, using text prompts. We address both these issues with ConceptFusion, a scene representation that is (1) fundamentally open-set, enabling reasoning beyond a closed set of concepts and (ii) inherently multimodal, enabling a diverse range of possible queries to the 3D map, from language, to images, to audio, to 3D geometry, all working in concert. ConceptFusion leverages the open-set capabilities of today's foundation models pre-trained on internet-scale data to reason about concepts across modalities such as natural language, images, and audio. We demonstrate that pixel-aligned open-set features can be fused into 3D maps via traditional SLAM and multi-view fusion approaches. This enables effective zero-shot spatial reasoning, not needing any additional training or finetuning, and retains long-tailed concepts better than supervised approaches, outperforming them by more than 40% margin on 3D IoU. We extensively evaluate ConceptFusion on a number of real-world datasets, simulated home environments, a real-world tabletop manipulation task, and an autonomous driving platform. We showcase new avenues for blending foundation models with 3D open-set multimodal mapping. For more information, visit our project page https://concept-fusion.github.io or watch our 5-minute explainer video https://www.youtube.com/watch?v=rkXgws8fiDs
Debiasing Vision-Language Models via Biased Prompts
Jan 31, 2023



Machine learning models have been shown to inherit biases from their training datasets, which can be particularly problematic for vision-language foundation models trained on uncurated datasets scraped from the internet. The biases can be amplified and propagated to downstream applications like zero-shot classifiers and text-to-image generative models. In this study, we propose a general approach for debiasing vision-language foundation models by projecting out biased directions in the text embedding. In particular, we show that debiasing only the text embedding with a calibrated projection matrix suffices to yield robust classifiers and fair generative models. The closed-form solution enables easy integration into large-scale pipelines, and empirical results demonstrate that our approach effectively reduces social bias and spurious correlation in both discriminative and generative vision-language models without the need for additional data or training.
NOPA: Neurally-guided Online Probabilistic Assistance for Building Socially Intelligent Home Assistants
Jan 12, 2023In this work, we study how to build socially intelligent robots to assist people in their homes. In particular, we focus on assistance with online goal inference, where robots must simultaneously infer humans' goals and how to help them achieve those goals. Prior assistance methods either lack the adaptivity to adjust helping strategies (i.e., when and how to help) in response to uncertainty about goals or the scalability to conduct fast inference in a large goal space. Our NOPA (Neurally-guided Online Probabilistic Assistance) method addresses both of these challenges. NOPA consists of (1) an online goal inference module combining neural goal proposals with inverse planning and particle filtering for robust inference under uncertainty, and (2) a helping planner that discovers valuable subgoals to help with and is aware of the uncertainty in goal inference. We compare NOPA against multiple baselines in a new embodied AI assistance challenge: Online Watch-And-Help, in which a helper agent needs to simultaneously watch a main agent's action, infer its goal, and help perform a common household task faster in realistic virtual home environments. Experiments show that our helper agent robustly updates its goal inference and adapts its helping plans to the changing level of uncertainty.
Aliasing is a Driver of Adversarial Attacks
Dec 22, 2022Aliasing is a highly important concept in signal processing, as careful consideration of resolution changes is essential in ensuring transmission and processing quality of audio, image, and video. Despite this, up until recently aliasing has received very little consideration in Deep Learning, with all common architectures carelessly sub-sampling without considering aliasing effects. In this work, we investigate the hypothesis that the existence of adversarial perturbations is due in part to aliasing in neural networks. Our ultimate goal is to increase robustness against adversarial attacks using explainable, non-trained, structural changes only, derived from aliasing first principles. Our contributions are the following. First, we establish a sufficient condition for no aliasing for general image transformations. Next, we study sources of aliasing in common neural network layers, and derive simple modifications from first principles to eliminate or reduce it. Lastly, our experimental results show a solid link between anti-aliasing and adversarial attacks. Simply reducing aliasing already results in more robust classifiers, and combining anti-aliasing with robust training out-performs solo robust training on $L_2$ attacks with none or minimal losses in performance on $L_{\infty}$ attacks.
Procedural Image Programs for Representation Learning
Nov 29, 2022



Learning image representations using synthetic data allows training neural networks without some of the concerns associated with real images, such as privacy and bias. Existing work focuses on a handful of curated generative processes which require expert knowledge to design, making it hard to scale up. To overcome this, we propose training with a large dataset of twenty-one thousand programs, each one generating a diverse set of synthetic images. These programs are short code snippets, which are easy to modify and fast to execute using OpenGL. The proposed dataset can be used for both supervised and unsupervised representation learning, and reduces the gap between pre-training with real and procedurally generated images by 38%.
* 29 pages, Accepted in the Conference on Neural Information Processing Systems 2022 (NeurIPS 2022)
$BT^2$: Backward-compatible Training with Basis Transformation
Nov 08, 2022



Modern retrieval system often requires recomputing the representation of every piece of data in the gallery when updating to a better representation model. This process is known as backfilling and can be especially costly in the real world where the gallery often contains billions of samples. Recently, researchers have proposed the idea of Backward Compatible Training (BCT) where the new representation model can be trained with an auxiliary loss to make it backward compatible with the old representation. In this way, the new representation can be directly compared with the old representation, in principle avoiding the need for any backfilling. However, followup work shows that there is an inherent tradeoff where a backward compatible representation model cannot simultaneously maintain the performance of the new model itself. This paper reports our ``not-so-surprising'' finding that adding extra dimensions to the representation can help here. However, we also found that naively increasing the dimension of the representation did not work. To deal with this, we propose Backward-compatible Training with a novel Basis Transformation ($BT^2$). A basis transformation (BT) is basically a learnable set of parameters that applies an orthonormal transformation. Such a transformation possesses an important property whereby the original information contained in its input is retained in its output. We show in this paper how a BT can be utilized to add only the necessary amount of additional dimensions. We empirically verify the advantage of $BT^2$ over other state-of-the-art methods in a wide range of settings. We then further extend $BT^2$ to other challenging yet more practical settings, including significant change in model architecture (CNN to Transformers), modality change, and even a series of updates in the model architecture mimicking the evolution of deep learning models.
Totems: Physical Objects for Verifying Visual Integrity
Sep 26, 2022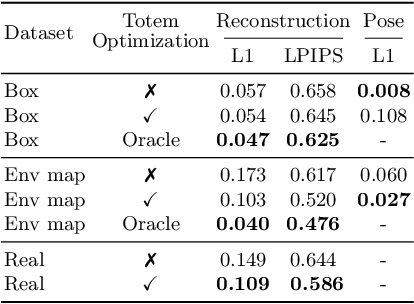
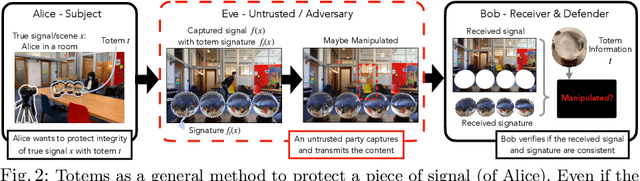

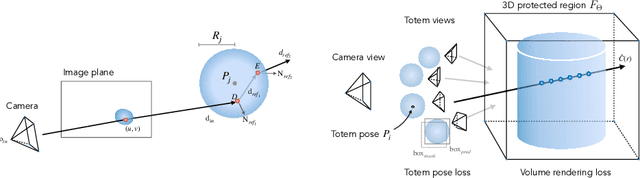
We introduce a new approach to image forensics: placing physical refractive objects, which we call totems, into a scene so as to protect any photograph taken of that scene. Totems bend and redirect light rays, thus providing multiple, albeit distorted, views of the scene within a single image. A defender can use these distorted totem pixels to detect if an image has been manipulated. Our approach unscrambles the light rays passing through the totems by estimating their positions in the scene and using their known geometric and material properties. To verify a totem-protected image, we detect inconsistencies between the scene reconstructed from totem viewpoints and the scene's appearance from the camera viewpoint. Such an approach makes the adversarial manipulation task more difficult, as the adversary must modify both the totem and image pixels in a geometrically consistent manner without knowing the physical properties of the totem. Unlike prior learning-based approaches, our method does not require training on datasets of specific manipulations, and instead uses physical properties of the scene and camera to solve the forensics problem.
Denoised MDPs: Learning World Models Better Than the World Itself
Jul 18, 2022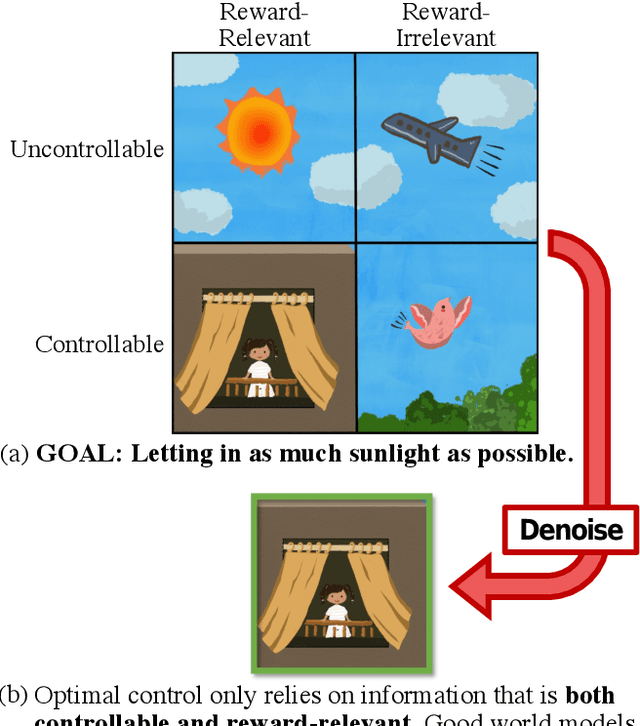
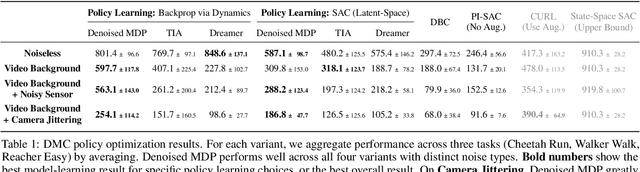
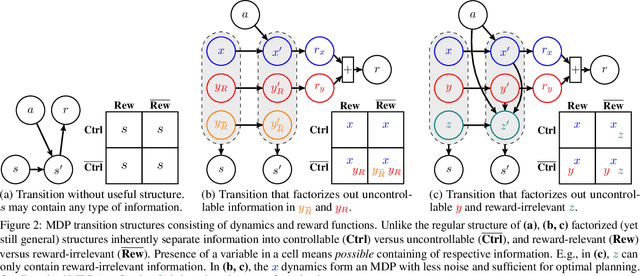
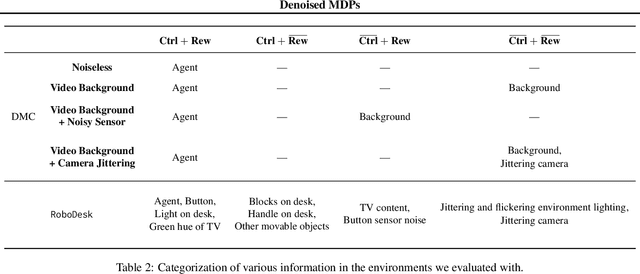
The ability to separate signal from noise, and reason with clean abstractions, is critical to intelligence. With this ability, humans can efficiently perform real world tasks without considering all possible nuisance factors.How can artificial agents do the same? What kind of information can agents safely discard as noises? In this work, we categorize information out in the wild into four types based on controllability and relation with reward, and formulate useful information as that which is both controllable and reward-relevant. This framework clarifies the kinds information removed by various prior work on representation learning in reinforcement learning (RL), and leads to our proposed approach of learning a Denoised MDP that explicitly factors out certain noise distractors. Extensive experiments on variants of DeepMind Control Suite and RoboDesk demonstrate superior performance of our denoised world model over using raw observations alone, and over prior works, across policy optimization control tasks as well as the non-control task of joint position regression.
Finding Fallen Objects Via Asynchronous Audio-Visual Integration
Jul 07, 2022
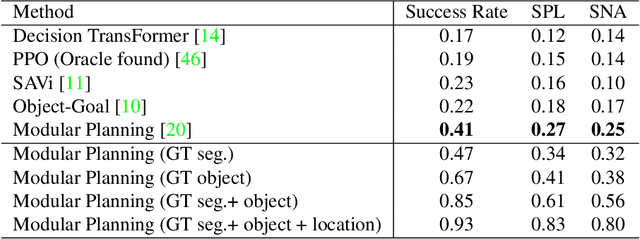

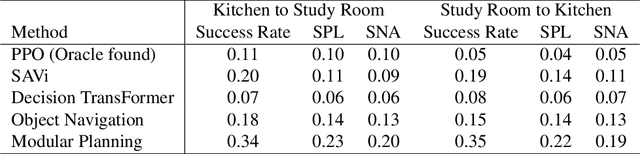
The way an object looks and sounds provide complementary reflections of its physical properties. In many settings cues from vision and audition arrive asynchronously but must be integrated, as when we hear an object dropped on the floor and then must find it. In this paper, we introduce a setting in which to study multi-modal object localization in 3D virtual environments. An object is dropped somewhere in a room. An embodied robot agent, equipped with a camera and microphone, must determine what object has been dropped -- and where -- by combining audio and visual signals with knowledge of the underlying physics. To study this problem, we have generated a large-scale dataset -- the Fallen Objects dataset -- that includes 8000 instances of 30 physical object categories in 64 rooms. The dataset uses the ThreeDWorld platform which can simulate physics-based impact sounds and complex physical interactions between objects in a photorealistic setting. As a first step toward addressing this challenge, we develop a set of embodied agent baselines, based on imitation learning, reinforcement learning, and modular planning, and perform an in-depth analysis of the challenge of this new task.
Local Relighting of Real Scenes
Jul 06, 2022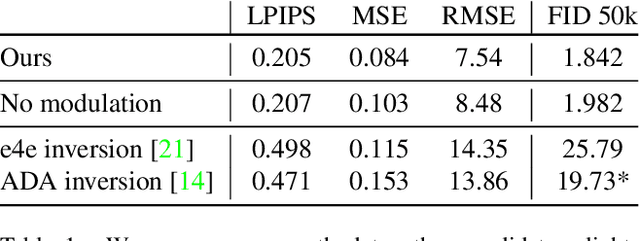

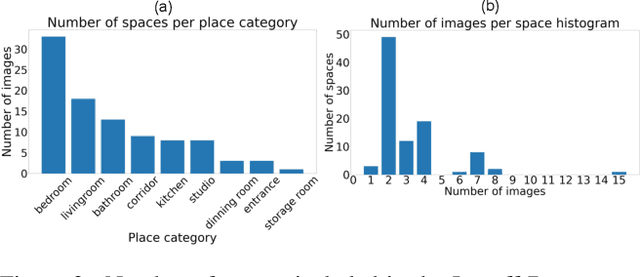
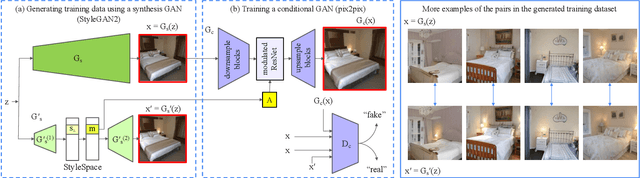
We introduce the task of local relighting, which changes a photograph of a scene by switching on and off the light sources that are visible within the image. This new task differs from the traditional image relighting problem, as it introduces the challenge of detecting light sources and inferring the pattern of light that emanates from them. We propose an approach for local relighting that trains a model without supervision of any novel image dataset by using synthetically generated image pairs from another model. Concretely, we collect paired training images from a stylespace-manipulated GAN; then we use these images to train a conditional image-to-image model. To benchmark local relighting, we introduce Lonoff, a collection of 306 precisely aligned images taken in indoor spaces with different combinations of lights switched on. We show that our method significantly outperforms baseline methods based on GAN inversion. Finally, we demonstrate extensions of our method that control different light sources separately. We invite the community to tackle this new task of local relighting.