 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow What and Know Where: An Object-and-Room Informed Sequential BERT for Indoor Vision-Language Navigation
Apr 09, 2021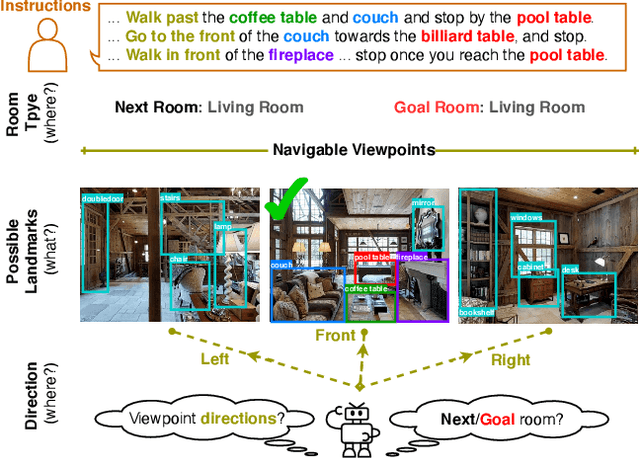

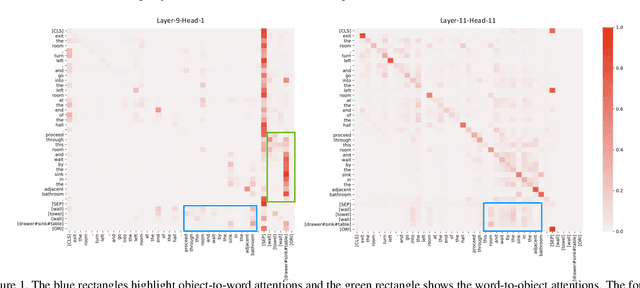
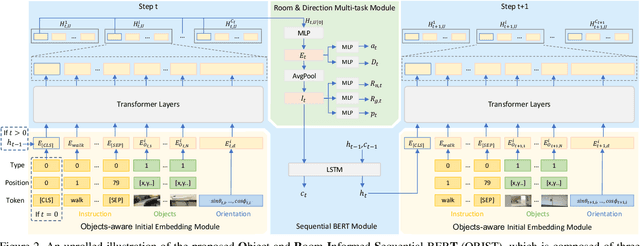
Vision-and-Language Navigation (VLN) requires an agent to navigate to a remote location on the basis of natural-language instructions and a set of photo-realistic panoramas. Most existing methods take words in instructions and discrete views of each panorama as the minimal unit of encoding. However, this requires a model to match different textual landmarks in instructions (e.g., TV, table) against the same view feature. In this work, we propose an object-informed sequential BERT to encode visual perceptions and linguistic instructions at the same fine-grained level, namely objects and words, to facilitate the matching between visual and textual entities and hence "know what". Our sequential BERT enables the visual-textual clues to be interpreted in light of the temporal context, which is crucial to multi-round VLN tasks. Additionally, we enable the model to identify the relative direction (e.g., left/right/front/back) of each navigable location and the room type (e.g., bedroom, kitchen) of its current and final navigation goal, namely "know where", as such information is widely mentioned in instructions implying the desired next and final locations. Extensive experiments demonstrate the effectiveness compared against several state-of-the-art methods on three indoor VLN tasks: REVERIE, NDH, and R2R.
Reasoning over Vision and Language: Exploring the Benefits of Supplemental Knowledge
Jan 15, 2021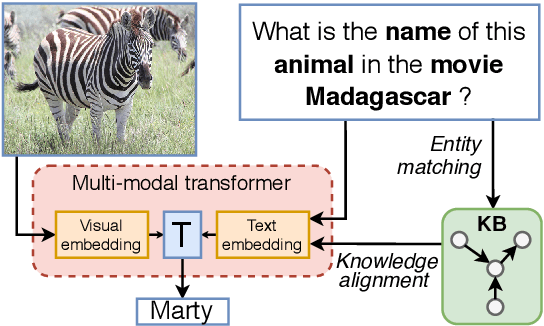
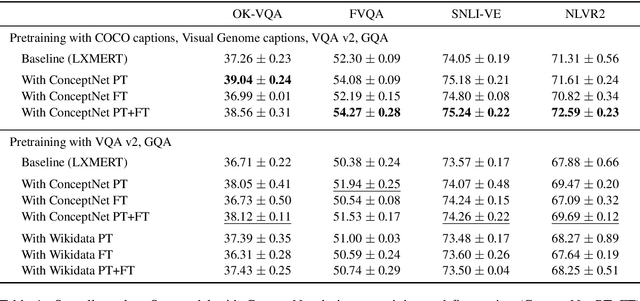
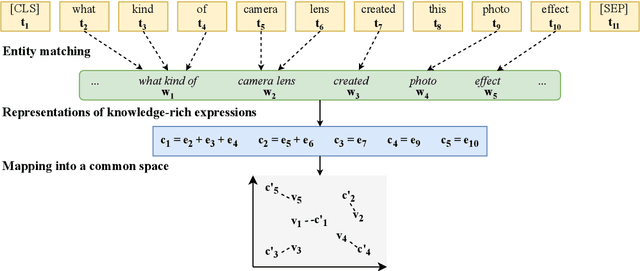
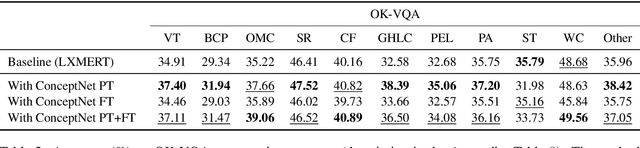
The limits of applicability of vision-and-language models are defined by the coverage of their training data. Tasks like vision question answering (VQA) often require commonsense and factual information beyond what can be learned from task-specific datasets. This paper investigates the injection of knowledge from general-purpose knowledge bases (KBs) into vision-and-language transformers. We use an auxiliary training objective that encourages the learned representations to align with graph embeddings of matching entities in a KB. We empirically study the relevance of various KBs to multiple tasks and benchmarks. The technique brings clear benefits to knowledge-demanding question answering tasks (OK-VQA, FVQA) by capturing semantic and relational knowledge absent from existing models. More surprisingly, the technique also benefits visual reasoning tasks (NLVR2, SNLI-VE). We perform probing experiments and show that the injection of additional knowledge regularizes the space of embeddings, which improves the representation of lexical and semantic similarities. The technique is model-agnostic and can expand the applicability of any vision-and-language transformer with minimal computational overhead.
Deep Multi-task Learning for Depression Detection and Prediction in Longitudinal Data
Dec 05, 2020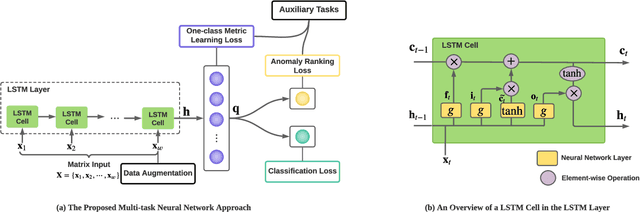
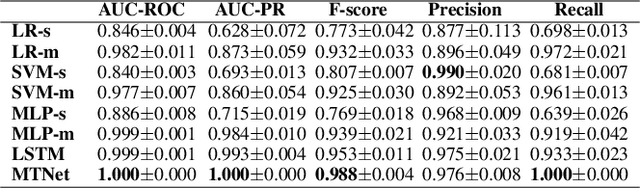
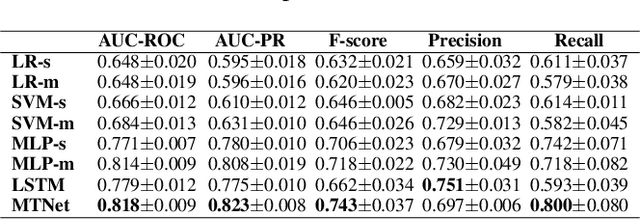
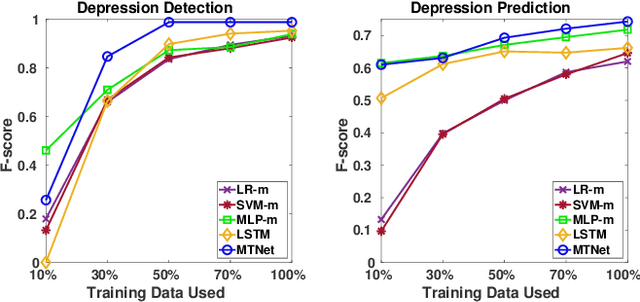
Depression is among the most prevalent mental disorders, affecting millions of people of all ages globally. Machine learning techniques have shown effective in enabling automated detection and prediction of depression for early intervention and treatment. However, they are challenged by the relative scarcity of instances of depression in the data. In this work we introduce a novel deep multi-task recurrent neural network to tackle this challenge, in which depression classification is jointly optimized with two auxiliary tasks, namely one-class metric learning and anomaly ranking. The auxiliary tasks introduce an inductive bias that improves the classification model's generalizability on small depression samples. Further, unlike existing studies that focus on learning depression signs from static data without considering temporal dynamics, we focus on longitudinal data because i) temporal changes in personal development and family environment can provide critical cues for psychiatric disorders and ii) it may enable us to predict depression before the illness actually occurs. Extensive experimental results on child depression data show that our model is able to i) achieve nearly perfect performance in depression detection and ii) accurately predict depression 2-4 years before the clinical diagnosis, substantially outperforming seven competing methods.
DyCo3D: Robust Instance Segmentation of 3D Point Clouds through Dynamic Convolution
Nov 26, 2020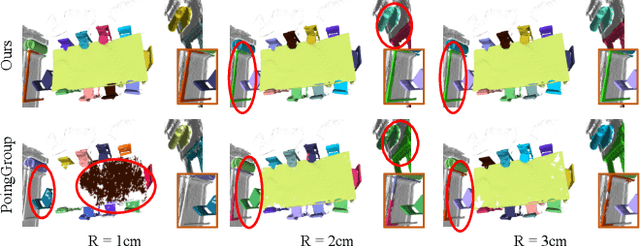

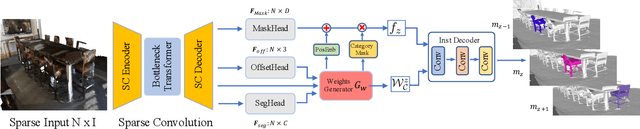
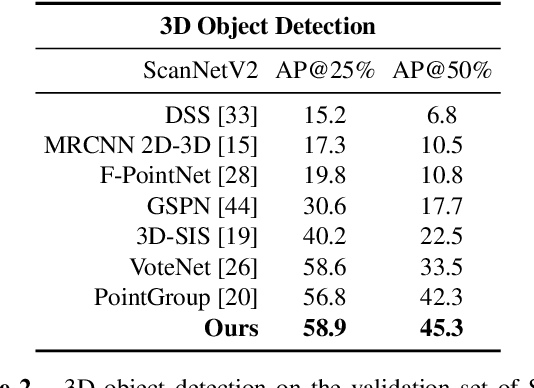
Previous top-performing approaches for point cloud instance segmentation involve a bottom-up strategy, which often includes inefficient operations or complex pipelines, such as grouping over-segmented components, introducing additional steps for refining, or designing complicated loss functions. The inevitable variation in the instance scales can lead bottom-up methods to become particularly sensitive to hyper-parameter values. To this end, we propose instead a dynamic, proposal-free, data-driven approach that generates the appropriate convolution kernels to apply in response to the nature of the instances. To make the kernels discriminative, we explore a large context by gathering homogeneous points that share identical semantic categories and have close votes for the geometric centroids. Instances are then decoded by several simple convolutional layers. Due to the limited receptive field introduced by the sparse convolution, a small light-weight transformer is also devised to capture the long-range dependencies and high-level interactions among point samples. The proposed method achieves promising results on both ScanetNetV2 and S3DIS, and this performance is robust to the particular hyper-parameter values chosen. It also improves inference speed by more than 25% over the current state-of-the-art. Code is available at: https://git.io/DyCo3D
Deep Reinforcement Learning for Unknown Anomaly Detection
Sep 15, 2020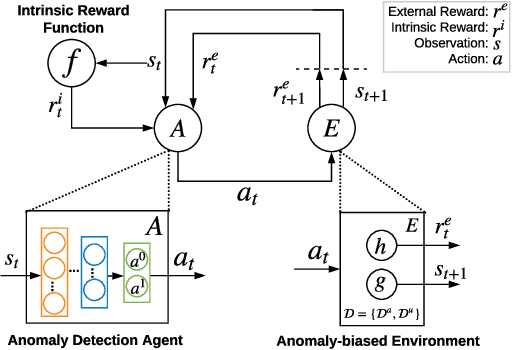

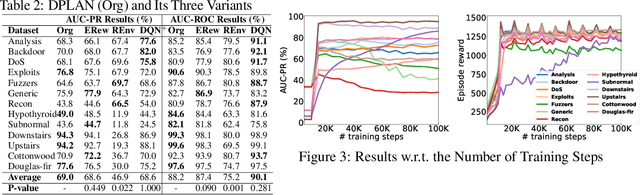
We address a critical yet largely unsolved anomaly detection problem, in which we aim to learn detection models from a small set of partially labeled anomalies and a large-scale unlabeled dataset. This is a common scenario in many important applications. Existing related methods either proceed unsupervised with the unlabeled data, or exclusively fit the limited anomaly examples that often do not span the entire set of anomalies. We propose here instead a deep reinforcement-learning-based approach that actively seeks novel classes of anomaly that lie beyond the scope of the labeled training data. This approach learns to balance exploiting its existing data model against exploring for new classes of anomaly. It is thus able to exploit the labeled anomaly data to improve detection accuracy, without limiting the set of anomalies sought to those given anomaly examples. This is of significant practical benefit, as anomalies are inevitably unpredictable in form and often expensive to miss. Extensive experiments on 48 real-world datasets show that our approach significantly outperforms five state-of-the-art competing methods.
Object-and-Action Aware Model for Visual Language Navigation
Jul 29, 2020
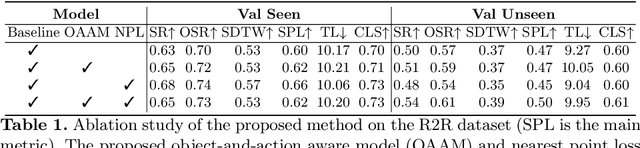
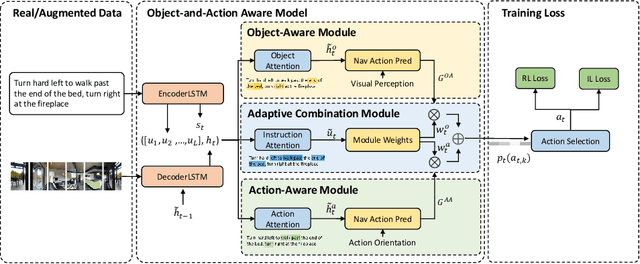
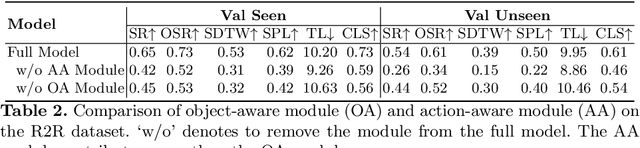
Vision-and-Language Navigation (VLN) is unique in that it requires turning relatively general natural-language instructions into robot agent actions, on the basis of the visible environment. This requires to extract value from two very different types of natural-language information. The first is object description (e.g., 'table', 'door'), each presenting as a tip for the agent to determine the next action by finding the item visible in the environment, and the second is action specification (e.g., 'go straight', 'turn left') which allows the robot to directly predict the next movements without relying on visual perceptions. However, most existing methods pay few attention to distinguish these information from each other during instruction encoding and mix together the matching between textual object/action encoding and visual perception/orientation features of candidate viewpoints. In this paper, we propose an Object-and-Action Aware Model (OAAM) that processes these two different forms of natural language based instruction separately. This enables each process to match object-centered/action-centered instruction to their own counterpart visual perception/action orientation flexibly. However, one side-issue caused by above solution is that an object mentioned in instructions may be observed in the direction of two or more candidate viewpoints, thus the OAAM may not predict the viewpoint on the shortest path as the next action. To handle this problem, we design a simple but effective path loss to penalize trajectories deviating from the ground truth path. Experimental results demonstrate the effectiveness of the proposed model and path loss, and the superiority of their combination with a 50% SPL score on the R2R dataset and a 40% CLS score on the R4R dataset in unseen environments, outperforming the previous state-of-the-art.
Deep Learning for Anomaly Detection: A Review
Jul 08, 2020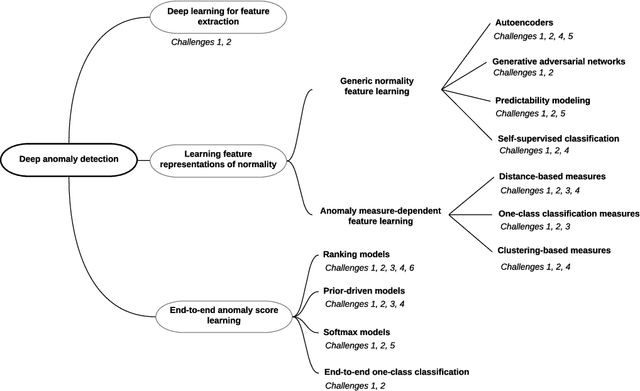
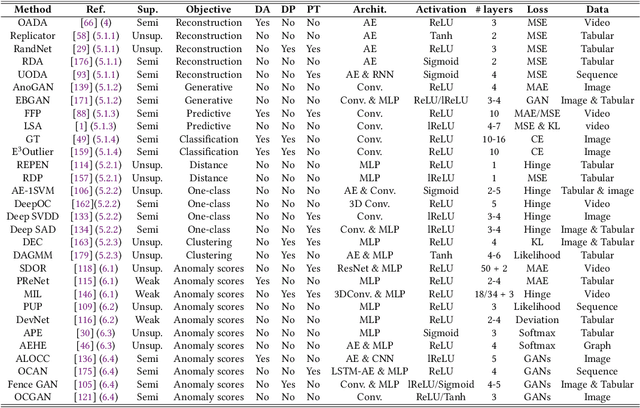
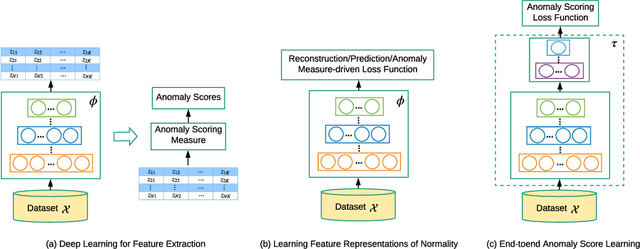
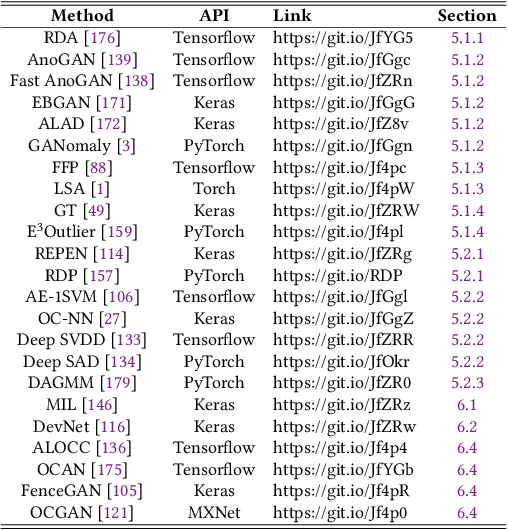
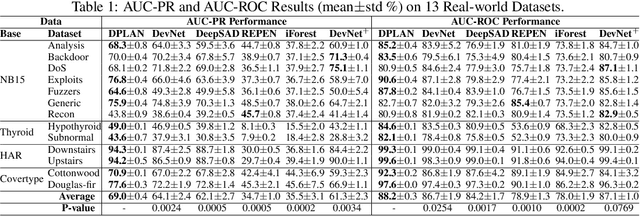
Anomaly detection, a.k.a. outlier detection, has been a lasting yet active research area in various research communities for several decades. There are still some unique problem complexities and challenges that require advanced approaches. In recent years, deep learning enabled anomaly detection, i.e., deep anomaly detection, has emerged as a critical direction. This paper reviews the research of deep anomaly detection with a comprehensive taxonomy of detection methods, covering advancements in three high-level categories and 11 fine-grained categories of the methods. We review their key intuitions, objective functions, underlying assumptions, advantages and disadvantages, and discuss how they address the aforementioned challenges. We further discuss a set of possible future opportunities and new perspectives on addressing the challenges.
Structured Multimodal Attentions for TextVQA
Jun 01, 2020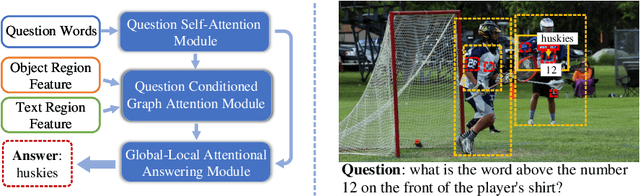
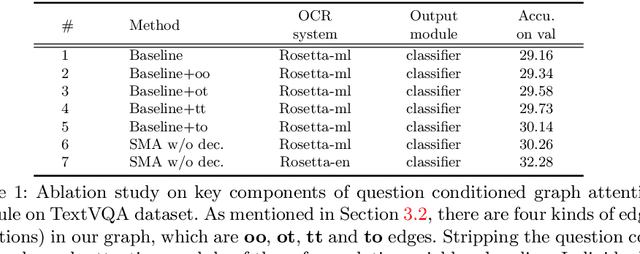
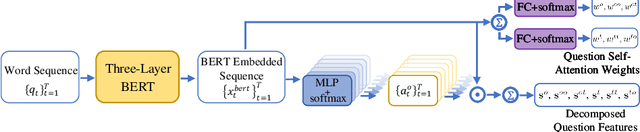

Text based Visual Question Answering (TextVQA) is a recently raised challenge that requires a machine to read text in images and answer natural language questions by jointly reasoning over the question, Optical Character Recognition (OCR) tokens and visual content. Most of the state-of-the-art (SoTA) VQA methods fail to answer these questions because of i) poor text reading ability; ii) lacking of text-visual reasoning capacity; and iii) adopting a discriminative answering mechanism instead of a generative one which is hard to cover both OCR tokens and general text tokens in the final answer. In this paper, we propose a structured multimodal attention (SMA) neural network to solve the above issues. Our SMA first uses a structural graph representation to encode the object-object, object-text and text-text relationships appearing in the image, and then design a multimodal graph attention network to reason over it. Finally, the outputs from the above module are processed by a global-local attentional answering module to produce an answer that covers tokens from both OCR and general text iteratively. Our proposed model outperforms the SoTA models on TextVQA dataset and all three tasks of ST-VQA dataset. To provide an upper bound for our method and a fair testing base for further works, we also provide human-annotated ground-truth OCR annotations for the TextVQA dataset, which were not given in the original release.
On the Value of Out-of-Distribution Testing: An Example of Goodhart's Law
May 19, 2020Out-of-distribution (OOD) testing is increasingly popular for evaluating a machine learning system's ability to generalize beyond the biases of a training set. OOD benchmarks are designed to present a different joint distribution of data and labels between training and test time. VQA-CP has become the standard OOD benchmark for visual question answering, but we discovered three troubling practices in its current use. First, most published methods rely on explicit knowledge of the construction of the OOD splits. They often rely on ``inverting'' the distribution of labels, e.g. answering mostly 'yes' when the common training answer is 'no'. Second, the OOD test set is used for model selection. Third, a model's in-domain performance is assessed after retraining it on in-domain splits (VQA v2) that exhibit a more balanced distribution of labels. These three practices defeat the objective of evaluating generalization, and put into question the value of methods specifically designed for this dataset. We show that embarrassingly-simple methods, including one that generates answers at random, surpass the state of the art on some question types. We provide short- and long-term solutions to avoid these pitfalls and realize the benefits of OOD evaluation.
Visual Question Answering with Prior Class Semantics
May 04, 2020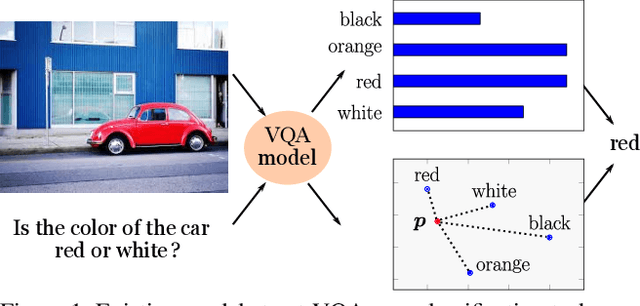
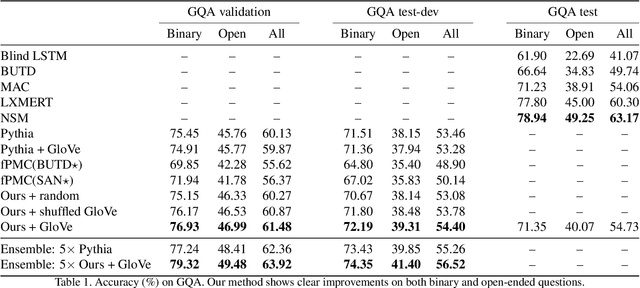
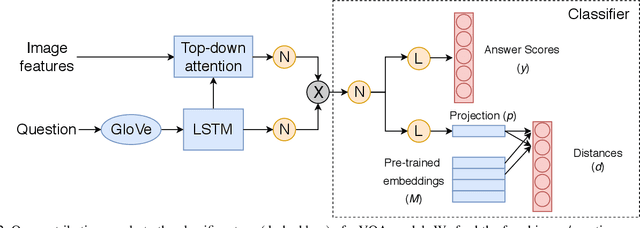
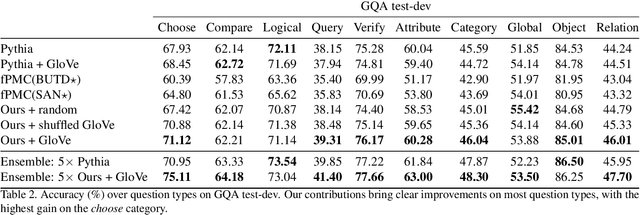
We present a novel mechanism to embed prior knowledge in a model for visual question answering. The open-set nature of the task is at odds with the ubiquitous approach of training of a fixed classifier. We show how to exploit additional information pertaining to the semantics of candidate answers. We extend the answer prediction process with a regression objective in a semantic space, in which we project candidate answers using prior knowledge derived from word embeddings. We perform an extensive study of learned representations with the GQA dataset, revealing that important semantic information is captured in the relations between embeddings in the answer space. Our method brings improvements in consistency and accuracy over a range of question types. Experiments with novel answers, unseen during training, indicate the method's potential for open-set prediction.