 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Diagnosis and Segmentation Learning from Cardiac Magnetic Resonance Imaging
Oct 23, 2018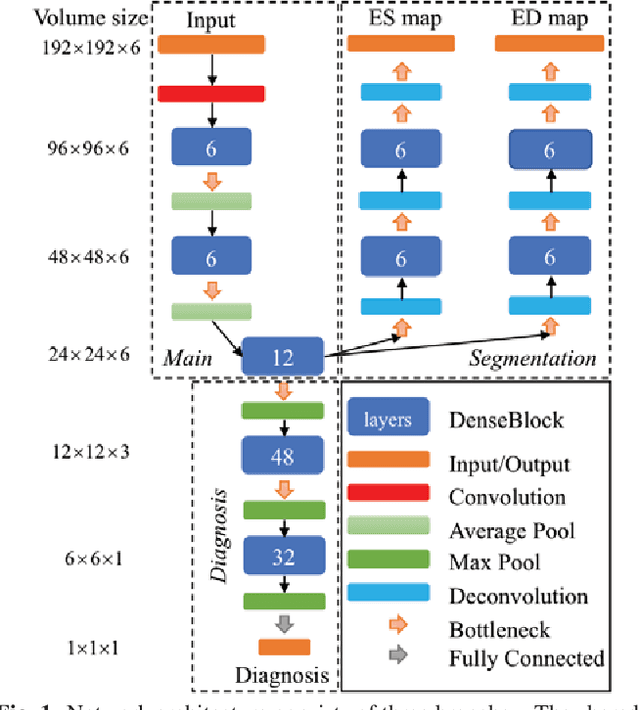
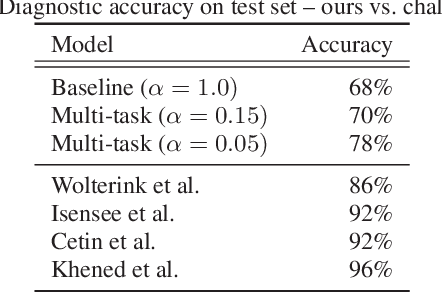
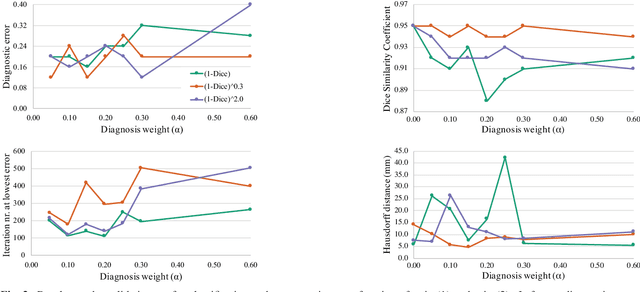
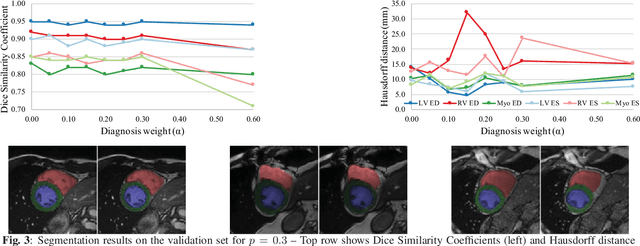
Cardiac magnetic resonance (CMR) is used extensively in the diagnosis and management of cardiovascular disease. Deep learning methods have proven to deliver segmentation results comparable to human experts in CMR imaging, but there have been no convincing results for the problem of end-to-end segmentation and diagnosis from CMR. This is in part due to a lack of sufficiently large datasets required to train robust diagnosis models. In this paper, we propose a learning method to train diagnosis models, where our approach is designed to work with relatively small datasets. In particular, the optimisation loss is based on multi-task learning that jointly trains for the tasks of segmentation and diagnosis classification. We hypothesize that segmentation has a regularizing effect on the learning of features relevant for diagnosis. Using the 100 training and 50 testing samples available from the Automated Cardiac Diagnosis Challenge (ACDC) dataset, which has a balanced distribution of 5 cardiac diagnoses, we observe a reduction of the classification error from 32% to 22%, and a faster convergence compared to a baseline without segmentation. To the best of our knowledge, this is the best diagnosis results from CMR using an end-to-end diagnosis and segmentation learning method.
MPTV: Matching Pursuit Based Total Variation Minimization for Image Deconvolution
Oct 12, 2018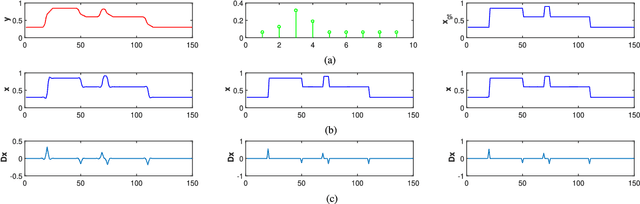



Total variation (TV) regularization has proven effective for a range of computer vision tasks through its preferential weighting of sharp image edges. Existing TV-based methods, however, often suffer from the over-smoothing issue and solution bias caused by the homogeneous penalization. In this paper, we consider addressing these issues by applying inhomogeneous regularization on different image components. We formulate the inhomogeneous TV minimization problem as a convex quadratic constrained linear programming problem. Relying on this new model, we propose a matching pursuit based total variation minimization method (MPTV), specifically for image deconvolution. The proposed MPTV method is essentially a cutting-plane method, which iteratively activates a subset of nonzero image gradients, and then solves a subproblem focusing on those activated gradients only. Compared to existing methods, MPTV is less sensitive to the choice of the trade-off parameter between data fitting and regularization. Moreover, the inhomogeneity of MPTV alleviates the over-smoothing and ringing artifacts, and improves the robustness to errors in blur kernel. Extensive experiments on different tasks demonstrate the superiority of the proposed method over the current state-of-the-art.
Adaptive Importance Learning for Improving Lightweight Image Super-resolution Network
Jun 05, 2018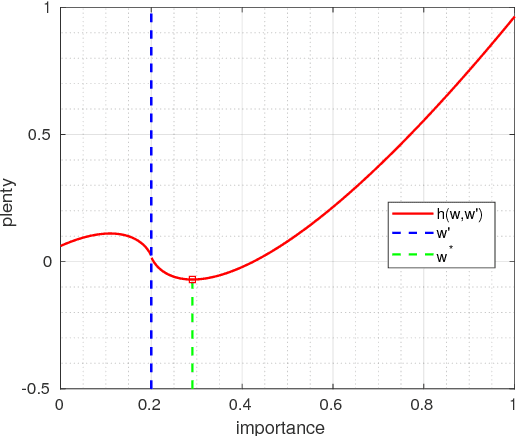
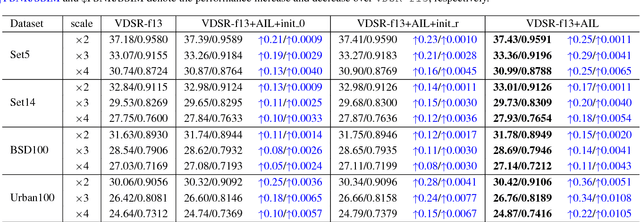
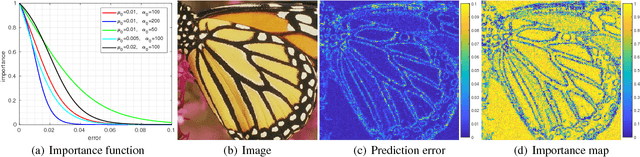
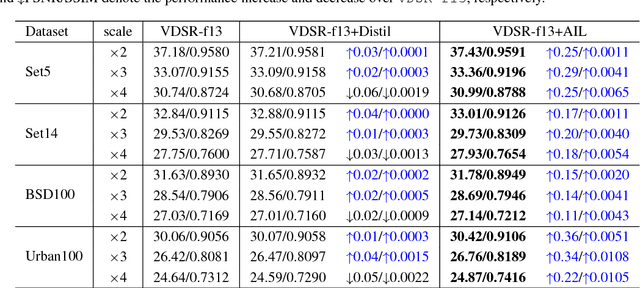
Deep neural networks have achieved remarkable success in single image super-resolution (SISR). The computing and memory requirements of these methods have hindered their application to broad classes of real devices with limited computing power, however. One approach to this problem has been lightweight network architectures that bal- ance the super-resolution performance and the computation burden. In this study, we revisit this problem from an orthog- onal view, and propose a novel learning strategy to maxi- mize the pixel-wise fitting capacity of a given lightweight network architecture. Considering that the initial capacity of the lightweight network is very limited, we present an adaptive importance learning scheme for SISR that trains the network with an easy-to-complex paradigm by dynam- ically updating the importance of image pixels on the basis of the training loss. Specifically, we formulate the network training and the importance learning into a joint optimization problem. With a carefully designed importance penalty function, the importance of individual pixels can be gradu- ally increased through solving a convex optimization problem. The training process thus begins with pixels that are easy to reconstruct, and gradually proceeds to more complex pixels as fitting improves.
Learning an Optimizer for Image Deconvolution
Apr 10, 2018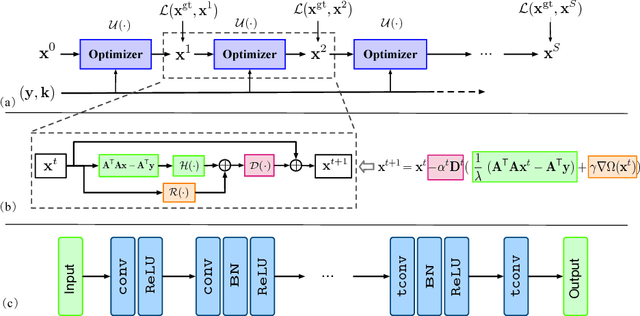
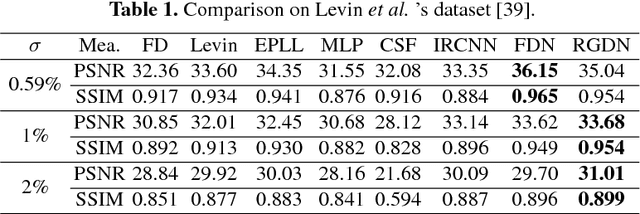

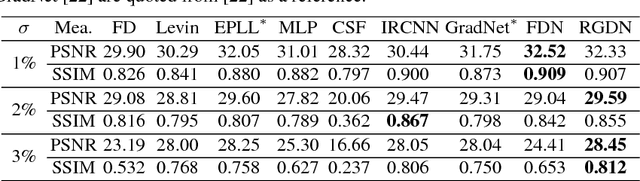
As an integral component of blind image deblurring, non-blind deconvolution removes image blur with a given blur kernel, which is essential but difficult due to the ill-posed nature of the inverse problem. The predominant approach is based on optimization subject to regularization functions that are either manually designed, or learned from examples. Existing learning based methods have shown superior restoration quality but are not practical enough due to their restricted model design. They solely focus on learning a prior and require to know the noise level for deconvolution. We address the gap between the optimization-based and learning-based approaches by learning an optimizer. We propose a Recurrent Gradient Descent Network (RGDN) by systematically incorporating deep neural networks into a fully parameterized gradient descent scheme. A parameter-free update unit is used to generate updates from the current estimates, based on a convolutional neural network. By training on diverse examples, the Recurrent Gradient Descent Network learns an implicit image prior and a universal update rule through recursive supervision. Extensive experiments on synthetic benchmarks and challenging real-world images demonstrate that the proposed method is effective and robust to produce favorable results as well as practical for real-world image deblurring applications.
Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments
Apr 05, 2018
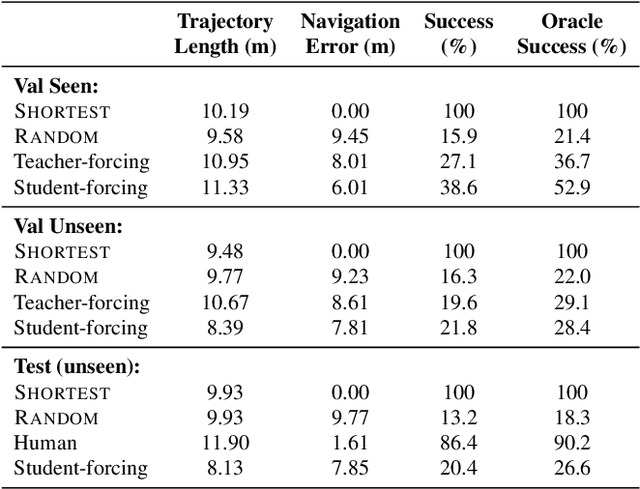
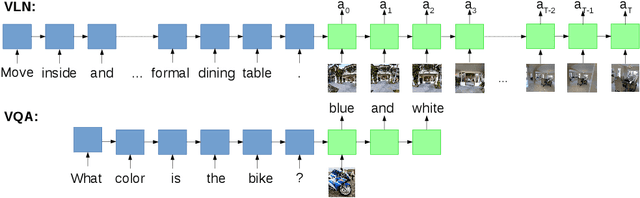

A robot that can carry out a natural-language instruction has been a dream since before the Jetsons cartoon series imagined a life of leisure mediated by a fleet of attentive robot helpers. It is a dream that remains stubbornly distant. However, recent advances in vision and language methods have made incredible progress in closely related areas. This is significant because a robot interpreting a natural-language navigation instruction on the basis of what it sees is carrying out a vision and language process that is similar to Visual Question Answering. Both tasks can be interpreted as visually grounded sequence-to-sequence translation problems, and many of the same methods are applicable. To enable and encourage the application of vision and language methods to the problem of interpreting visually-grounded navigation instructions, we present the Matterport3D Simulator -- a large-scale reinforcement learning environment based on real imagery. Using this simulator, which can in future support a range of embodied vision and language tasks, we provide the first benchmark dataset for visually-grounded natural language navigation in real buildings -- the Room-to-Room (R2R) dataset.
Visual Question Answering with Memory-Augmented Networks
Mar 25, 2018
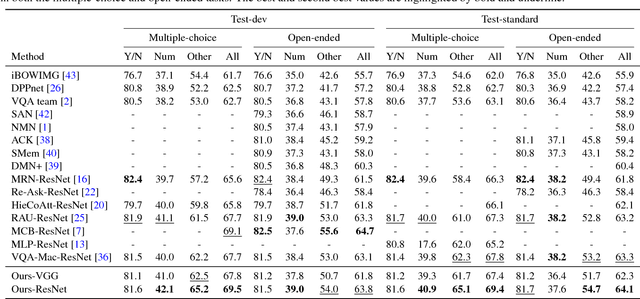
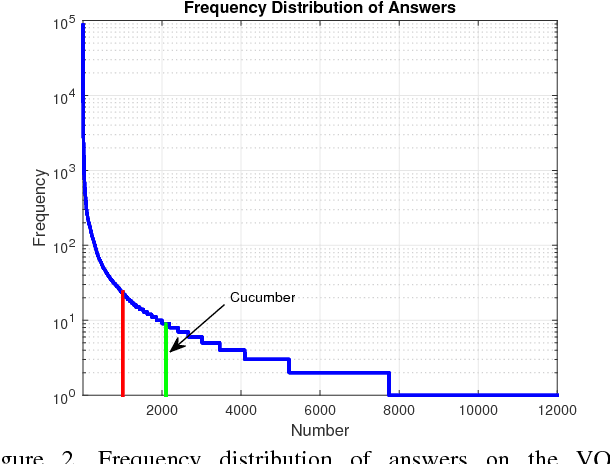
In this paper, we exploit a memory-augmented neural network to predict accurate answers to visual questions, even when those answers occur rarely in the training set. The memory network incorporates both internal and external memory blocks and selectively pays attention to each training exemplar. We show that memory-augmented neural networks are able to maintain a relatively long-term memory of scarce training exemplars, which is important for visual question answering due to the heavy-tailed distribution of answers in a general VQA setting. Experimental results on two large-scale benchmark datasets show the favorable performance of the proposed algorithm with a comparison to state of the art.
Real-time Semantic Image Segmentation via Spatial Sparsity
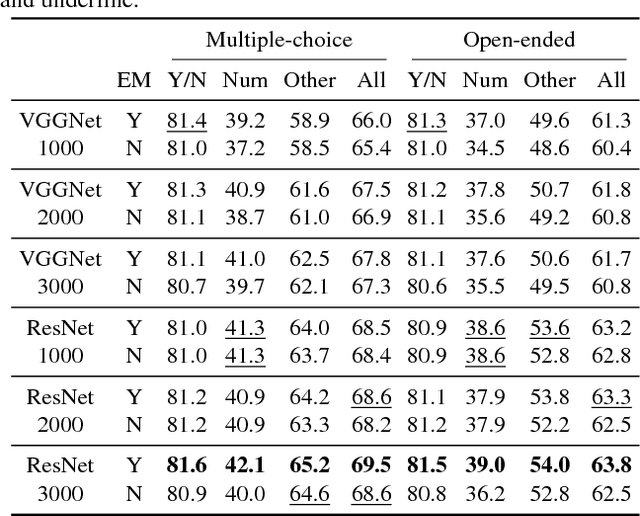
Dec 01, 2017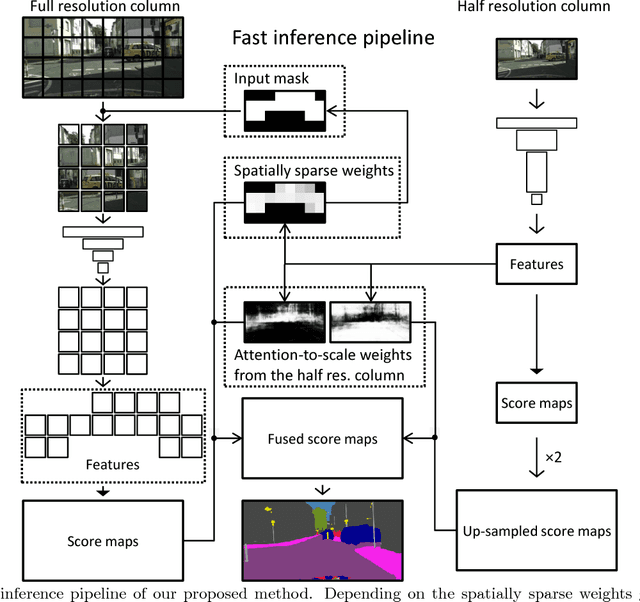

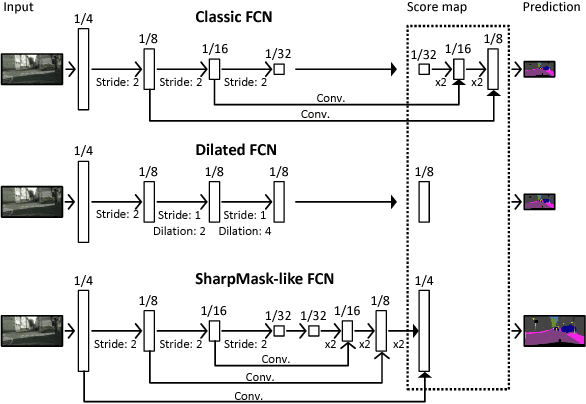
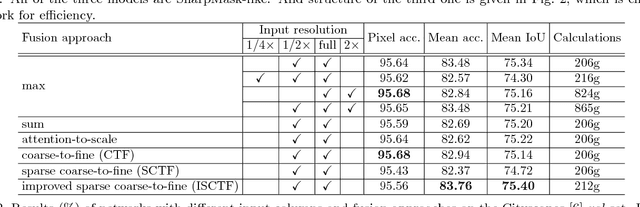
We propose an approach to semantic (image) segmentation that reduces the computational costs by a factor of 25 with limited impact on the quality of results. Semantic segmentation has a number of practical applications, and for most such applications the computational costs are critical. The method follows a typical two-column network structure, where one column accepts an input image, while the other accepts a half-resolution version of that image. By identifying specific regions in the full-resolution image that can be safely ignored, as well as carefully tailoring the network structure, we can process approximately 15 highresolution Cityscapes images (1024x2048) per second using a single GTX 980 video card, while achieving a mean intersection-over-union score of 72.9% on the Cityscapes test set.
Visual Question Answering as a Meta Learning Task
Nov 22, 2017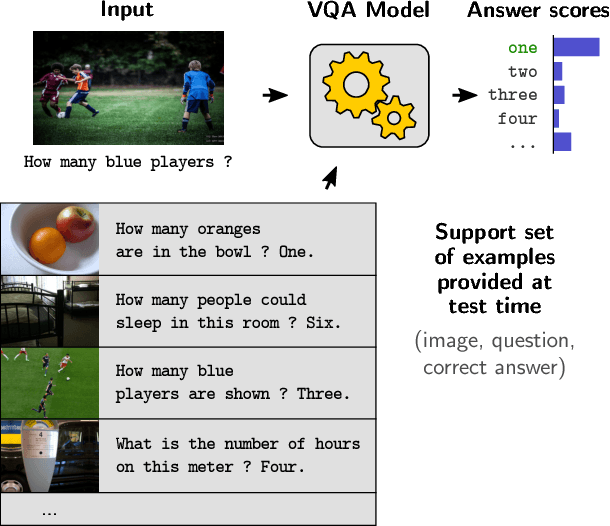
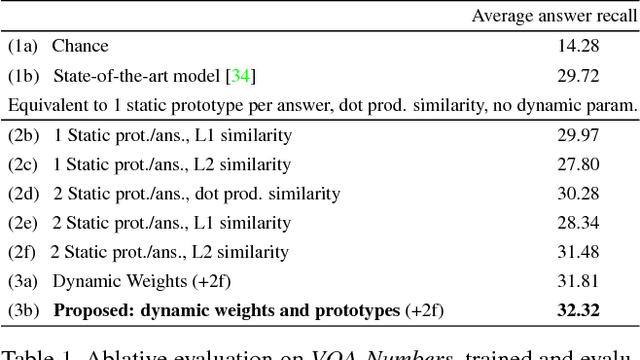
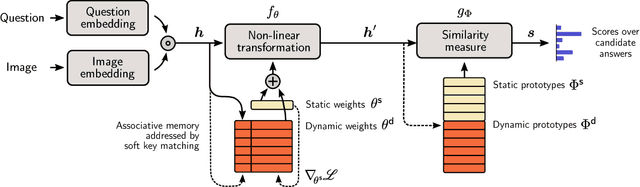
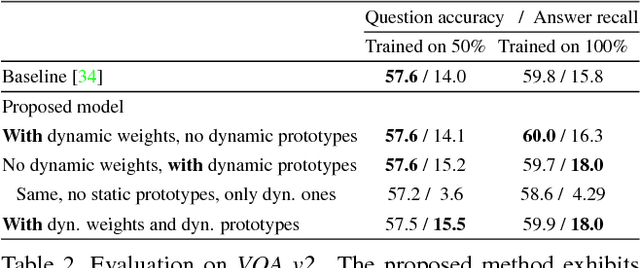
The predominant approach to Visual Question Answering (VQA) demands that the model represents within its weights all of the information required to answer any question about any image. Learning this information from any real training set seems unlikely, and representing it in a reasonable number of weights doubly so. We propose instead to approach VQA as a meta learning task, thus separating the question answering method from the information required. At test time, the method is provided with a support set of example questions/answers, over which it reasons to resolve the given question. The support set is not fixed and can be extended without retraining, thereby expanding the capabilities of the model. To exploit this dynamically provided information, we adapt a state-of-the-art VQA model with two techniques from the recent meta learning literature, namely prototypical networks and meta networks. Experiments demonstrate the capability of the system to learn to produce completely novel answers (i.e. never seen during training) from examples provided at test time. In comparison to the existing state of the art, the proposed method produces qualitatively distinct results with higher recall of rare answers, and a better sample efficiency that allows training with little initial data. More importantly, it represents an important step towards vision-and-language methods that can learn and reason on-the-fly.
Asking the Difficult Questions: Goal-Oriented Visual Question Generation via Intermediate Rewards
Nov 21, 2017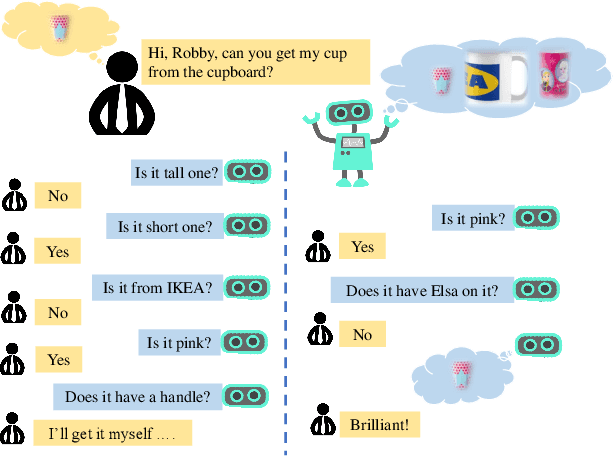
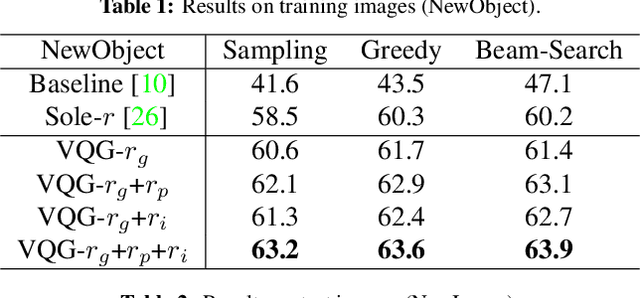
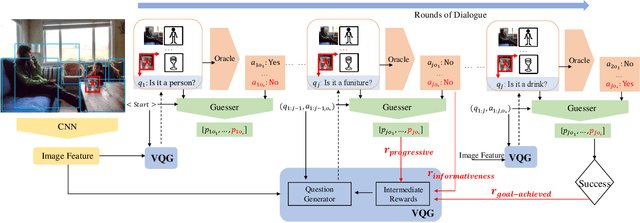
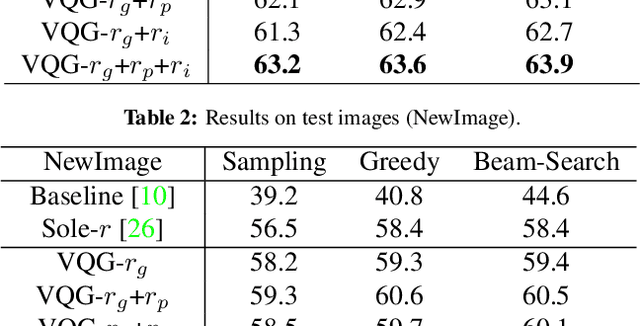
Despite significant progress in a variety of vision-and-language problems, developing a method capable of asking intelligent, goal-oriented questions about images is proven to be an inscrutable challenge. Towards this end, we propose a Deep Reinforcement Learning framework based on three new intermediate rewards, namely goal-achieved, progressive and informativeness that encourage the generation of succinct questions, which in turn uncover valuable information towards the overall goal. By directly optimizing for questions that work quickly towards fulfilling the overall goal, we avoid the tendency of existing methods to generate long series of insane queries that add little value. We evaluate our model on the GuessWhat?! dataset and show that the resulting questions can help a standard Guesser identify a specific object in an image at a much higher success rate.
Are You Talking to Me? Reasoned Visual Dialog Generation through Adversarial Learning
Nov 21, 2017
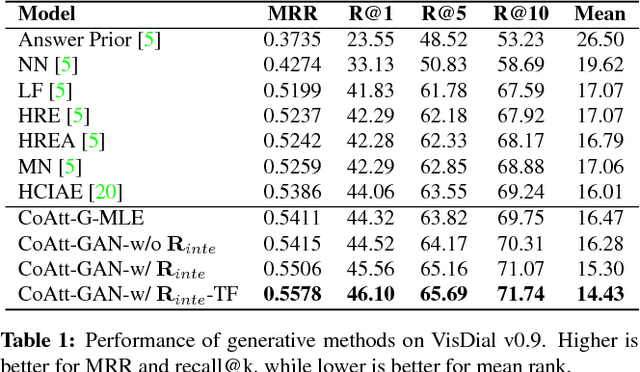
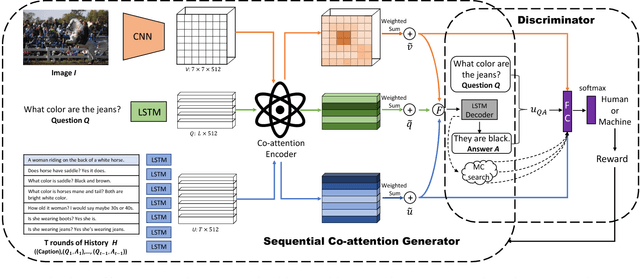
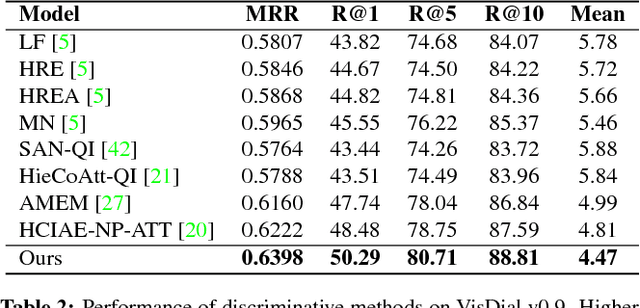
The Visual Dialogue task requires an agent to engage in a conversation about an image with a human. It represents an extension of the Visual Question Answering task in that the agent needs to answer a question about an image, but it needs to do so in light of the previous dialogue that has taken place. The key challenge in Visual Dialogue is thus maintaining a consistent, and natural dialogue while continuing to answer questions correctly. We present a novel approach that combines Reinforcement Learning and Generative Adversarial Networks (GANs) to generate more human-like responses to questions. The GAN helps overcome the relative paucity of training data, and the tendency of the typical MLE-based approach to generate overly terse answers. Critically, the GAN is tightly integrated into the attention mechanism that generates human-interpretable reasons for each answer. This means that the discriminative model of the GAN has the task of assessing whether a candidate answer is generated by a human or not, given the provided reason. This is significant because it drives the generative model to produce high quality answers that are well supported by the associated reasoning. The method also generates the state-of-the-art results on the primary benchmark.