 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the GLIDE model for Human Action-effect Prediction
Aug 01, 2022



We address the following action-effect prediction task. Given an image depicting an initial state of the world and an action expressed in text, predict an image depicting the state of the world following the action. The prediction should have the same scene context as the input image. We explore the use of the recently proposed GLIDE model for performing this task. GLIDE is a generative neural network that can synthesize (inpaint) masked areas of an image, conditioned on a short piece of text. Our idea is to mask-out a region of the input image where the effect of the action is expected to occur. GLIDE is then used to inpaint the masked region conditioned on the required action. In this way, the resulting image has the same background context as the input image, updated to show the effect of the action. We give qualitative results from experiments using the EPIC dataset of ego-centric videos labelled with actions.
Scribble-Supervised Semantic Segmentation by Uncertainty Reduction on Neural Representation and Self-Supervision on Neural Eigenspace
Feb 19, 2021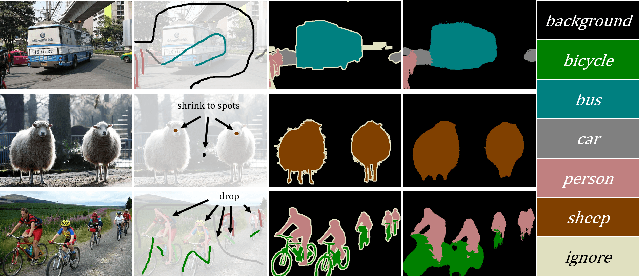
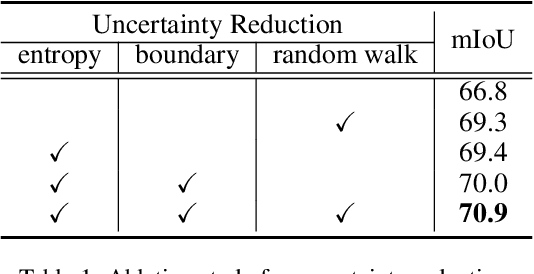
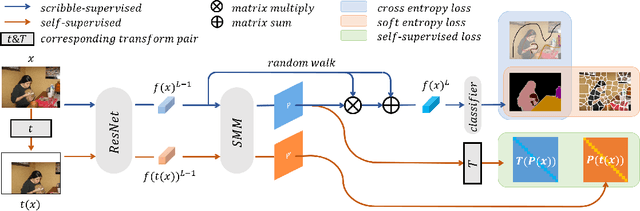
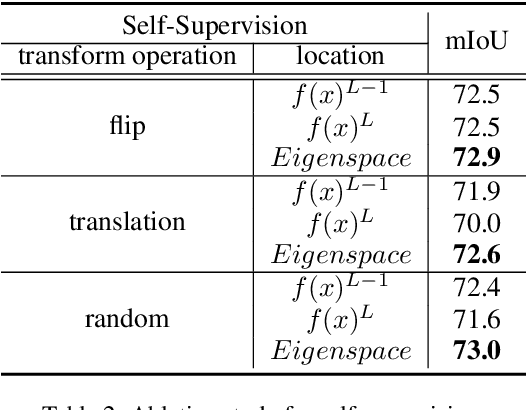
Scribble-supervised semantic segmentation has gained much attention recently for its promising performance without high-quality annotations. Due to the lack of supervision, confident and consistent predictions are usually hard to obtain. Typically, people handle these problems to either adopt an auxiliary task with the well-labeled dataset or incorporate the graphical model with additional requirements on scribble annotations. Instead, this work aims to achieve semantic segmentation by scribble annotations directly without extra information and other limitations. Specifically, we propose holistic operations, including minimizing entropy and a network embedded random walk on neural representation to reduce uncertainty. Given the probabilistic transition matrix of a random walk, we further train the network with self-supervision on its neural eigenspace to impose consistency on predictions between related images. Comprehensive experiments and ablation studies verify the proposed approach, which demonstrates superiority over others; it is even comparable to some full-label supervised ones and works well when scribbles are randomly shrunk or dropped.
Defect segmentation: Mapping tunnel lining internal defects with ground penetrating radar data using a convolutional neural network
Mar 29, 2020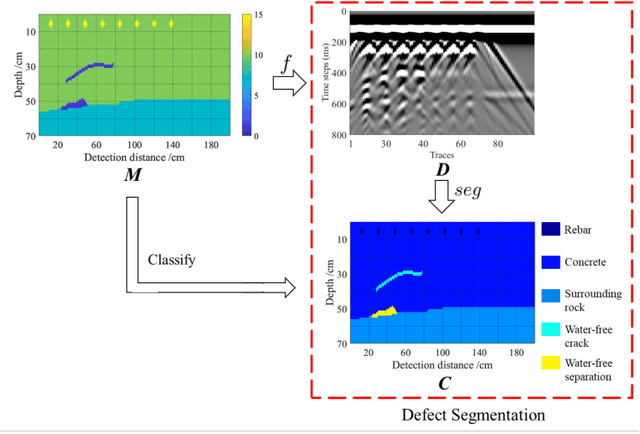

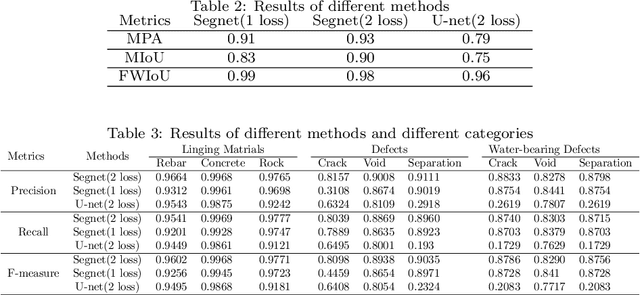
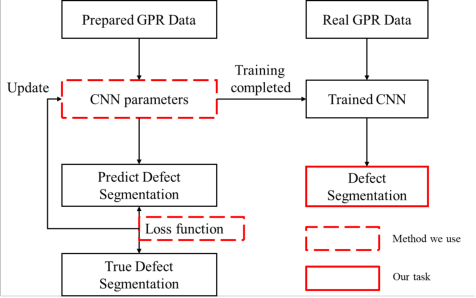
This research proposes a Ground Penetrating Radar (GPR) data processing method for non-destructive detection of tunnel lining internal defects, called defect segmentation. To perform this critical step of automatic tunnel lining detection, the method uses a CNN called Segnet combined with the Lov\'asz softmax loss function to map the internal defect structure with GPR synthetic data, which improves the accuracy, automation and efficiency of defects detection. The novel method we present overcomes several difficulties of traditional GPR data interpretation as demonstrated by an evaluation on both synthetic and real datas -- to verify the method on real data, a test model containing a known defect was designed and built and GPR data was obtained and analyzed.
Human-like Planning for Reaching in Cluttered Environments
Mar 03, 2020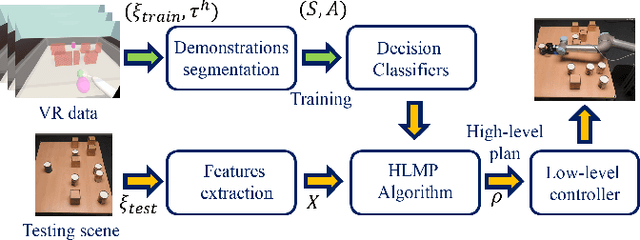
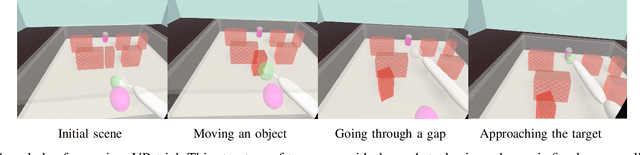
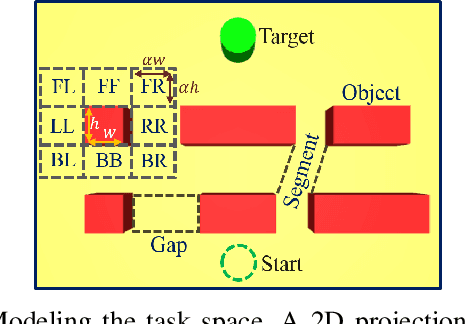
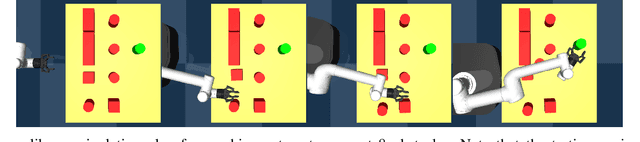
Humans, in comparison to robots, are remarkably adept at reaching for objects in cluttered environments. The best existing robot planners are based on random sampling of configuration space -- which becomes excessively high-dimensional with large number of objects. Consequently, most planners often fail to efficiently find object manipulation plans in such environments. We addressed this problem by identifying high-level manipulation plans in humans, and transferring these skills to robot planners. We used virtual reality to capture human participants reaching for a target object on a tabletop cluttered with obstacles. From this, we devised a qualitative representation of the task space to abstract the decision making, irrespective of the number of obstacles. Based on this representation, human demonstrations were segmented and used to train decision classifiers. Using these classifiers, our planner produced a list of waypoints in task space. These waypoints provided a high-level plan, which could be transferred to an arbitrary robot model and used to initialise a local trajectory optimiser. We evaluated this approach through testing on unseen human VR data, a physics-based robot simulation, and a real robot (dataset and code are publicly available). We found that the human-like planner outperformed a state-of-the-art standard trajectory optimisation algorithm, and was able to generate effective strategies for rapid planning -- irrespective of the number of obstacles in the environment.
GPRInvNet: Deep Learning-Based Ground Penetrating Radar Data Inversion for Tunnel Lining
Dec 13, 2019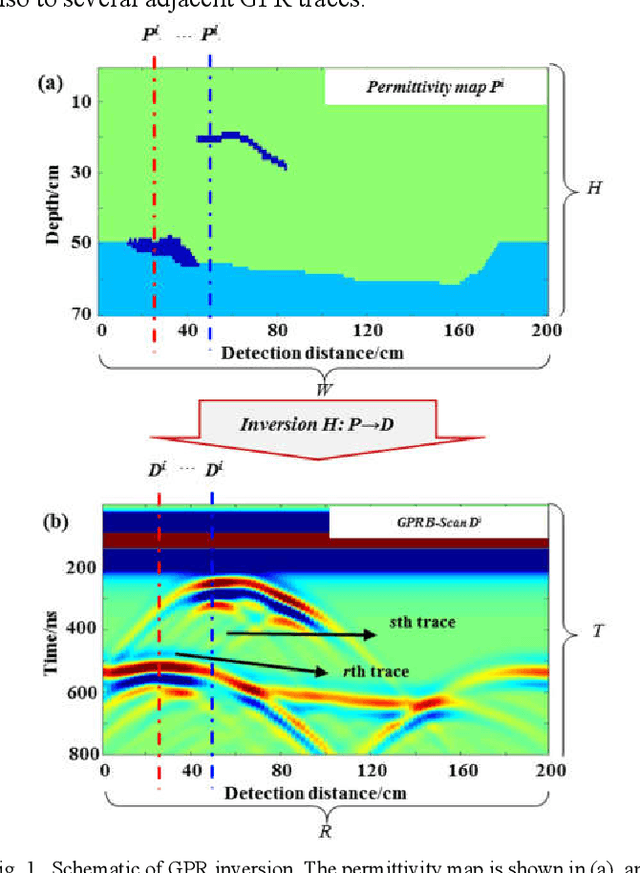
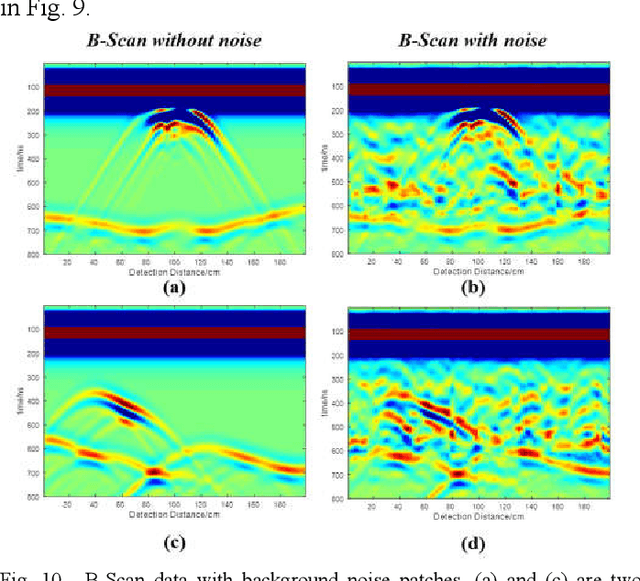
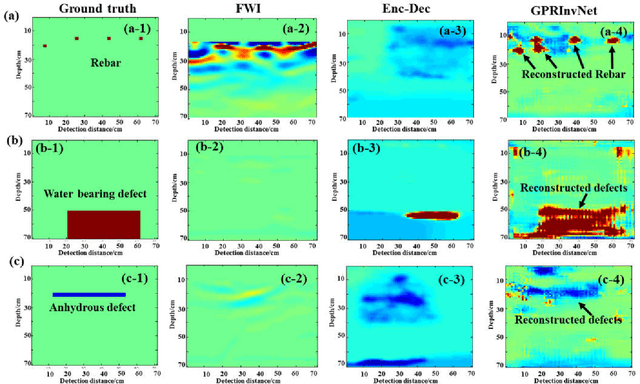
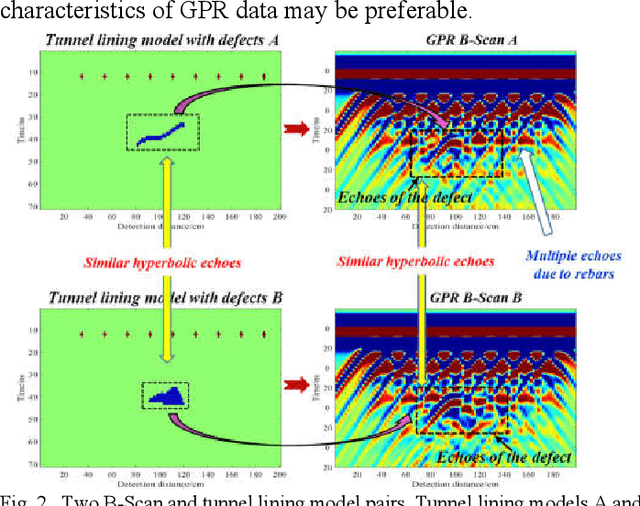
A DNN architecture called GPRInvNet is proposed to tackle the challenge of mapping Ground Penetrating Radar (GPR) B-Scan data to complex permittivity maps of subsurface structure. GPRInvNet consists of a trace-to-trace encoder and a decoder. It is specially designed to take account of the characteristics of GPR inversion when faced with complex GPR B-Scan data as well as addressing the spatial alignment issue between time-series B-Scan data and spatial permittivity maps. It fuses features from several adjacent traces on the B-Scan data to enhance each trace, and then further condense the features of each trace separately. The sensitive zone on the permittivity map spatially aligned to the enhanced trace is reconstructed accurately. GPRInvNet has been utilized to reconstruct the permittivity map of tunnel linings. A diverse range of dielectric models of tunnel lining containing complex defects has been reconstructed using GPRInvNet, and results demonstrate that GPRInvNet is capable of effectively reconstructing complex tunnel lining defects with clear boundaries. Comparative results with existing baseline methods also demonstrate the superiority of the GPRInvNet. To generalize GPRInvNet to real GPR data, we integrated background noise patches recorded form a practical model testing into synthetic GPR data to train GPRInvNet. The model testing has been conducted for validation, and experimental results show that GPRInvNet achieves satisfactory results on real data.
ViTac: Feature Sharing between Vision and Tactile Sensing for Cloth Texture Recognition
Mar 13, 2018


Vision and touch are two of the important sensing modalities for humans and they offer complementary information for sensing the environment. Robots could also benefit from such multi-modal sensing ability. In this paper, addressing for the first time (to the best of our knowledge) texture recognition from tactile images and vision, we propose a new fusion method named Deep Maximum Covariance Analysis (DMCA) to learn a joint latent space for sharing features through vision and tactile sensing. The features of camera images and tactile data acquired from a GelSight sensor are learned by deep neural networks. But the learned features are of a high dimensionality and are redundant due to the differences between the two sensing modalities, which deteriorates the perception performance. To address this, the learned features are paired using maximum covariance analysis. Results of the algorithm on a newly collected dataset of paired visual and tactile data relating to cloth textures show that a good recognition performance of greater than 90\% can be achieved by using the proposed DMCA framework. In addition, we find that the perception performance of either vision or tactile sensing can be improved by employing the shared representation space, compared to learning from unimodal data.
CLAD: A Complex and Long Activities Dataset with Rich Crowdsourced Annotations
Sep 21, 2017
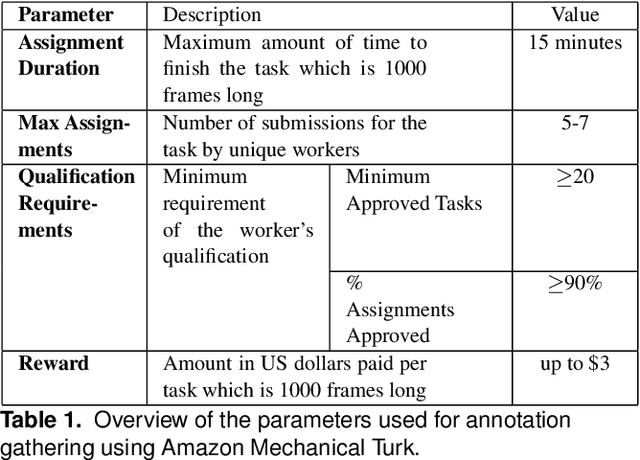
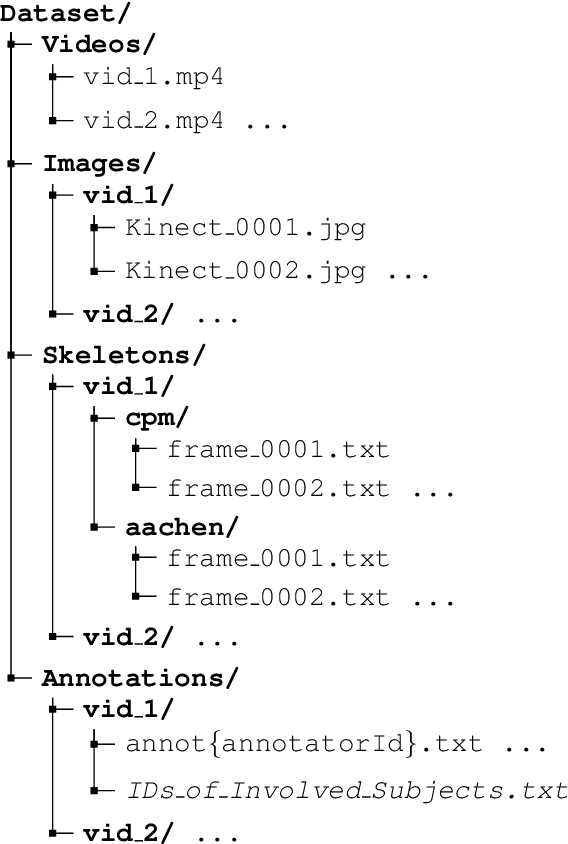
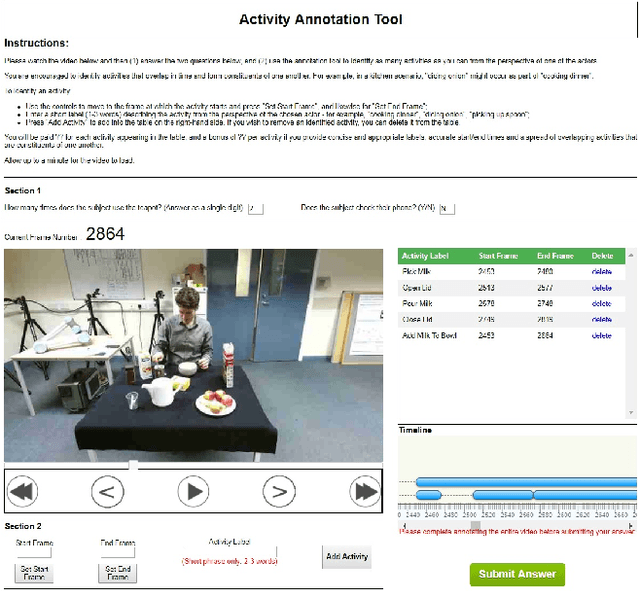
This paper introduces a novel activity dataset which exhibits real-life and diverse scenarios of complex, temporally-extended human activities and actions. The dataset presents a set of videos of actors performing everyday activities in a natural and unscripted manner. The dataset was recorded using a static Kinect 2 sensor which is commonly used on many robotic platforms. The dataset comprises of RGB-D images, point cloud data, automatically generated skeleton tracks in addition to crowdsourced annotations. Furthermore, we also describe the methodology used to acquire annotations through crowdsourcing. Finally some activity recognition benchmarks are presented using current state-of-the-art techniques. We believe that this dataset is particularly suitable as a testbed for activity recognition research but it can also be applicable for other common tasks in robotics/computer vision research such as object detection and human skeleton tracking.
The STRANDS Project: Long-Term Autonomy in Everyday Environments
Oct 14, 2016
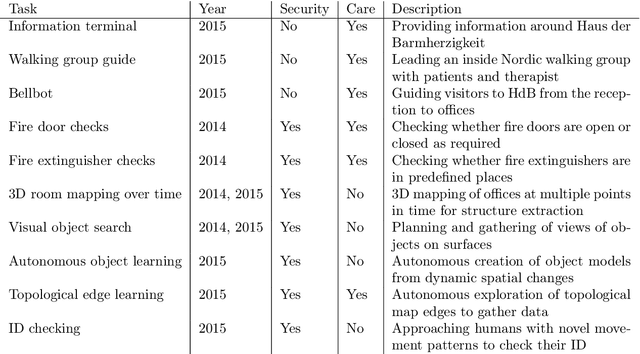
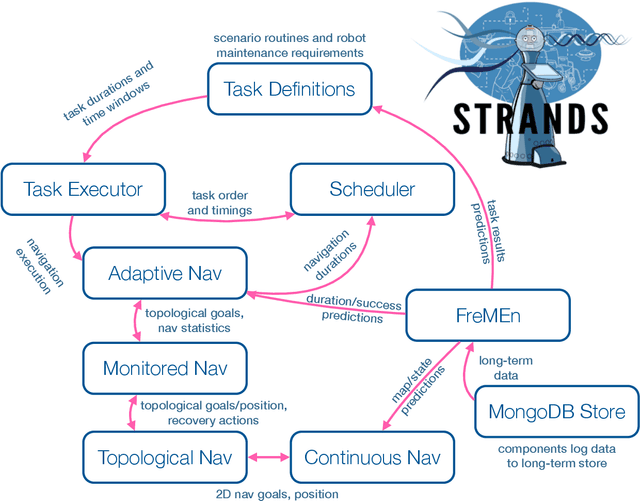
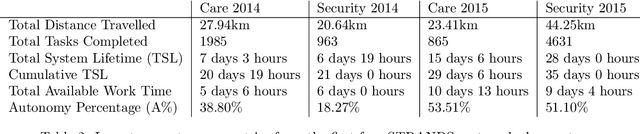
Thanks to the efforts of the robotics and autonomous systems community, robots are becoming ever more capable. There is also an increasing demand from end-users for autonomous service robots that can operate in real environments for extended periods. In the STRANDS project we are tackling this demand head-on by integrating state-of-the-art artificial intelligence and robotics research into mobile service robots, and deploying these systems for long-term installations in security and care environments. Over four deployments, our robots have been operational for a combined duration of 104 days autonomously performing end-user defined tasks, covering 116km in the process. In this article we describe the approach we have used to enable long-term autonomous operation in everyday environments, and how our robots are able to use their long run times to improve their own performance.
Reasoning with Topological and Directional Spatial Information
Sep 01, 2009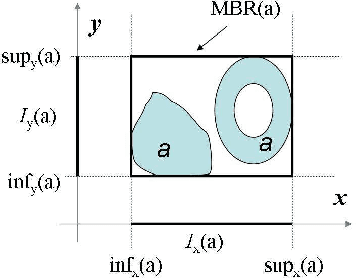

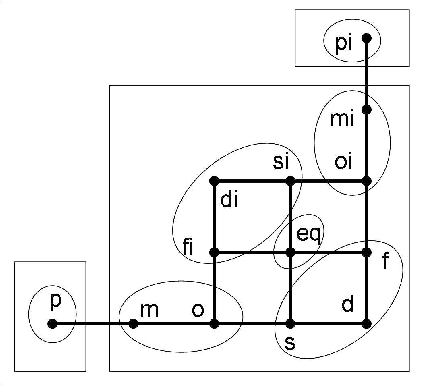
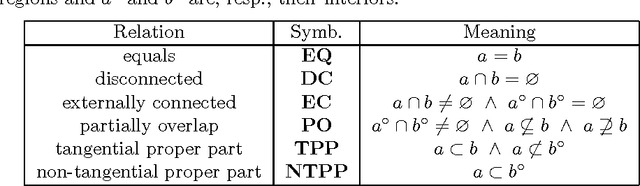
Current research on qualitative spatial representation and reasoning mainly focuses on one single aspect of space. In real world applications, however, multiple spatial aspects are often involved simultaneously. This paper investigates problems arising in reasoning with combined topological and directional information. We use the RCC8 algebra and the Rectangle Algebra (RA) for expressing topological and directional information respectively. We give examples to show that the bipath-consistency algorithm BIPATH is incomplete for solving even basic RCC8 and RA constraints. If topological constraints are taken from some maximal tractable subclasses of RCC8, and directional constraints are taken from a subalgebra, termed DIR49, of RA, then we show that BIPATH is able to separate topological constraints from directional ones. This means, given a set of hybrid topological and directional constraints from the above subclasses of RCC8 and RA, we can transfer the joint satisfaction problem in polynomial time to two independent satisfaction problems in RCC8 and RA. For general RA constraints, we give a method to compute solutions that satisfy all topological constraints and approximately satisfy each RA constraint to any prescribed precision.