 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Navigation Planning for Long-term Autonomous Operation of Underwater Gliders
Feb 22, 2026Underwater glider robots have become an indispensable tool for ocean sampling. Although stakeholders are calling for tools to manage increasingly large fleets of gliders, successful autonomous long-term deployments have thus far been scarce, which hints at a lack of suitable methodologies and systems. In this work, we formulate glider navigation planning as a stochastic shortest-path Markov Decision Process and propose a sample-based online planner based on Monte Carlo Tree Search. Samples are generated by a physics-informed simulator that captures uncertain execution of controls and ocean current forecasts while remaining computationally tractable. The simulator parameters are fitted using historical glider data. We integrate these methods into an autonomous command-and-control system for Slocum gliders that enables closed-loop replanning at each surfacing. The resulting system was validated in two field deployments in the North Sea totalling approximately 3 months and 1000 km of autonomous operation. Results demonstrate improved efficiency compared to straight-to-goal navigation and show the practicality of sample-based planning for long-term marine autonomy.
Improving Regret Approximation for Unsupervised Dynamic Environment Generation
Jan 21, 2026Unsupervised Environment Design (UED) seeks to automatically generate training curricula for reinforcement learning (RL) agents, with the goal of improving generalisation and zero-shot performance. However, designing effective curricula remains a difficult problem, particularly in settings where small subsets of environment parameterisations result in significant increases in the complexity of the required policy. Current methods struggle with a difficult credit assignment problem and rely on regret approximations that fail to identify challenging levels, both of which are compounded as the size of the environment grows. We propose Dynamic Environment Generation for UED (DEGen) to enable a denser level generator reward signal, reducing the difficulty of credit assignment and allowing for UED to scale to larger environment sizes. We also introduce a new regret approximation, Maximised Negative Advantage (MNA), as a significantly improved metric to optimise for, that better identifies more challenging levels. We show empirically that MNA outperforms current regret approximations and when combined with DEGen, consistently outperforms existing methods, especially as the size of the environment grows. We have made all our code available here: https://github.com/HarryMJMead/Dynamic-Environment-Generation-for-UED.
Gaussian Process Aggregation for Root-Parallel Monte Carlo Tree Search with Continuous Actions
Dec 10, 2025Monte Carlo Tree Search is a cornerstone algorithm for online planning, and its root-parallel variant is widely used when wall clock time is limited but best performance is desired. In environments with continuous action spaces, how to best aggregate statistics from different threads is an important yet underexplored question. In this work, we introduce a method that uses Gaussian Process Regression to obtain value estimates for promising actions that were not trialed in the environment. We perform a systematic evaluation across 6 different domains, demonstrating that our approach outperforms existing aggregation strategies while requiring a modest increase in inference time.
Scalable Solution Methods for Dec-POMDPs with Deterministic Dynamics
Aug 29, 2025



Many high-level multi-agent planning problems, including multi-robot navigation and path planning, can be effectively modeled using deterministic actions and observations. In this work, we focus on such domains and introduce the class of Deterministic Decentralized POMDPs (Det-Dec-POMDPs). This is a subclass of Dec-POMDPs characterized by deterministic transitions and observations conditioned on the state and joint actions. We then propose a practical solver called Iterative Deterministic POMDP Planning (IDPP). This method builds on the classic Joint Equilibrium Search for Policies framework and is specifically optimized to handle large-scale Det-Dec-POMDPs that current Dec-POMDP solvers are unable to address efficiently.
A Finite-State Controller Based Offline Solver for Deterministic POMDPs
May 01, 2025



Deterministic partially observable Markov decision processes (DetPOMDPs) often arise in planning problems where the agent is uncertain about its environmental state but can act and observe deterministically. In this paper, we propose DetMCVI, an adaptation of the Monte Carlo Value Iteration (MCVI) algorithm for DetPOMDPs, which builds policies in the form of finite-state controllers (FSCs). DetMCVI solves large problems with a high success rate, outperforming existing baselines for DetPOMDPs. We also verify the performance of the algorithm in a real-world mobile robot forest mapping scenario.
Return Capping: Sample-Efficient CVaR Policy Gradient Optimisation
Apr 29, 2025



When optimising for conditional value at risk (CVaR) using policy gradients (PG), current methods rely on discarding a large proportion of trajectories, resulting in poor sample efficiency. We propose a reformulation of the CVaR optimisation problem by capping the total return of trajectories used in training, rather than simply discarding them, and show that this is equivalent to the original problem if the cap is set appropriately. We show, with empirical results in an number of environments, that this reformulation of the problem results in consistently improved performance compared to baselines.
No Regrets: Investigating and Improving Regret Approximations for Curriculum Discovery
Aug 27, 2024



What data or environments to use for training to improve downstream performance is a longstanding and very topical question in reinforcement learning. In particular, Unsupervised Environment Design (UED) methods have gained recent attention as their adaptive curricula enable agents to be robust to in- and out-of-distribution tasks. We ask to what extent these methods are themselves robust when applied to a novel setting, closely inspired by a real-world robotics problem. Surprisingly, we find that the state-of-the-art UED methods either do not improve upon the na\"{i}ve baseline of Domain Randomisation (DR), or require substantial hyperparameter tuning to do so. Our analysis shows that this is due to their underlying scoring functions failing to predict intuitive measures of ``learnability'', i.e., in finding the settings that the agent sometimes solves, but not always. Based on this, we instead directly train on levels with high learnability and find that this simple and intuitive approach outperforms UED methods and DR in several binary-outcome environments, including on our domain and the standard UED domain of Minigrid. We further introduce a new adversarial evaluation procedure for directly measuring robustness, closely mirroring the conditional value at risk (CVaR). We open-source all our code and present visualisations of final policies here: https://github.com/amacrutherford/sampling-for-learnability.
Monte Carlo Tree Search with Boltzmann Exploration
Apr 11, 2024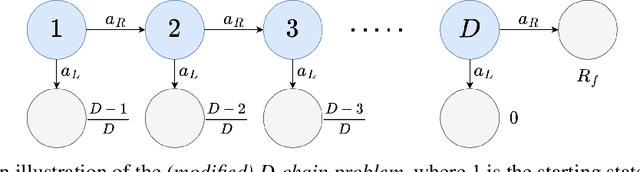



Monte-Carlo Tree Search (MCTS) methods, such as Upper Confidence Bound applied to Trees (UCT), are instrumental to automated planning techniques. However, UCT can be slow to explore an optimal action when it initially appears inferior to other actions. Maximum ENtropy Tree-Search (MENTS) incorporates the maximum entropy principle into an MCTS approach, utilising Boltzmann policies to sample actions, naturally encouraging more exploration. In this paper, we highlight a major limitation of MENTS: optimal actions for the maximum entropy objective do not necessarily correspond to optimal actions for the original objective. We introduce two algorithms, Boltzmann Tree Search (BTS) and Decaying ENtropy Tree-Search (DENTS), that address these limitations and preserve the benefits of Boltzmann policies, such as allowing actions to be sampled faster by using the Alias method. Our empirical analysis shows that our algorithms show consistent high performance across several benchmark domains, including the game of Go.
* Camera ready version of NeurIPS2023 paper
JaxMARL: Multi-Agent RL Environments in JAX
Nov 20, 2023



Benchmarks play an important role in the development of machine learning algorithms. For example, research in reinforcement learning (RL) has been heavily influenced by available environments and benchmarks. However, RL environments are traditionally run on the CPU, limiting their scalability with typical academic compute. Recent advancements in JAX have enabled the wider use of hardware acceleration to overcome these computational hurdles, enabling massively parallel RL training pipelines and environments. This is particularly useful for multi-agent reinforcement learning (MARL) research. First of all, multiple agents must be considered at each environment step, adding computational burden, and secondly, the sample complexity is increased due to non-stationarity, decentralised partial observability, or other MARL challenges. In this paper, we present JaxMARL, the first open-source code base that combines ease-of-use with GPU enabled efficiency, and supports a large number of commonly used MARL environments as well as popular baseline algorithms. When considering wall clock time, our experiments show that per-run our JAX-based training pipeline is up to 12500x faster than existing approaches. This enables efficient and thorough evaluations, with the potential to alleviate the evaluation crisis of the field. We also introduce and benchmark SMAX, a vectorised, simplified version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine. This not only enables GPU acceleration, but also provides a more flexible MARL environment, unlocking the potential for self-play, meta-learning, and other future applications in MARL. We provide code at https://github.com/flairox/jaxmarl.
A Framework for Learning from Demonstration with Minimal Human Effort
Jun 15, 2023



We consider robot learning in the context of shared autonomy, where control of the system can switch between a human teleoperator and autonomous control. In this setting we address reinforcement learning, and learning from demonstration, where there is a cost associated with human time. This cost represents the human time required to teleoperate the robot, or recover the robot from failures. For each episode, the agent must choose between requesting human teleoperation, or using one of its autonomous controllers. In our approach, we learn to predict the success probability for each controller, given the initial state of an episode. This is used in a contextual multi-armed bandit algorithm to choose the controller for the episode. A controller is learnt online from demonstrations and reinforcement learning so that autonomous performance improves, and the system becomes less reliant on the teleoperator with more experience. We show that our approach to controller selection reduces the human cost to perform two simulated tasks and a single real-world task.