 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermutation Equivariant Neural Functionals
Feb 27, 2023



This work studies the design of neural networks that can process the weights or gradients of other neural networks, which we refer to as neural functional networks (NFNs). Despite a wide range of potential applications, including learned optimization, processing implicit neural representations, network editing, and policy evaluation, there are few unifying principles for designing effective architectures that process the weights of other networks. We approach the design of neural functionals through the lens of symmetry, in particular by focusing on the permutation symmetries that arise in the weights of deep feedforward networks because hidden layer neurons have no inherent order. We introduce a framework for building permutation equivariant neural functionals, whose architectures encode these symmetries as an inductive bias. The key building blocks of this framework are NF-Layers (neural functional layers) that we constrain to be permutation equivariant through an appropriate parameter sharing scheme. In our experiments, we find that permutation equivariant neural functionals are effective on a diverse set of tasks that require processing the weights of MLPs and CNNs, such as predicting classifier generalization, producing "winning ticket" sparsity masks for initializations, and editing the weights of implicit neural representations (INRs). In addition, we provide code for our models and experiments at https://github.com/AllanYangZhou/nfn.
NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics via Novel-View Synthesis
Jan 18, 2023Expert demonstrations are a rich source of supervision for training visual robotic manipulation policies, but imitation learning methods often require either a large number of demonstrations or expensive online expert supervision to learn reactive closed-loop behaviors. In this work, we introduce SPARTN (Synthetic Perturbations for Augmenting Robot Trajectories via NeRF): a fully-offline data augmentation scheme for improving robot policies that use eye-in-hand cameras. Our approach leverages neural radiance fields (NeRFs) to synthetically inject corrective noise into visual demonstrations, using NeRFs to generate perturbed viewpoints while simultaneously calculating the corrective actions. This requires no additional expert supervision or environment interaction, and distills the geometric information in NeRFs into a real-time reactive RGB-only policy. In a simulated 6-DoF visual grasping benchmark, SPARTN improves success rates by 2.8$\times$ over imitation learning without the corrective augmentations and even outperforms some methods that use online supervision. It additionally closes the gap between RGB-only and RGB-D success rates, eliminating the previous need for depth sensors. In real-world 6-DoF robotic grasping experiments from limited human demonstrations, our method improves absolute success rates by $22.5\%$ on average, including objects that are traditionally challenging for depth-based methods. See video results at \url{https://bland.website/spartn}.
Unsupervised language models for disease variant prediction
Dec 07, 2022There is considerable interest in predicting the pathogenicity of protein variants in human genes. Due to the sparsity of high quality labels, recent approaches turn to \textit{unsupervised} learning, using Multiple Sequence Alignments (MSAs) to train generative models of natural sequence variation within each gene. These generative models then predict variant likelihood as a proxy to evolutionary fitness. In this work we instead combine this evolutionary principle with pretrained protein language models (LMs), which have already shown promising results in predicting protein structure and function. Instead of training separate models per-gene, we find that a single protein LM trained on broad sequence datasets can score pathogenicity for any gene variant zero-shot, without MSAs or finetuning. We call this unsupervised approach \textbf{VELM} (Variant Effect via Language Models), and show that it achieves scoring performance comparable to the state of the art when evaluated on clinically labeled variants of disease-related genes.
Multi-Domain Long-Tailed Learning by Augmenting Disentangled Representations
Oct 25, 2022



There is an inescapable long-tailed class-imbalance issue in many real-world classification problems. Existing long-tailed classification methods focus on the single-domain setting, where all examples are drawn from the same distribution. However, real-world scenarios often involve multiple domains with distinct imbalanced class distributions. We study this multi-domain long-tailed learning problem and aim to produce a model that generalizes well across all classes and domains. Towards that goal, we introduce TALLY, which produces invariant predictors by balanced augmenting hidden representations over domains and classes. Built upon a proposed selective balanced sampling strategy, TALLY achieves this by mixing the semantic representation of one example with the domain-associated nuisances of another, producing a new representation for use as data augmentation. To improve the disentanglement of semantic representations, TALLY further utilizes a domain-invariant class prototype that averages out domain-specific effects. We evaluate TALLY on four long-tailed variants of classical domain generalization benchmarks and two real-world imbalanced multi-domain datasets. The results indicate that TALLY consistently outperforms other state-of-the-art methods in both subpopulation shift and domain shift.
Do Deep Networks Transfer Invariances Across Classes?
Mar 18, 2022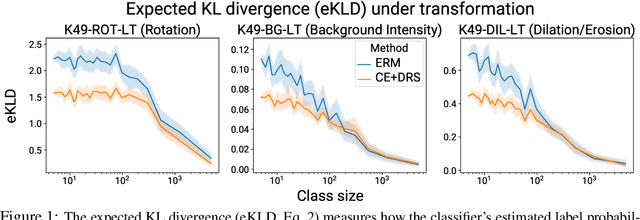
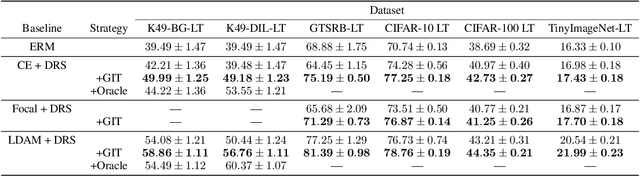
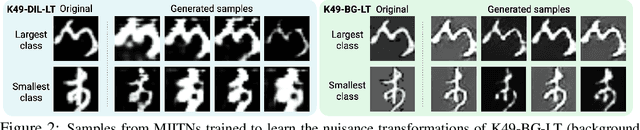
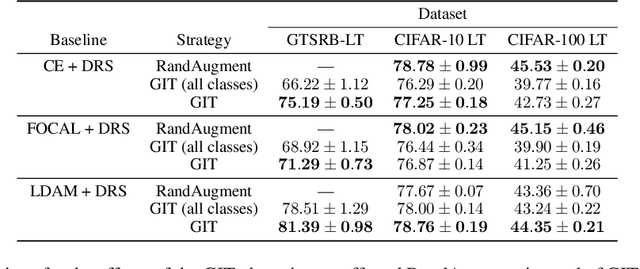
To generalize well, classifiers must learn to be invariant to nuisance transformations that do not alter an input's class. Many problems have "class-agnostic" nuisance transformations that apply similarly to all classes, such as lighting and background changes for image classification. Neural networks can learn these invariances given sufficient data, but many real-world datasets are heavily class imbalanced and contain only a few examples for most of the classes. We therefore pose the question: how well do neural networks transfer class-agnostic invariances learned from the large classes to the small ones? Through careful experimentation, we observe that invariance to class-agnostic transformations is still heavily dependent on class size, with the networks being much less invariant on smaller classes. This result holds even when using data balancing techniques, and suggests poor invariance transfer across classes. Our results provide one explanation for why classifiers generalize poorly on unbalanced and long-tailed distributions. Based on this analysis, we show how a generative approach for learning the nuisance transformations can help transfer invariances across classes and improve performance on a set of imbalanced image classification benchmarks. Source code for our experiments is available at https://github.com/AllanYangZhou/generative-invariance-transfer.
Policy Architectures for Compositional Generalization in Control
Mar 10, 2022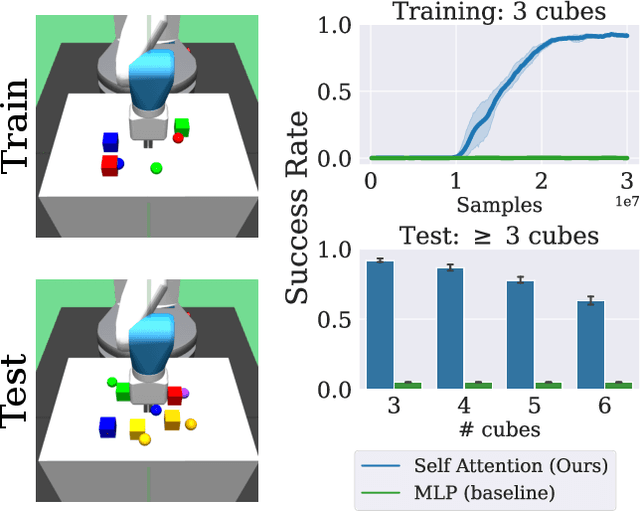
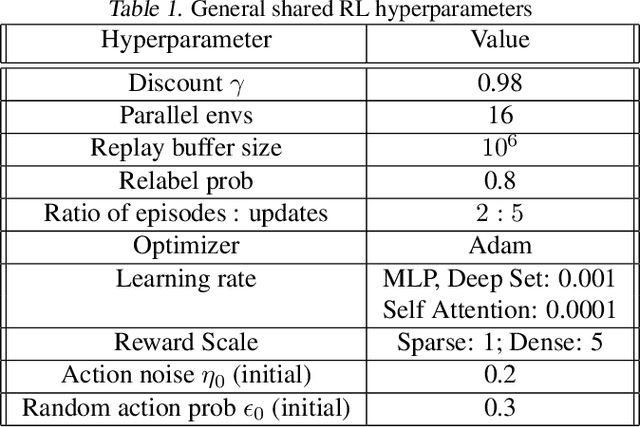
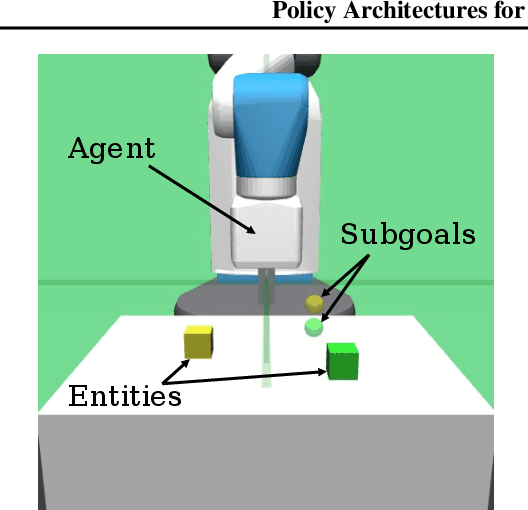
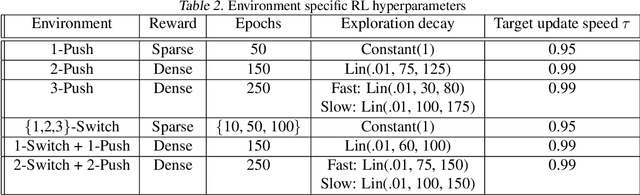
Many tasks in control, robotics, and planning can be specified using desired goal configurations for various entities in the environment. Learning goal-conditioned policies is a natural paradigm to solve such tasks. However, current approaches struggle to learn and generalize as task complexity increases, such as variations in number of environment entities or compositions of goals. In this work, we introduce a framework for modeling entity-based compositional structure in tasks, and create suitable policy designs that can leverage this structure. Our policies, which utilize architectures like Deep Sets and Self Attention, are flexible and can be trained end-to-end without requiring any action primitives. When trained using standard reinforcement and imitation learning methods on a suite of simulated robot manipulation tasks, we find that these architectures achieve significantly higher success rates with less data. We also find these architectures enable broader and compositional generalization, producing policies that extrapolate to different numbers of entities than seen in training, and stitch together (i.e. compose) learned skills in novel ways. Videos of the results can be found at https://sites.google.com/view/comp-gen-rl.
Noether Networks: Meta-Learning Useful Conserved Quantities
Dec 06, 2021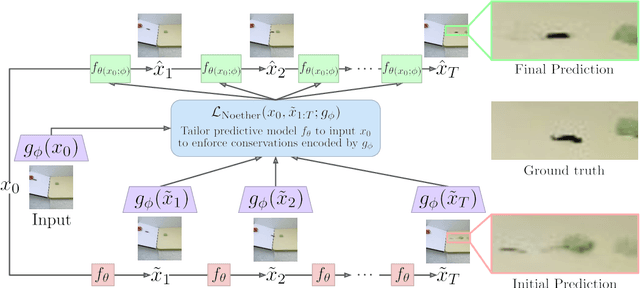
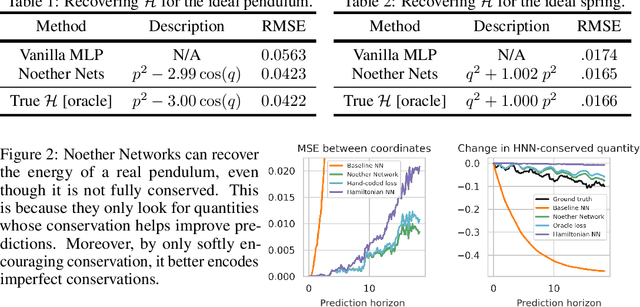
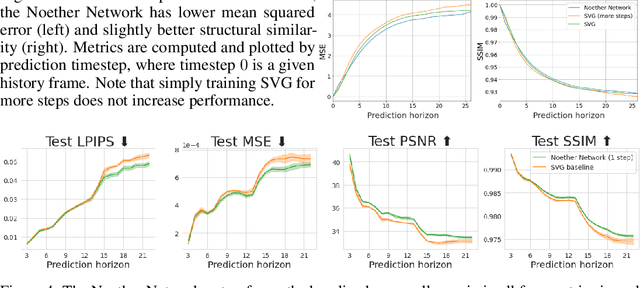

Progress in machine learning (ML) stems from a combination of data availability, computational resources, and an appropriate encoding of inductive biases. Useful biases often exploit symmetries in the prediction problem, such as convolutional networks relying on translation equivariance. Automatically discovering these useful symmetries holds the potential to greatly improve the performance of ML systems, but still remains a challenge. In this work, we focus on sequential prediction problems and take inspiration from Noether's theorem to reduce the problem of finding inductive biases to meta-learning useful conserved quantities. We propose Noether Networks: a new type of architecture where a meta-learned conservation loss is optimized inside the prediction function. We show, theoretically and experimentally, that Noether Networks improve prediction quality, providing a general framework for discovering inductive biases in sequential problems.
Discriminator Augmented Model-Based Reinforcement Learning
Mar 30, 2021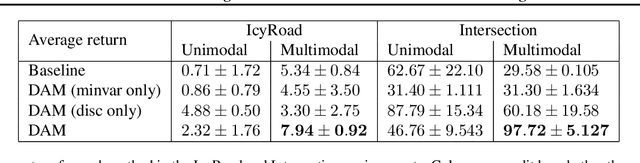
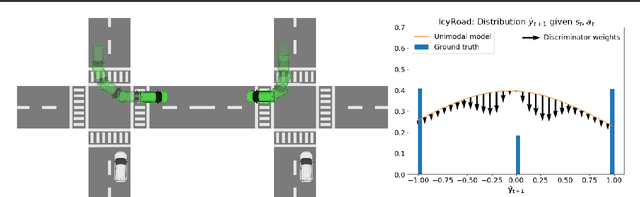
By planning through a learned dynamics model, model-based reinforcement learning (MBRL) offers the prospect of good performance with little environment interaction. However, it is common in practice for the learned model to be inaccurate, impairing planning and leading to poor performance. This paper aims to improve planning with an importance sampling framework that accounts and corrects for discrepancy between the true and learned dynamics. This framework also motivates an alternative objective for fitting the dynamics model: to minimize the variance of value estimation during planning. We derive and implement this objective, which encourages better prediction on trajectories with larger returns. We observe empirically that our approach improves the performance of current MBRL algorithms on two stochastic control problems, and provide a theoretical basis for our method.
Meta-Learning Symmetries by Reparameterization
Jul 06, 2020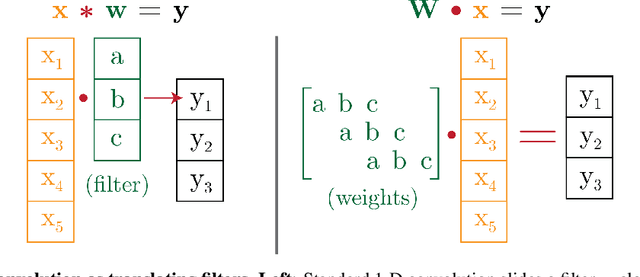

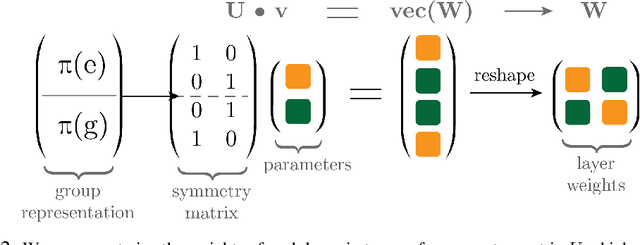

Many successful deep learning architectures are equivariant to certain transformations in order to conserve parameters and improve generalization: most famously, convolution layers are equivariant to shifts of the input. This approach only works when practitioners know a-priori symmetries of the task and can manually construct an architecture with the corresponding equivariances. Our goal is a general approach for learning equivariances from data, without needing prior knowledge of a task's symmetries or custom task-specific architectures. We present a method for learning and encoding equivariances into networks by learning corresponding parameter sharing patterns from data. Our method can provably encode equivariance-inducing parameter sharing for any finite group of symmetry transformations, and we find experimentally that it can automatically learn a variety of equivariances from symmetries in data. We provide our experiment code and pre-trained models at https://github.com/AllanYangZhou/metalearning-symmetries.
Watch, Try, Learn: Meta-Learning from Demonstrations and Reward
Jun 07, 2019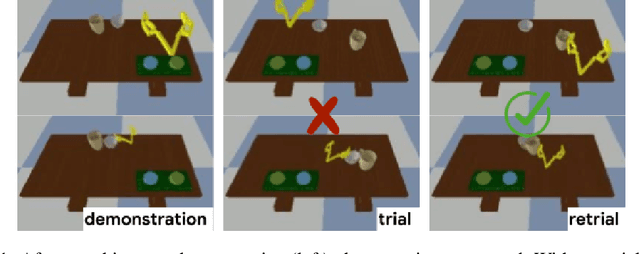
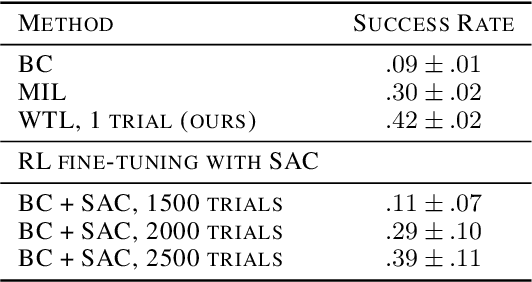
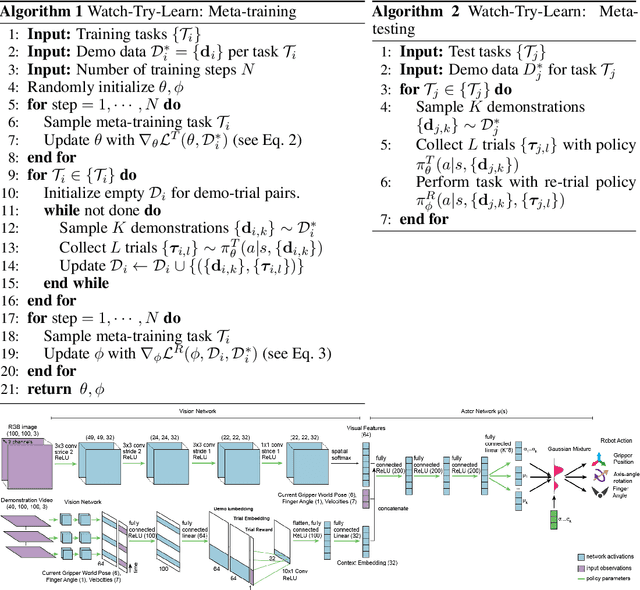
Imitation learning allows agents to learn complex behaviors from demonstrations. However, learning a complex vision-based task may require an impractical number of demonstrations. Meta-imitation learning is a promising approach towards enabling agents to learn a new task from one or a few demonstrations by leveraging experience from learning similar tasks. In the presence of task ambiguity or unobserved dynamics, demonstrations alone may not provide enough information; an agent must also try the task to successfully infer a policy. In this work, we propose a method that can learn to learn from both demonstrations and trial-and-error experience with sparse reward feedback. In comparison to meta-imitation, this approach enables the agent to effectively and efficiently improve itself autonomously beyond the demonstration data. In comparison to meta-reinforcement learning, we can scale to substantially broader distributions of tasks, as the demonstration reduces the burden of exploration. Our experiments show that our method significantly outperforms prior approaches on a set of challenging, vision-based control tasks.