 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Deep Networks Transfer Invariances Across Classes?
Mar 18, 2022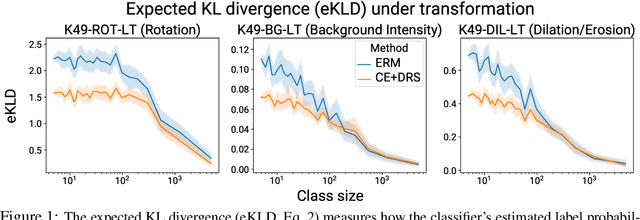
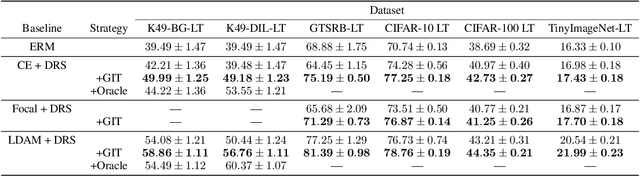
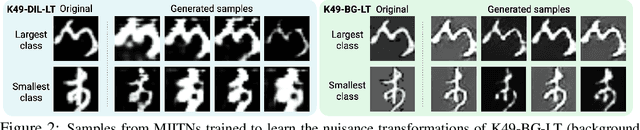
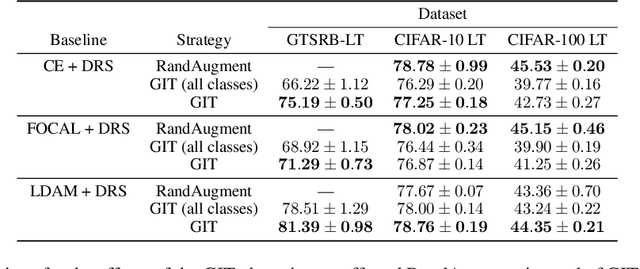
To generalize well, classifiers must learn to be invariant to nuisance transformations that do not alter an input's class. Many problems have "class-agnostic" nuisance transformations that apply similarly to all classes, such as lighting and background changes for image classification. Neural networks can learn these invariances given sufficient data, but many real-world datasets are heavily class imbalanced and contain only a few examples for most of the classes. We therefore pose the question: how well do neural networks transfer class-agnostic invariances learned from the large classes to the small ones? Through careful experimentation, we observe that invariance to class-agnostic transformations is still heavily dependent on class size, with the networks being much less invariant on smaller classes. This result holds even when using data balancing techniques, and suggests poor invariance transfer across classes. Our results provide one explanation for why classifiers generalize poorly on unbalanced and long-tailed distributions. Based on this analysis, we show how a generative approach for learning the nuisance transformations can help transfer invariances across classes and improve performance on a set of imbalanced image classification benchmarks. Source code for our experiments is available at https://github.com/AllanYangZhou/generative-invariance-transfer.
Meta-Learning Symmetries by Reparameterization
Jul 06, 2020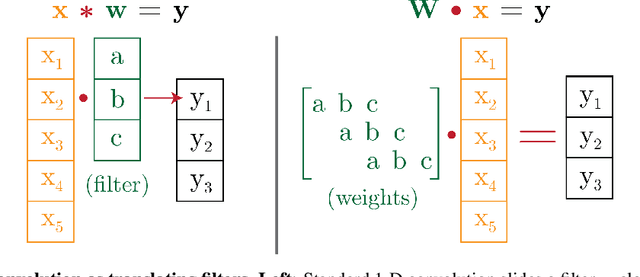

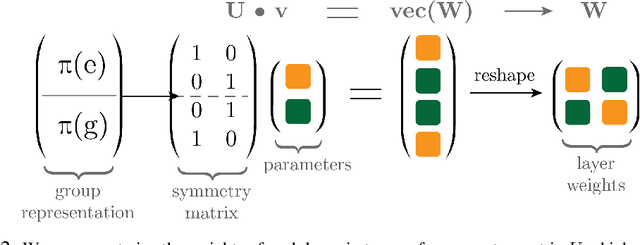

Many successful deep learning architectures are equivariant to certain transformations in order to conserve parameters and improve generalization: most famously, convolution layers are equivariant to shifts of the input. This approach only works when practitioners know a-priori symmetries of the task and can manually construct an architecture with the corresponding equivariances. Our goal is a general approach for learning equivariances from data, without needing prior knowledge of a task's symmetries or custom task-specific architectures. We present a method for learning and encoding equivariances into networks by learning corresponding parameter sharing patterns from data. Our method can provably encode equivariance-inducing parameter sharing for any finite group of symmetry transformations, and we find experimentally that it can automatically learn a variety of equivariances from symmetries in data. We provide our experiment code and pre-trained models at https://github.com/AllanYangZhou/metalearning-symmetries.