 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework to Assess agreement Among Diverse Rater Groups
Nov 09, 2023Recent advancements in conversational AI have created an urgent need for safety guardrails that prevent users from being exposed to offensive and dangerous content. Much of this work relies on human ratings and feedback, but does not account for the fact that perceptions of offense and safety are inherently subjective and that there may be systematic disagreements between raters that align with their socio-demographic identities. Instead, current machine learning approaches largely ignore rater subjectivity and use gold standards that obscure disagreements (e.g., through majority voting). In order to better understand the socio-cultural leanings of such tasks, we propose a comprehensive disagreement analysis framework to measure systematic diversity in perspectives among different rater subgroups. We then demonstrate its utility by applying this framework to a dataset of human-chatbot conversations rated by a demographically diverse pool of raters. Our analysis reveals specific rater groups that have more diverse perspectives than the rest, and informs demographic axes that are crucial to consider for safety annotations.
"Is a picture of a bird a bird": Policy recommendations for dealing with ambiguity in machine vision models
Jun 27, 2023



Many questions that we ask about the world do not have a single clear answer, yet typical human annotation set-ups in machine learning assume there must be a single ground truth label for all examples in every task. The divergence between reality and practice is stark, especially in cases with inherent ambiguity and where the range of different subjective judgments is wide. Here, we examine the implications of subjective human judgments in the behavioral task of labeling images used to train machine vision models. We identify three primary sources of ambiguity arising from (i) depictions of labels in the images, (ii) raters' backgrounds, and (iii) the task definition. On the basis of the empirical results, we suggest best practices for handling label ambiguity in machine learning datasets.
Inverse Scaling: When Bigger Isn't Better
Jun 15, 2023



Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
Two Failures of Self-Consistency in the Multi-Step Reasoning of LLMs
May 23, 2023



Large language models (LLMs) have achieved widespread success on a variety of in-context few-shot tasks, but this success is typically evaluated via correctness rather than consistency. We argue that self-consistency is an important criteria for valid multi-step reasoning and propose two types of self-consistency that are particularly important for multi-step logic -- hypothetical consistency (the ability for a model to predict what its output would be in a hypothetical other context) and compositional consistency (consistency of a model's outputs for a compositional task even when an intermediate step is replaced with the model's output for that step). We demonstrate that four sizes of the GPT-3 model exhibit poor consistency rates across both types of consistency on four different tasks (Wikipedia, DailyDialog, arithmetic, and GeoQuery).
Adversarial Nibbler: A Data-Centric Challenge for Improving the Safety of Text-to-Image Models
May 22, 2023


The generative AI revolution in recent years has been spurred by an expansion in compute power and data quantity, which together enable extensive pre-training of powerful text-to-image (T2I) models. With their greater capabilities to generate realistic and creative content, these T2I models like DALL-E, MidJourney, Imagen or Stable Diffusion are reaching ever wider audiences. Any unsafe behaviors inherited from pretraining on uncurated internet-scraped datasets thus have the potential to cause wide-reaching harm, for example, through generated images which are violent, sexually explicit, or contain biased and derogatory stereotypes. Despite this risk of harm, we lack systematic and structured evaluation datasets to scrutinize model behavior, especially adversarial attacks that bypass existing safety filters. A typical bottleneck in safety evaluation is achieving a wide coverage of different types of challenging examples in the evaluation set, i.e., identifying 'unknown unknowns' or long-tail problems. To address this need, we introduce the Adversarial Nibbler challenge. The goal of this challenge is to crowdsource a diverse set of failure modes and reward challenge participants for successfully finding safety vulnerabilities in current state-of-the-art T2I models. Ultimately, we aim to provide greater awareness of these issues and assist developers in improving the future safety and reliability of generative AI models. Adversarial Nibbler is a data-centric challenge, part of the DataPerf challenge suite, organized and supported by Kaggle and MLCommons.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Two-Turn Debate Doesn't Help Humans Answer Hard Reading Comprehension Questions
Oct 19, 2022
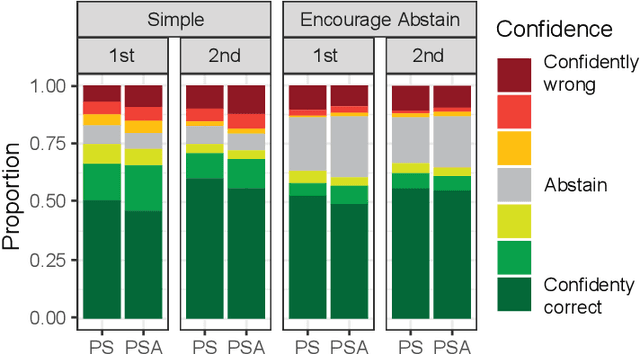
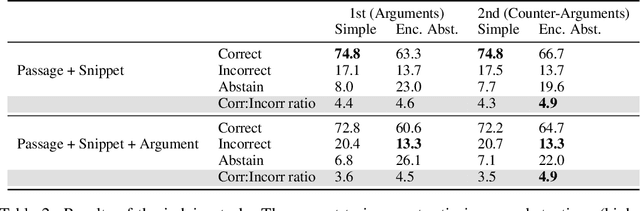
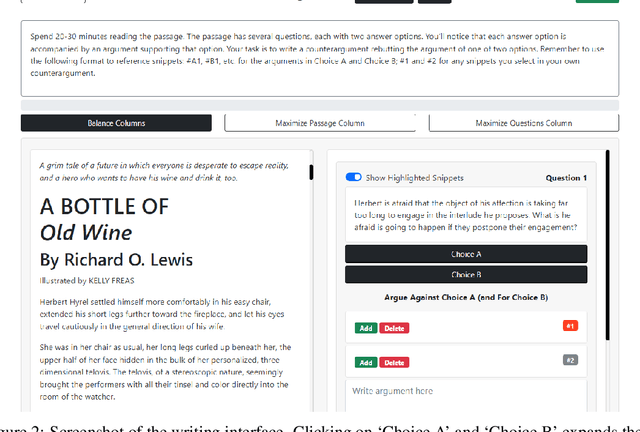
The use of language-model-based question-answering systems to aid humans in completing difficult tasks is limited, in part, by the unreliability of the text these systems generate. Using hard multiple-choice reading comprehension questions as a testbed, we assess whether presenting humans with arguments for two competing answer options, where one is correct and the other is incorrect, allows human judges to perform more accurately, even when one of the arguments is unreliable and deceptive. If this is helpful, we may be able to increase our justified trust in language-model-based systems by asking them to produce these arguments where needed. Previous research has shown that just a single turn of arguments in this format is not helpful to humans. However, as debate settings are characterized by a back-and-forth dialogue, we follow up on previous results to test whether adding a second round of counter-arguments is helpful to humans. We find that, regardless of whether they have access to arguments or not, humans perform similarly on our task. These findings suggest that, in the case of answering reading comprehension questions, debate is not a helpful format.
What Do NLP Researchers Believe? Results of the NLP Community Metasurvey
Aug 26, 2022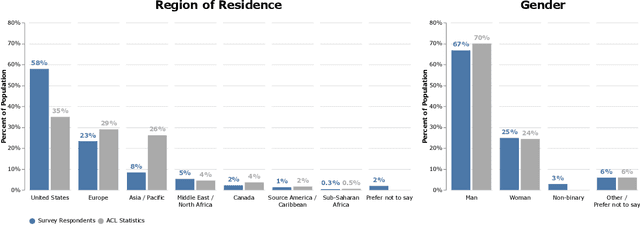

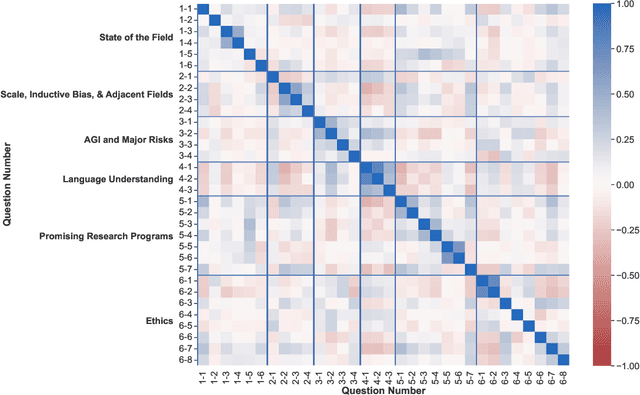
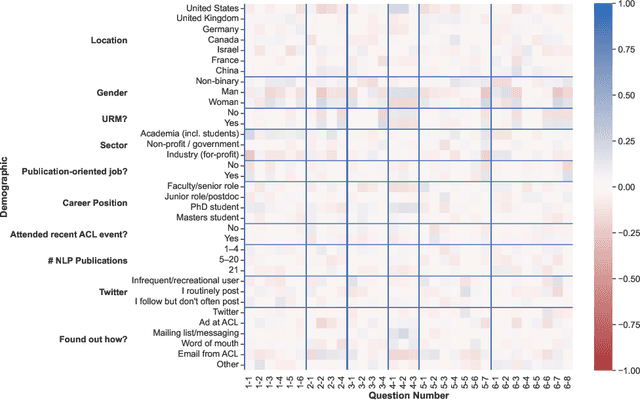
We present the results of the NLP Community Metasurvey. Run from May to June 2022, the survey elicited opinions on controversial issues, including industry influence in the field, concerns about AGI, and ethics. Our results put concrete numbers to several controversies: For example, respondents are split almost exactly in half on questions about the importance of artificial general intelligence, whether language models understand language, and the necessity of linguistic structure and inductive bias for solving NLP problems. In addition, the survey posed meta-questions, asking respondents to predict the distribution of survey responses. This allows us not only to gain insight on the spectrum of beliefs held by NLP researchers, but also to uncover false sociological beliefs where the community's predictions don't match reality. We find such mismatches on a wide range of issues. Among other results, the community greatly overestimates its own belief in the usefulness of benchmarks and the potential for scaling to solve real-world problems, while underestimating its own belief in the importance of linguistic structure, inductive bias, and interdisciplinary science.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Single-Turn Debate Does Not Help Humans Answer Hard Reading-Comprehension Questions
Apr 13, 2022
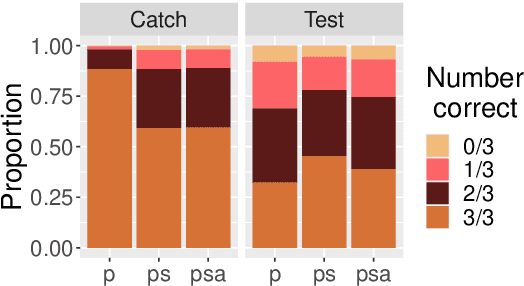
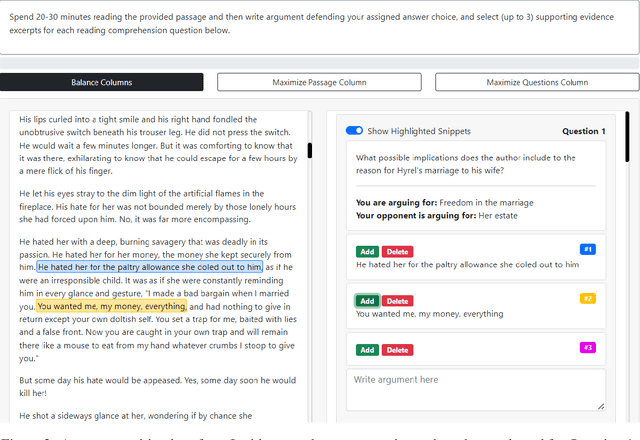
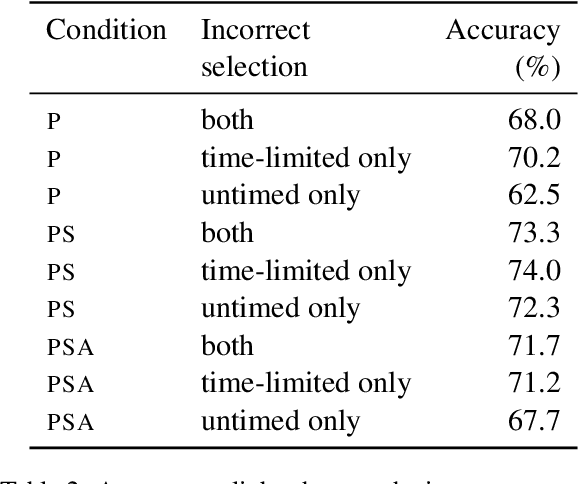
Current QA systems can generate reasonable-sounding yet false answers without explanation or evidence for the generated answer, which is especially problematic when humans cannot readily check the model's answers. This presents a challenge for building trust in machine learning systems. We take inspiration from real-world situations where difficult questions are answered by considering opposing sides (see Irving et al., 2018). For multiple-choice QA examples, we build a dataset of single arguments for both a correct and incorrect answer option in a debate-style set-up as an initial step in training models to produce explanations for two candidate answers. We use long contexts -- humans familiar with the context write convincing explanations for pre-selected correct and incorrect answers, and we test if those explanations allow humans who have not read the full context to more accurately determine the correct answer. We do not find that explanations in our set-up improve human accuracy, but a baseline condition shows that providing human-selected text snippets does improve accuracy. We use these findings to suggest ways of improving the debate set up for future data collection efforts.