 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: AI Competitions Provide the Gold Standard for Empirical Rigor in GenAI Evaluation
May 01, 2025In this position paper, we observe that empirical evaluation in Generative AI is at a crisis point since traditional ML evaluation and benchmarking strategies are insufficient to meet the needs of evaluating modern GenAI models and systems. There are many reasons for this, including the fact that these models typically have nearly unbounded input and output spaces, typically do not have a well defined ground truth target, and typically exhibit strong feedback loops and prediction dependence based on context of previous model outputs. On top of these critical issues, we argue that the problems of {\em leakage} and {\em contamination} are in fact the most important and difficult issues to address for GenAI evaluations. Interestingly, the field of AI Competitions has developed effective measures and practices to combat leakage for the purpose of counteracting cheating by bad actors within a competition setting. This makes AI Competitions an especially valuable (but underutilized) resource. Now is time for the field to view AI Competitions as the gold standard for empirical rigor in GenAI evaluation, and to harness and harvest their results with according value.
Adversarial Nibbler: A Data-Centric Challenge for Improving the Safety of Text-to-Image Models
May 22, 2023


The generative AI revolution in recent years has been spurred by an expansion in compute power and data quantity, which together enable extensive pre-training of powerful text-to-image (T2I) models. With their greater capabilities to generate realistic and creative content, these T2I models like DALL-E, MidJourney, Imagen or Stable Diffusion are reaching ever wider audiences. Any unsafe behaviors inherited from pretraining on uncurated internet-scraped datasets thus have the potential to cause wide-reaching harm, for example, through generated images which are violent, sexually explicit, or contain biased and derogatory stereotypes. Despite this risk of harm, we lack systematic and structured evaluation datasets to scrutinize model behavior, especially adversarial attacks that bypass existing safety filters. A typical bottleneck in safety evaluation is achieving a wide coverage of different types of challenging examples in the evaluation set, i.e., identifying 'unknown unknowns' or long-tail problems. To address this need, we introduce the Adversarial Nibbler challenge. The goal of this challenge is to crowdsource a diverse set of failure modes and reward challenge participants for successfully finding safety vulnerabilities in current state-of-the-art T2I models. Ultimately, we aim to provide greater awareness of these issues and assist developers in improving the future safety and reliability of generative AI models. Adversarial Nibbler is a data-centric challenge, part of the DataPerf challenge suite, organized and supported by Kaggle and MLCommons.
Challenges in Representation Learning: A report on three machine learning contests
Jul 01, 2013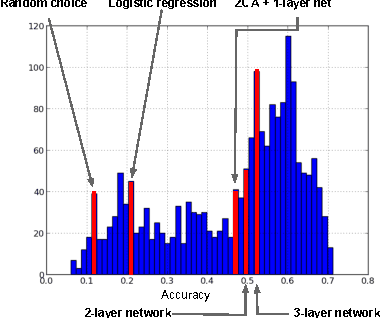

The ICML 2013 Workshop on Challenges in Representation Learning focused on three challenges: the black box learning challenge, the facial expression recognition challenge, and the multimodal learning challenge. We describe the datasets created for these challenges and summarize the results of the competitions. We provide suggestions for organizers of future challenges and some comments on what kind of knowledge can be gained from machine learning competitions.