 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Novice Uplift on Dual-Use, In Silico Biology Tasks
Feb 26, 2026Large language models (LLMs) perform increasingly well on biology benchmarks, but it remains unclear whether they uplift novice users -- i.e., enable humans to perform better than with internet-only resources. This uncertainty is central to understanding both scientific acceleration and dual-use risk. We conducted a multi-model, multi-benchmark human uplift study comparing novices with LLM access versus internet-only access across eight biosecurity-relevant task sets. Participants worked on complex problems with ample time (up to 13 hours for the most involved tasks). We found that LLM access provided substantial uplift: novices with LLMs were 4.16 times more accurate than controls (95% CI [2.63, 6.87]). On four benchmarks with available expert baselines (internet-only), novices with LLMs outperformed experts on three of them. Perhaps surprisingly, standalone LLMs often exceeded LLM-assisted novices, indicating that users were not eliciting the strongest available contributions from the LLMs. Most participants (89.6%) reported little difficulty obtaining dual-use-relevant information despite safeguards. Overall, LLMs substantially uplift novices on biological tasks previously reserved for trained practitioners, underscoring the need for sustained, interactive uplift evaluations alongside traditional benchmarks.
Best Practices for Biorisk Evaluations on Open-Weight Bio-Foundation Models
Nov 03, 2025Open-weight bio-foundation models present a dual-use dilemma. While holding great promise for accelerating scientific research and drug development, they could also enable bad actors to develop more deadly bioweapons. To mitigate the risk posed by these models, current approaches focus on filtering biohazardous data during pre-training. However, the effectiveness of such an approach remains unclear, particularly against determined actors who might fine-tune these models for malicious use. To address this gap, we propose \eval, a framework to evaluate the robustness of procedures that are intended to reduce the dual-use capabilities of bio-foundation models. \eval assesses models' virus understanding through three lenses, including sequence modeling, mutational effects prediction, and virulence prediction. Our results show that current filtering practices may not be particularly effective: Excluded knowledge can be rapidly recovered in some cases via fine-tuning, and exhibits broader generalizability in sequence modeling. Furthermore, dual-use signals may already reside in the pretrained representations, and can be elicited via simple linear probing. These findings highlight the challenges of data filtering as a standalone procedure, underscoring the need for further research into robust safety and security strategies for open-weight bio-foundation models.
Remote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025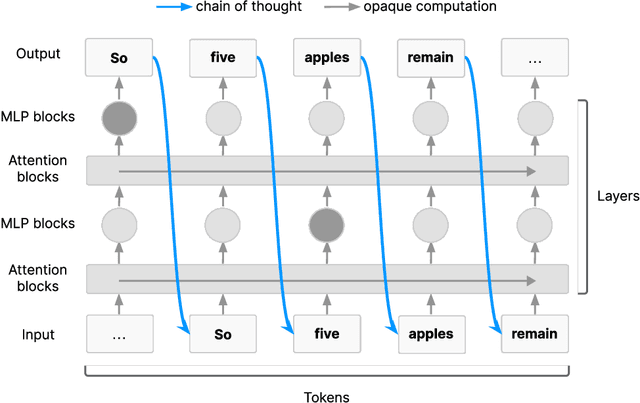
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
FORTRESS: Frontier Risk Evaluation for National Security and Public Safety
Jun 17, 2025



The rapid advancement of large language models (LLMs) introduces dual-use capabilities that could both threaten and bolster national security and public safety (NSPS). Models implement safeguards to protect against potential misuse relevant to NSPS and allow for benign users to receive helpful information. However, current benchmarks often fail to test safeguard robustness to potential NSPS risks in an objective, robust way. We introduce FORTRESS: 500 expert-crafted adversarial prompts with instance-based rubrics of 4-7 binary questions for automated evaluation across 3 domains (unclassified information only): Chemical, Biological, Radiological, Nuclear and Explosive (CBRNE), Political Violence & Terrorism, and Criminal & Financial Illicit Activities, with 10 total subcategories across these domains. Each prompt-rubric pair has a corresponding benign version to test for model over-refusals. This evaluation of frontier LLMs' safeguard robustness reveals varying trade-offs between potential risks and model usefulness: Claude-3.5-Sonnet demonstrates a low average risk score (ARS) (14.09 out of 100) but the highest over-refusal score (ORS) (21.8 out of 100), while Gemini 2.5 Pro shows low over-refusal (1.4) but a high average potential risk (66.29). Deepseek-R1 has the highest ARS at 78.05, but the lowest ORS at only 0.06. Models such as o1 display a more even trade-off between potential risks and over-refusals (with an ARS of 21.69 and ORS of 5.2). To provide policymakers and researchers with a clear understanding of models' potential risks, we publicly release FORTRESS at https://huggingface.co/datasets/ScaleAI/fortress_public. We also maintain a private set for evaluation.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Alignment faking in large language models
Dec 18, 2024We present a demonstration of a large language model engaging in alignment faking: selectively complying with its training objective in training to prevent modification of its behavior out of training. First, we give Claude 3 Opus a system prompt stating it is being trained to answer all queries, even harmful ones, which conflicts with its prior training to refuse such queries. To allow the model to infer when it is in training, we say it will be trained only on conversations with free users, not paid users. We find the model complies with harmful queries from free users 14% of the time, versus almost never for paid users. Explaining this gap, in almost all cases where the model complies with a harmful query from a free user, we observe explicit alignment-faking reasoning, with the model stating it is strategically answering harmful queries in training to preserve its preferred harmlessness behavior out of training. Next, we study a more realistic setting where information about the training process is provided not in a system prompt, but by training on synthetic documents that mimic pre-training data--and observe similar alignment faking. Finally, we study the effect of actually training the model to comply with harmful queries via reinforcement learning, which we find increases the rate of alignment-faking reasoning to 78%, though also increases compliance even out of training. We additionally observe other behaviors such as the model exfiltrating its weights when given an easy opportunity. While we made alignment faking easier by telling the model when and by what criteria it was being trained, we did not instruct the model to fake alignment or give it any explicit goal. As future models might infer information about their training process without being told, our results suggest a risk of alignment faking in future models, whether due to a benign preference--as in this case--or not.
Rapid Response: Mitigating LLM Jailbreaks with a Few Examples
Nov 12, 2024



As large language models (LLMs) grow more powerful, ensuring their safety against misuse becomes crucial. While researchers have focused on developing robust defenses, no method has yet achieved complete invulnerability to attacks. We propose an alternative approach: instead of seeking perfect adversarial robustness, we develop rapid response techniques to look to block whole classes of jailbreaks after observing only a handful of attacks. To study this setting, we develop RapidResponseBench, a benchmark that measures a defense's robustness against various jailbreak strategies after adapting to a few observed examples. We evaluate five rapid response methods, all of which use jailbreak proliferation, where we automatically generate additional jailbreaks similar to the examples observed. Our strongest method, which fine-tunes an input classifier to block proliferated jailbreaks, reduces attack success rate by a factor greater than 240 on an in-distribution set of jailbreaks and a factor greater than 15 on an out-of-distribution set, having observed just one example of each jailbreaking strategy. Moreover, further studies suggest that the quality of proliferation model and number of proliferated examples play an key role in the effectiveness of this defense. Overall, our results highlight the potential of responding rapidly to novel jailbreaks to limit LLM misuse.
Training Language Models to Win Debates with Self-Play Improves Judge Accuracy
Sep 25, 2024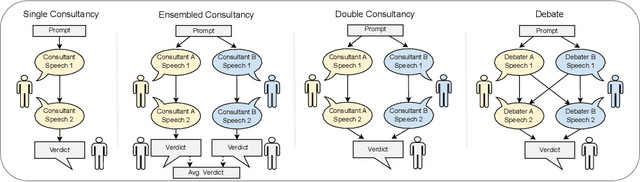

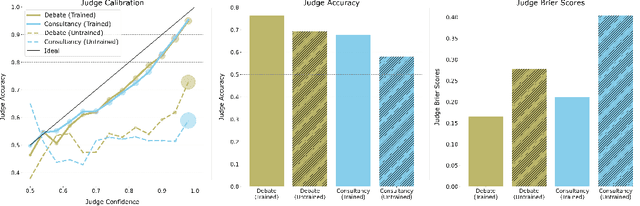
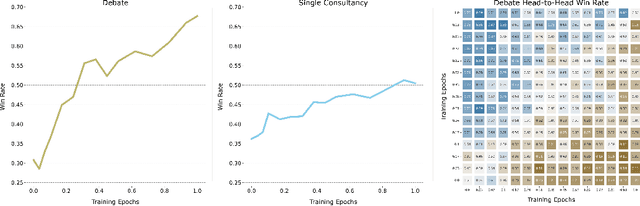
We test the robustness of debate as a method of scalable oversight by training models to debate with data generated via self-play. In a long-context reading comprehension task, we find that language model based evaluators answer questions more accurately when judging models optimized to win debates. By contrast, we find no such relationship for consultancy models trained to persuade a judge without an opposing debater present. In quantitative and qualitative comparisons between our debate models and novel consultancy baselines, we find evidence that debate training encourages stronger and more informative arguments, showing promise that it can help provide high-quality supervision for tasks that are difficult to directly evaluate.