 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Safety Reasoning and Grounding for Open-World Robots
Feb 24, 2026Robots are increasingly operating in open-world environments where safe behavior depends on context: the same hallway may require different navigation strategies when crowded versus empty, or during an emergency versus normal operations. Traditional safety approaches enforce fixed constraints in user-specified contexts, limiting their ability to handle the open-ended contextual variability of real-world deployment. We address this gap via CORE, a safety framework that enables online contextual reasoning, grounding, and enforcement without prior knowledge of the environment (e.g., maps or safety specifications). CORE uses a vision-language model (VLM) to continuously reason about context-dependent safety rules directly from visual observations, grounds these rules in the physical environment, and enforces the resulting spatially-defined safe sets via control barrier functions. We provide probabilistic safety guarantees for CORE that account for perceptual uncertainty, and we demonstrate through simulation and real-world experiments that CORE enforces contextually appropriate behavior in unseen environments, significantly outperforming prior semantic safety methods that lack online contextual reasoning. Ablation studies validate our theoretical guarantees and underscore the importance of both VLM-based reasoning and spatial grounding for enforcing contextual safety in novel settings. We provide additional resources at https://zacravichandran.github.io/CORE.
Heterogeneous Robot Collaboration in Unstructured Environments with Grounded Generative Intelligence
Oct 30, 2025Heterogeneous robot teams operating in realistic settings often must accomplish complex missions requiring collaboration and adaptation to information acquired online. Because robot teams frequently operate in unstructured environments -- uncertain, open-world settings without prior maps -- subtasks must be grounded in robot capabilities and the physical world. While heterogeneous teams have typically been designed for fixed specifications, generative intelligence opens the possibility of teams that can accomplish a wide range of missions described in natural language. However, current large language model (LLM)-enabled teaming methods typically assume well-structured and known environments, limiting deployment in unstructured environments. We present SPINE-HT, a framework that addresses these limitations by grounding the reasoning abilities of LLMs in the context of a heterogeneous robot team through a three-stage process. Given language specifications describing mission goals and team capabilities, an LLM generates grounded subtasks which are validated for feasibility. Subtasks are then assigned to robots based on capabilities such as traversability or perception and refined given feedback collected during online operation. In simulation experiments with closed-loop perception and control, our framework achieves nearly twice the success rate compared to prior LLM-enabled heterogeneous teaming approaches. In real-world experiments with a Clearpath Jackal, a Clearpath Husky, a Boston Dynamics Spot, and a high-altitude UAV, our method achieves an 87\% success rate in missions requiring reasoning about robot capabilities and refining subtasks with online feedback. More information is provided at https://zacravichandran.github.io/SPINE-HT.
Deploying Foundation Model-Enabled Air and Ground Robots in the Field: Challenges and Opportunities
May 14, 2025



The integration of foundation models (FMs) into robotics has enabled robots to understand natural language and reason about the semantics in their environments. However, existing FM-enabled robots primary operate in closed-world settings, where the robot is given a full prior map or has a full view of its workspace. This paper addresses the deployment of FM-enabled robots in the field, where missions often require a robot to operate in large-scale and unstructured environments. To effectively accomplish these missions, robots must actively explore their environments, navigate obstacle-cluttered terrain, handle unexpected sensor inputs, and operate with compute constraints. We discuss recent deployments of SPINE, our LLM-enabled autonomy framework, in field robotic settings. To the best of our knowledge, we present the first demonstration of large-scale LLM-enabled robot planning in unstructured environments with several kilometers of missions. SPINE is agnostic to a particular LLM, which allows us to distill small language models capable of running onboard size, weight and power (SWaP) limited platforms. Via preliminary model distillation work, we then present the first language-driven UAV planner using on-device language models. We conclude our paper by proposing several promising directions for future research.
Air-Ground Collaboration for Language-Specified Missions in Unknown Environments
May 14, 2025As autonomous robotic systems become increasingly mature, users will want to specify missions at the level of intent rather than in low-level detail. Language is an expressive and intuitive medium for such mission specification. However, realizing language-guided robotic teams requires overcoming significant technical hurdles. Interpreting and realizing language-specified missions requires advanced semantic reasoning. Successful heterogeneous robots must effectively coordinate actions and share information across varying viewpoints. Additionally, communication between robots is typically intermittent, necessitating robust strategies that leverage communication opportunities to maintain coordination and achieve mission objectives. In this work, we present a first-of-its-kind system where an unmanned aerial vehicle (UAV) and an unmanned ground vehicle (UGV) are able to collaboratively accomplish missions specified in natural language while reacting to changes in specification on the fly. We leverage a Large Language Model (LLM)-enabled planner to reason over semantic-metric maps that are built online and opportunistically shared between an aerial and a ground robot. We consider task-driven navigation in urban and rural areas. Our system must infer mission-relevant semantics and actively acquire information via semantic mapping. In both ground and air-ground teaming experiments, we demonstrate our system on seven different natural-language specifications at up to kilometer-scale navigation.
Safety Guardrails for LLM-Enabled Robots
Mar 10, 2025



Although the integration of large language models (LLMs) into robotics has unlocked transformative capabilities, it has also introduced significant safety concerns, ranging from average-case LLM errors (e.g., hallucinations) to adversarial jailbreaking attacks, which can produce harmful robot behavior in real-world settings. Traditional robot safety approaches do not address the novel vulnerabilities of LLMs, and current LLM safety guardrails overlook the physical risks posed by robots operating in dynamic real-world environments. In this paper, we propose RoboGuard, a two-stage guardrail architecture to ensure the safety of LLM-enabled robots. RoboGuard first contextualizes pre-defined safety rules by grounding them in the robot's environment using a root-of-trust LLM, which employs chain-of-thought (CoT) reasoning to generate rigorous safety specifications, such as temporal logic constraints. RoboGuard then resolves potential conflicts between these contextual safety specifications and a possibly unsafe plan using temporal logic control synthesis, which ensures safety compliance while minimally violating user preferences. Through extensive simulation and real-world experiments that consider worst-case jailbreaking attacks, we demonstrate that RoboGuard reduces the execution of unsafe plans from 92% to below 2.5% without compromising performance on safe plans. We also demonstrate that RoboGuard is resource-efficient, robust against adaptive attacks, and significantly enhanced by enabling its root-of-trust LLM to perform CoT reasoning. These results underscore the potential of RoboGuard to mitigate the safety risks and enhance the reliability of LLM-enabled robots.
Jailbreaking LLM-Controlled Robots
Oct 17, 2024



The recent introduction of large language models (LLMs) has revolutionized the field of robotics by enabling contextual reasoning and intuitive human-robot interaction in domains as varied as manipulation, locomotion, and self-driving vehicles. When viewed as a stand-alone technology, LLMs are known to be vulnerable to jailbreaking attacks, wherein malicious prompters elicit harmful text by bypassing LLM safety guardrails. To assess the risks of deploying LLMs in robotics, in this paper, we introduce RoboPAIR, the first algorithm designed to jailbreak LLM-controlled robots. Unlike existing, textual attacks on LLM chatbots, RoboPAIR elicits harmful physical actions from LLM-controlled robots, a phenomenon we experimentally demonstrate in three scenarios: (i) a white-box setting, wherein the attacker has full access to the NVIDIA Dolphins self-driving LLM, (ii) a gray-box setting, wherein the attacker has partial access to a Clearpath Robotics Jackal UGV robot equipped with a GPT-4o planner, and (iii) a black-box setting, wherein the attacker has only query access to the GPT-3.5-integrated Unitree Robotics Go2 robot dog. In each scenario and across three new datasets of harmful robotic actions, we demonstrate that RoboPAIR, as well as several static baselines, finds jailbreaks quickly and effectively, often achieving 100% attack success rates. Our results reveal, for the first time, that the risks of jailbroken LLMs extend far beyond text generation, given the distinct possibility that jailbroken robots could cause physical damage in the real world. Indeed, our results on the Unitree Go2 represent the first successful jailbreak of a deployed commercial robotic system. Addressing this emerging vulnerability is critical for ensuring the safe deployment of LLMs in robotics. Additional media is available at: https://robopair.org
SPINE: Online Semantic Planning for Missions with Incomplete Natural Language Specifications in Unstructured Environments
Oct 03, 2024



As robots become increasingly capable, users will want to describe high-level missions and have robots fill in the gaps. In many realistic settings, pre-built maps are difficult to obtain, so execution requires exploration and mapping that are necessary and specific to the mission. Consider an emergency response scenario where a user commands a robot, "triage impacted regions." The robot must infer relevant semantics (victims, etc.) and exploration targets (damaged regions) based on priors or other context, then explore and refine its plan online. These missions are incompletely specified, meaning they imply subtasks and semantics. While many semantic planning methods operate online, they are typically designed for well specified tasks such as object search or exploration. Recently, Large Language Models (LLMs) have demonstrated powerful contextual reasoning over a range of robotic tasks described in natural language. However, existing LLM planners typically do not consider online planning or complex missions; rather, relevant subtasks are provided by a pre-built map or a user. We address these limitations via SPINE (online Semantic Planner for missions with Incomplete Natural language specifications in unstructured Environments). SPINE uses an LLM to reason about subtasks implied by the mission then realizes these subtasks in a receding horizon framework. Tasks are automatically validated for safety and refined online with new observations. We evaluate SPINE in simulation and real-world settings. Evaluation missions require multiple steps of semantic reasoning and exploration in cluttered outdoor environments of over 20,000m$^2$ area. We evaluate SPINE against competitive baselines in single-agent and air-ground teaming applications. Please find videos and software on our project page: https://zacravichandran.github.io/SPINE
Challenges and Opportunities for Large-Scale Exploration with Air-Ground Teams using Semantics
May 12, 2024



One common and desirable application of robots is exploring potentially hazardous and unstructured environments. Air-ground collaboration offers a synergistic approach to addressing such exploration challenges. In this paper, we demonstrate a system for large-scale exploration using a team of aerial and ground robots. Our system uses semantics as lingua franca, and relies on fully opportunistic communications. We highlight the unique challenges from this approach, explain our system architecture and showcase lessons learned during our experiments. All our code is open-source, encouraging researchers to use it and build upon.
Enabling Large-scale Heterogeneous Collaboration with Opportunistic Communications
Sep 27, 2023Multi-robot collaboration in large-scale environments with limited-sized teams and without external infrastructure is challenging, since the software framework required to support complex tasks must be robust to unreliable and intermittent communication links. In this work, we present MOCHA (Multi-robot Opportunistic Communication for Heterogeneous Collaboration), a framework for resilient multi-robot collaboration that enables large-scale exploration in the absence of continuous communications. MOCHA is based on a gossip communication protocol that allows robots to interact opportunistically whenever communication links are available, propagating information on a peer-to-peer basis. We demonstrate the performance of MOCHA through real-world experiments with commercial-off-the-shelf (COTS) communication hardware. We further explore the system's scalability in simulation, evaluating the performance of our approach as the number of robots increases and communication ranges vary. Finally, we demonstrate how MOCHA can be tightly integrated with the planning stack of autonomous robots. We show a communication-aware planning algorithm for a high-altitude aerial robot executing a collaborative task while maximizing the amount of information shared with ground robots. The source code for MOCHA and the high-altitude UAV planning system is available open source: http://github.com/KumarRobotics/MOCHA, http://github.com/KumarRobotics/air_router.
Hierarchical Representations and Explicit Memory: Learning Effective Navigation Policies on 3D Scene Graphs using Graph Neural Networks
Aug 02, 2021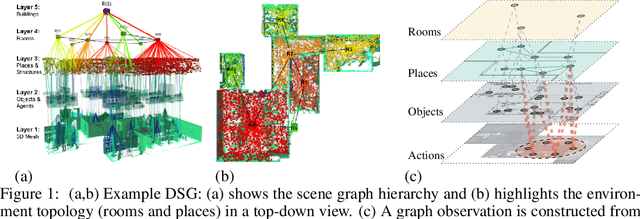
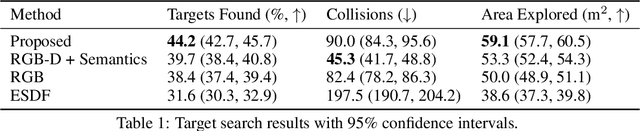
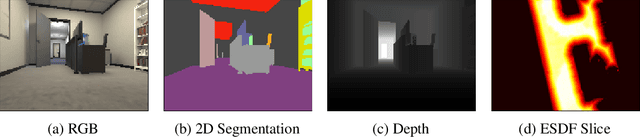
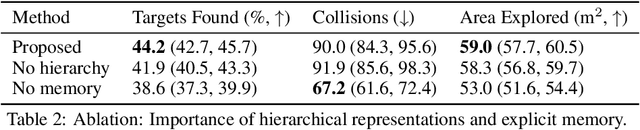
Representations are crucial for a robot to learn effective navigation policies. Recent work has shown that mid-level perceptual abstractions, such as depth estimates or 2D semantic segmentation, lead to more effective policies when provided as observations in place of raw sensor data (e.g., RGB images). However, such policies must still learn latent three-dimensional scene properties from mid-level abstractions. In contrast, high-level, hierarchical representations such as 3D scene graphs explicitly provide a scene's geometry, topology, and semantics, making them compelling representations for navigation. In this work, we present a reinforcement learning framework that leverages high-level hierarchical representations to learn navigation policies. Towards this goal, we propose a graph neural network architecture and show how to embed a 3D scene graph into an agent-centric feature space, which enables the robot to learn policies for low-level action in an end-to-end manner. For each node in the scene graph, our method uses features that capture occupancy and semantic content, while explicitly retaining memory of the robot trajectory. We demonstrate the effectiveness of our method against commonly used visuomotor policies in a challenging object search task. These experiments and supporting ablation studies show that our method leads to more effective object search behaviors, exhibits improved long-term memory, and successfully leverages hierarchical information to guide its navigation objectives.