 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Convolutional Neural Networks: A Robust and Interpretable Model for Object Recognition under Occlusion
Jun 28, 2020Computer vision systems in real-world applications need to be robust to partial occlusion while also being explainable. In this work, we show that black-box deep convolutional neural networks (DCNNs) have only limited robustness to partial occlusion. We overcome these limitations by unifying DCNNs with part-based models into Compositional Convolutional Neural Networks (CompositionalNets) - an interpretable deep architecture with innate robustness to partial occlusion. Specifically, we propose to replace the fully connected classification head of DCNNs with a differentiable compositional model that can be trained end-to-end. The structure of the compositional model enables CompositionalNets to decompose images into objects and context, as well as to further decompose object representations in terms of individual parts and the objects' pose. The generative nature of our compositional model enables it to localize occluders and to recognize objects based on their non-occluded parts. We conduct extensive experiments in terms of image classification and object detection on images of artificially occluded objects from the PASCAL3D+ and ImageNet dataset, and real images of partially occluded vehicles from the MS-COCO dataset. Our experiments show that CompositionalNets made from several popular DCNN backbones (VGG-16, ResNet50, ResNext) improve by a large margin over their non-compositional counterparts at classifying and detecting partially occluded objects. Furthermore, they can localize occluders accurately despite being trained with class-level supervision only. Finally, we demonstrate that CompositionalNets provide human interpretable predictions as their individual components can be understood as detecting parts and estimating an objects' viewpoint.
Smooth Adversarial Training
Jun 25, 2020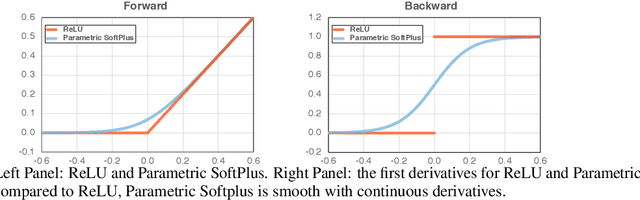

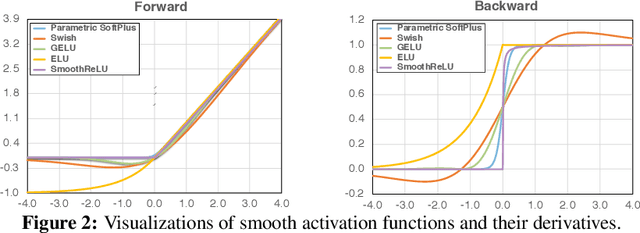
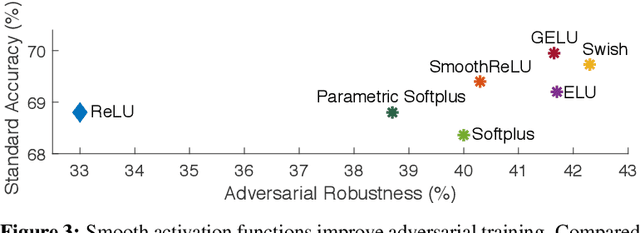
It is commonly believed that networks cannot be both accurate and robust, that gaining robustness means losing accuracy. It is also generally believed that, unless making networks larger, network architectural elements would otherwise matter little in improving adversarial robustness. Here we present evidence to challenge these common beliefs by a careful study about adversarial training. Our key observation is that the widely-used ReLU activation function significantly weakens adversarial training due to its non-smooth nature. Hence we propose smooth adversarial training (SAT), in which we replace ReLU with its smooth approximations to strengthen adversarial training. The purpose of smooth activation functions in SAT is to allow it to find harder adversarial examples and compute better gradient updates during adversarial training. Compared to standard adversarial training, SAT improves adversarial robustness for "free", i.e., no drop in accuracy and no increase in computational cost. For example, without introducing additional computations, SAT significantly enhances ResNet-50's robustness from 33.0% to 42.3%, while also improving accuracy by 0.9% on ImageNet. SAT also works well with larger networks: it helps EfficientNet-L1 to achieve 82.2% accuracy and 58.6% robustness on ImageNet, outperforming the previous state-of-the-art defense by 9.5% for accuracy and 11.6% for robustness.
DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
Jun 03, 2020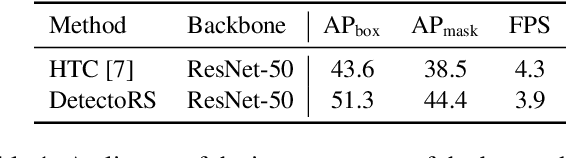
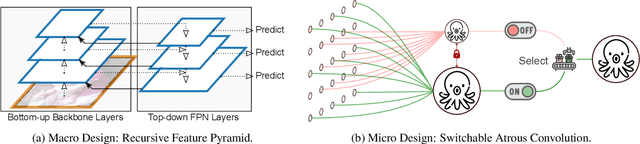
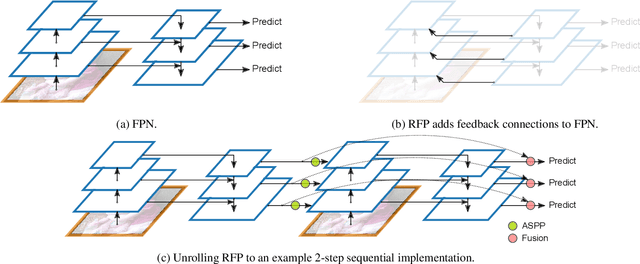

Many modern object detectors demonstrate outstanding performances by using the mechanism of looking and thinking twice. In this paper, we explore this mechanism in the backbone design for object detection. At the macro level, we propose Recursive Feature Pyramid, which incorporates extra feedback connections from Feature Pyramid Networks into the bottom-up backbone layers. At the micro level, we propose Switchable Atrous Convolution, which convolves the features with different atrous rates and gathers the results using switch functions. Combining them results in DetectoRS, which significantly improves the performances of object detection. On COCO test-dev, DetectoRS achieves state-of-the-art 54.7% box AP for object detection, 47.1% mask AP for instance segmentation, and 49.6% PQ for panoptic segmentation. The code is made publicly available.
Robust Object Detection under Occlusion with Context-Aware CompositionalNets
May 30, 2020
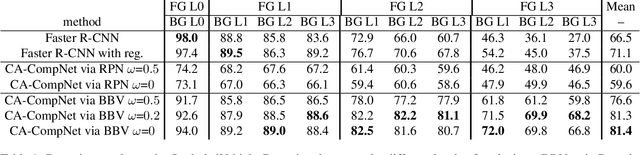

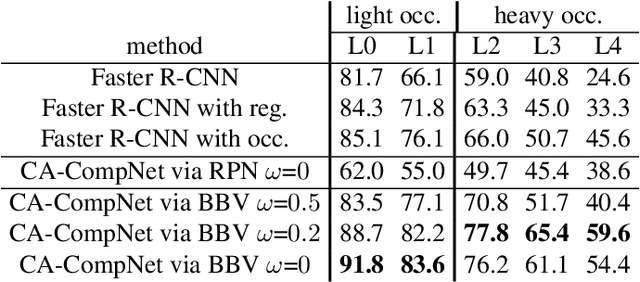
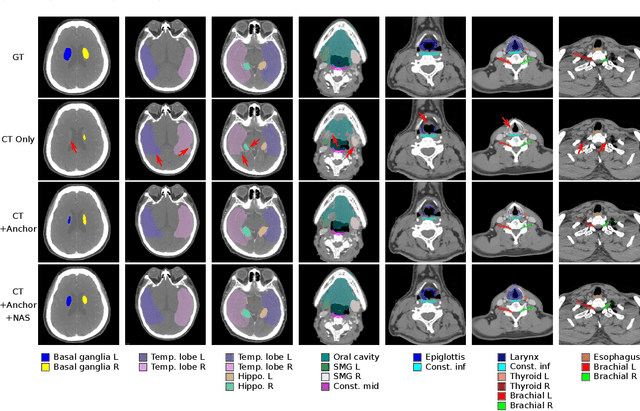
Detecting partially occluded objects is a difficult task. Our experimental results show that deep learning approaches, such as Faster R-CNN, are not robust at object detection under occlusion. Compositional convolutional neural networks (CompositionalNets) have been shown to be robust at classifying occluded objects by explicitly representing the object as a composition of parts. In this work, we propose to overcome two limitations of CompositionalNets which will enable them to detect partially occluded objects: 1) CompositionalNets, as well as other DCNN architectures, do not explicitly separate the representation of the context from the object itself. Under strong object occlusion, the influence of the context is amplified which can have severe negative effects for detection at test time. In order to overcome this, we propose to segment the context during training via bounding box annotations. We then use the segmentation to learn a context-aware CompositionalNet that disentangles the representation of the context and the object. 2) We extend the part-based voting scheme in CompositionalNets to vote for the corners of the object's bounding box, which enables the model to reliably estimate bounding boxes for partially occluded objects. Our extensive experiments show that our proposed model can detect objects robustly, increasing the detection performance of strongly occluded vehicles from PASCAL3D+ and MS-COCO by 41% and 35% respectively in absolute performance relative to Faster R-CNN.
Detecting Scatteredly-Distributed, Small, andCritically Important Objects in 3D OncologyImaging via Decision Stratification
May 27, 2020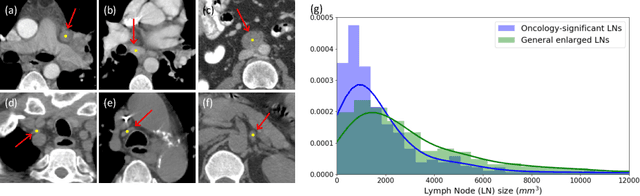
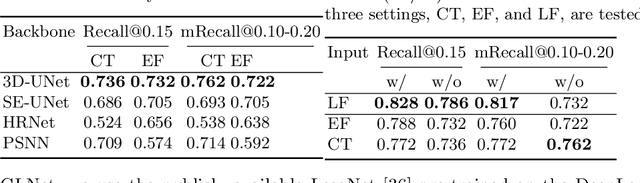
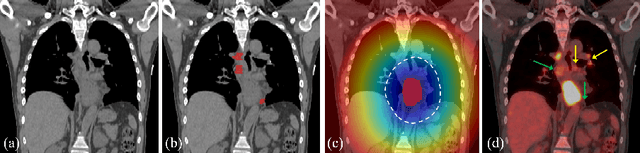
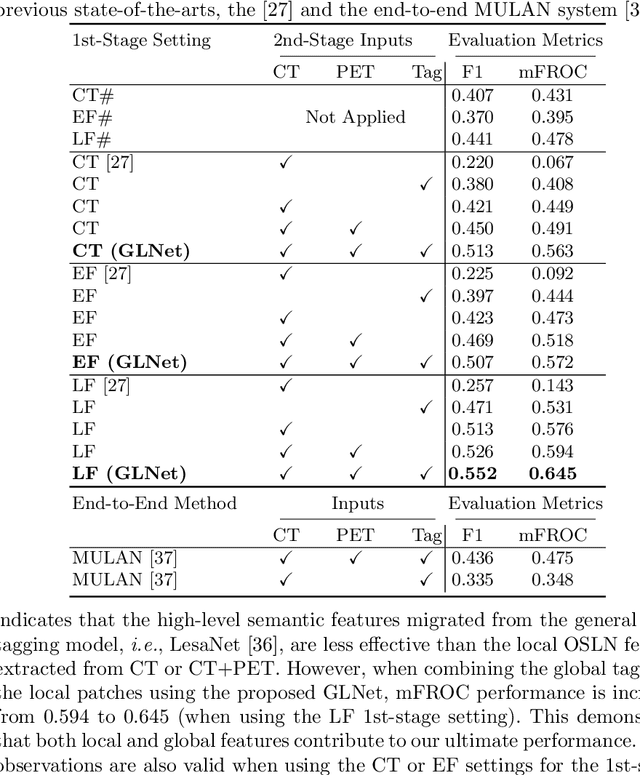
Finding and identifying scatteredly-distributed, small, and critically important objects in 3D oncology images is very challenging. We focus on the detection and segmentation of oncology-significant (or suspicious cancer metastasized) lymph nodes (OSLNs), which has not been studied before as a computational task. Determining and delineating the spread of OSLNs is essential in defining the corresponding resection/irradiating regions for the downstream workflows of surgical resection and radiotherapy of various cancers. For patients who are treated with radiotherapy, this task is performed by experienced radiation oncologists that involves high-level reasoning on whether LNs are metastasized, which is subject to high inter-observer variations. In this work, we propose a divide-and-conquer decision stratification approach that divides OSLNs into tumor-proximal and tumor-distal categories. This is motivated by the observation that each category has its own different underlying distributions in appearance, size and other characteristics. Two separate detection-by-segmentation networks are trained per category and fused. To further reduce false positives (FP), we present a novel global-local network (GLNet) that combines high-level lesion characteristics with features learned from localized 3D image patches. Our method is evaluated on a dataset of 141 esophageal cancer patients with PET and CT modalities (the largest to-date). Our results significantly improve the recall from $45\%$ to $67\%$ at $3$ FPs per patient as compared to previous state-of-the-art methods. The highest achieved OSLN recall of $0.828$ is clinically relevant and valuable.
JSSR: A Joint Synthesis, Segmentation, and Registration System for 3D Multi-Modal Image Alignment of Large-scale Pathological CT Scans
May 27, 2020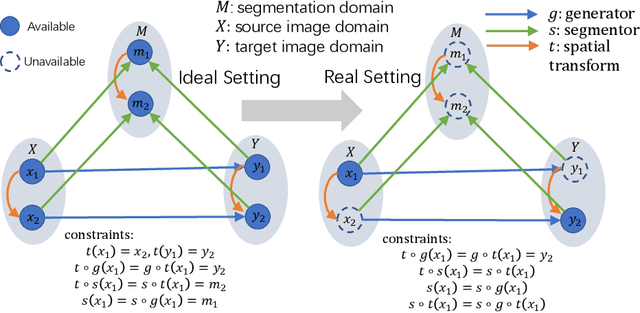
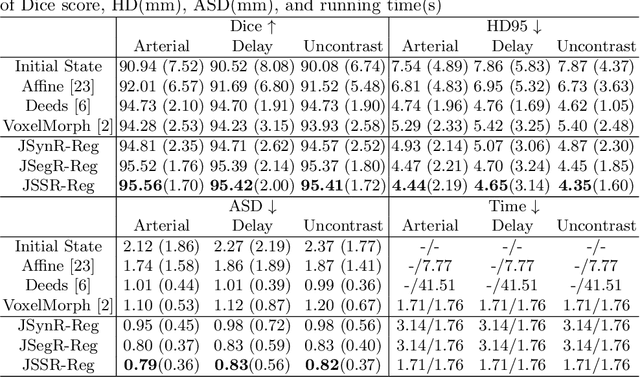
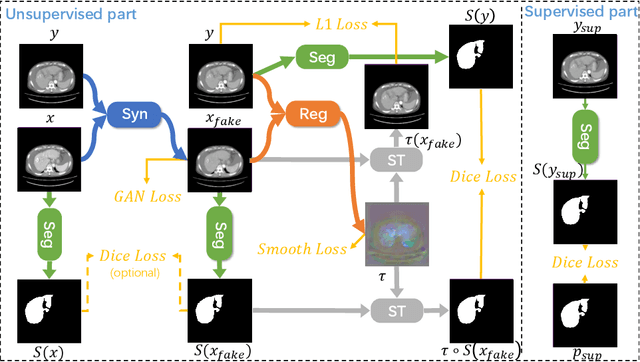
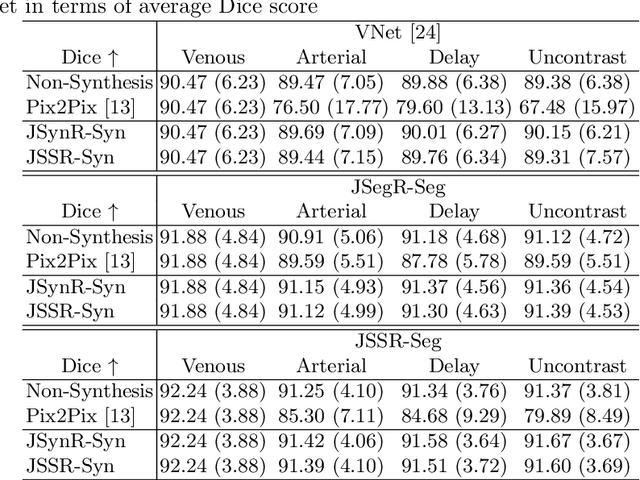
Multi-modal image registration is a challenging problem yet important clinical task in many real applications and scenarios. For medical imaging based diagnosis, deformable registration among different image modalities is often required in order to provide complementary visual information, as the first step. During the registration, the semantic information is the key to match homologous points and pixels. Nevertheless, many conventional registration methods are incapable to capture the high-level semantic anatomical dense correspondences. In this work, we propose a novel multi-task learning system, JSSR, based on an end-to-end 3D convolutional neural network that is composed of a generator, a register and a segmentor, for the tasks of synthesis, registration and segmentation, respectively. This system is optimized to satisfy the implicit constraints between different tasks unsupervisedly. It first synthesizes the source domain images into the target domain, then an intra-modal registration is applied on the synthesized images and target images. Then we can get the semantic segmentation by applying segmentors on the synthesized images and target images, which are aligned by the same deformation field generated by the registers. The supervision from another fully-annotated dataset is used to regularize the segmentors. We extensively evaluate our JSSR system on a large-scale medical image dataset containing 1,485 patient CT imaging studies of four different phases (i.e., 5,940 3D CT scans with pathological livers) on the registration, segmentation and synthesis tasks. The performance is improved after joint training on the registration and segmentation tasks by 0.9% and 1.9% respectively from a highly competitive and accurate baseline. The registration part also consistently outperforms the conventional state-of-the-art multi-modal registration methods.
Domain Adaptive Relational Reasoning for 3D Multi-Organ Segmentation
May 18, 2020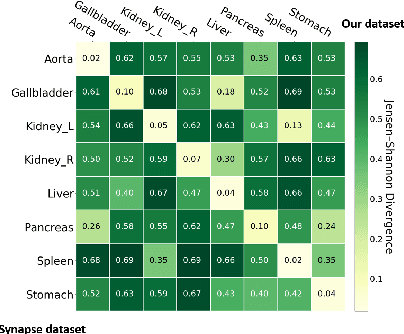
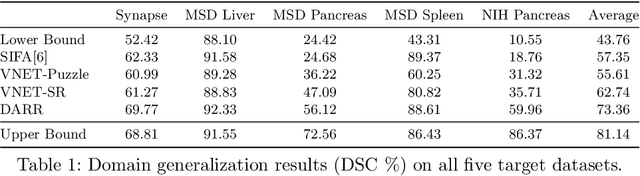
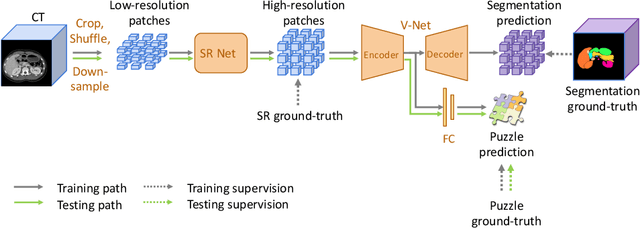
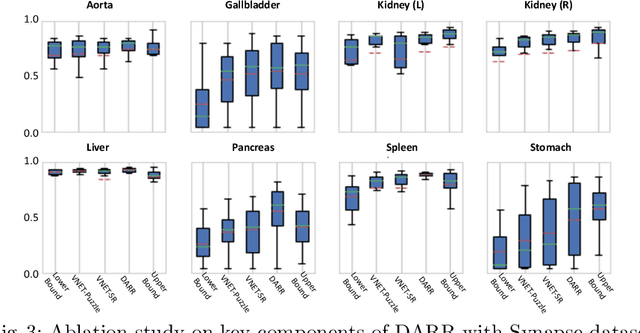
In this paper, we present a novel unsupervised domain adaptation (UDA) method, named Domain Adaptive Relational Reasoning (DARR), to generalize 3D multi-organ segmentation models to medical data collected from different scanners and/or protocols (domains). Our method is inspired by the fact that the spatial relationship between internal structures in medical images is relatively fixed, e.g., a spleen is always located at the tail of a pancreas, which serves as a latent variable to transfer the knowledge shared across multiple domains. We formulate the spatial relationship by solving a jigsaw puzzle task, i.e., recovering a CT scan from its shuffled patches, and jointly train it with the organ segmentation task. To guarantee the transferability of the learned spatial relationship to multiple domains, we additionally introduce two schemes: 1) Employing a super-resolution network also jointly trained with the segmentation model to standardize medical images from different domain to a certain spatial resolution; 2) Adapting the spatial relationship for a test image by test-time jigsaw puzzle training. Experimental results show that our method improves the performance by 29.60\% DSC on target datasets on average without using any data from the target domain during training.
Organ at Risk Segmentation for Head and Neck Cancer using Stratified Learning and Neural Architecture Search
Apr 17, 2020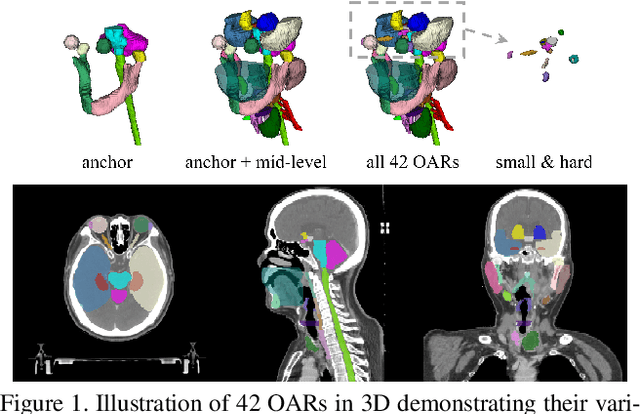

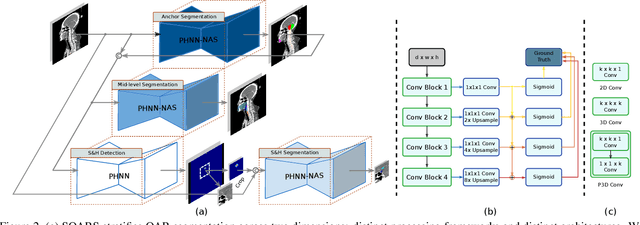
OAR segmentation is a critical step in radiotherapy of head and neck (H&N) cancer, where inconsistencies across radiation oncologists and prohibitive labor costs motivate automated approaches. However, leading methods using standard fully convolutional network workflows that are challenged when the number of OARs becomes large, e.g. > 40. For such scenarios, insights can be gained from the stratification approaches seen in manual clinical OAR delineation. This is the goal of our work, where we introduce stratified organ at risk segmentation (SOARS), an approach that stratifies OARs into anchor, mid-level, and small & hard (S&H) categories. SOARS stratifies across two dimensions. The first dimension is that distinct processing pipelines are used for each OAR category. In particular, inspired by clinical practices, anchor OARs are used to guide the mid-level and S&H categories. The second dimension is that distinct network architectures are used to manage the significant contrast, size, and anatomy variations between different OARs. We use differentiable neural architecture search (NAS), allowing the network to choose among 2D, 3D or Pseudo-3D convolutions. Extensive 4-fold cross-validation on 142 H&N cancer patients with 42 manually labeled OARs, the most comprehensive OAR dataset to date, demonstrates that both pipeline- and NAS-stratification significantly improves quantitative performance over the state-of-the-art (from 69.52% to 73.68% in absolute Dice scores). Thus, SOARS provides a powerful and principled means to manage the highly complex segmentation space of OARs.
PatchAttack: A Black-box Texture-based Attack with Reinforcement Learning
Apr 12, 2020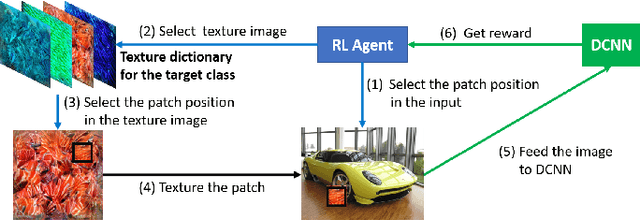
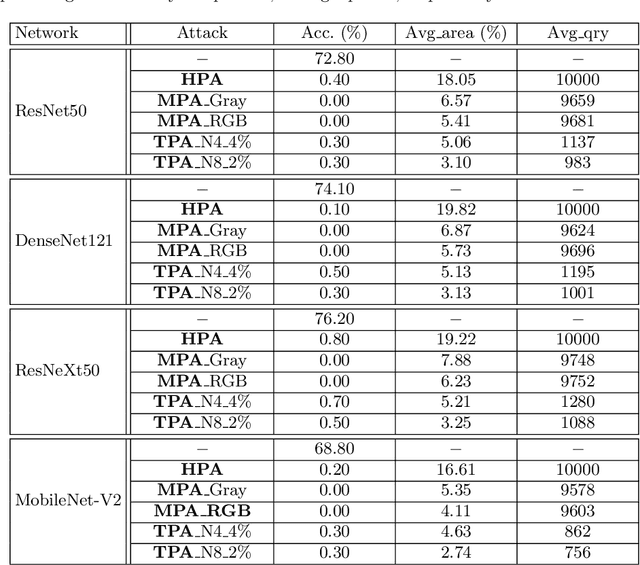

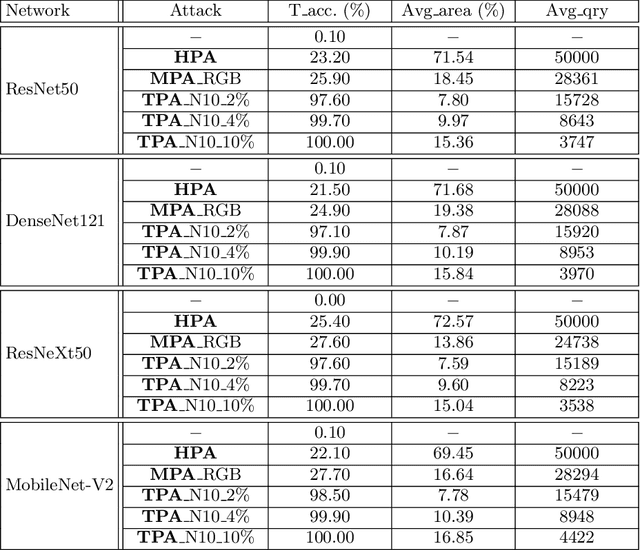
Patch-based attacks introduce a perceptible but localized change to the input that induces misclassification. A limitation of current patch-based black-box attacks is that they perform poorly for targeted attacks, and even for the less challenging non-targeted scenarios, they require a large number of queries. Our proposed PatchAttack is query efficient and can break models for both targeted and non-targeted attacks. PatchAttack induces misclassifications by superimposing small textured patches on the input image. We parametrize the appearance of these patches by a dictionary of class-specific textures. This texture dictionary is learned by clustering Gram matrices of feature activations from a VGG backbone. PatchAttack optimizes the position and texture parameters of each patch using reinforcement learning. Our experiments show that PatchAttack achieves > 99% success rate on ImageNet for a wide range of architectures, while only manipulating 3% of the image for non-targeted attacks and 10% on average for targeted attacks. Furthermore, we show that PatchAttack circumvents state-of-the-art adversarial defense methods successfully.
Context-Aware Group Captioning via Self-Attention and Contrastive Features
Apr 07, 2020
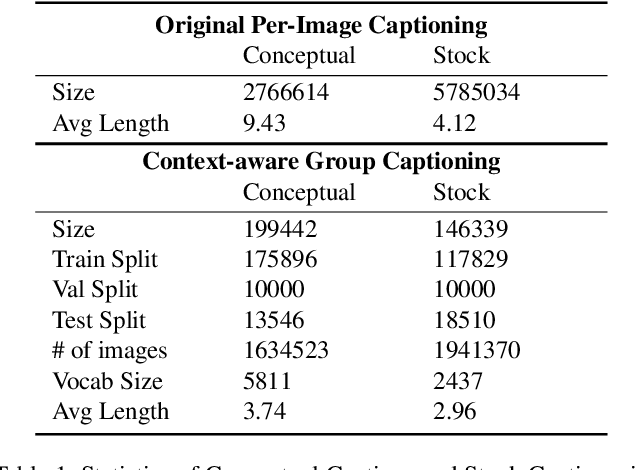
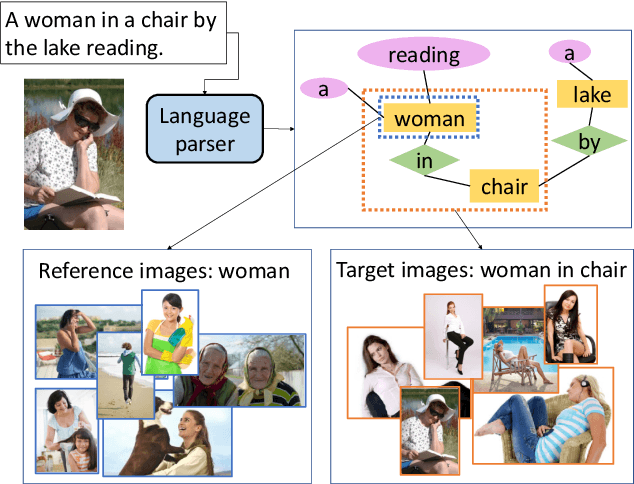
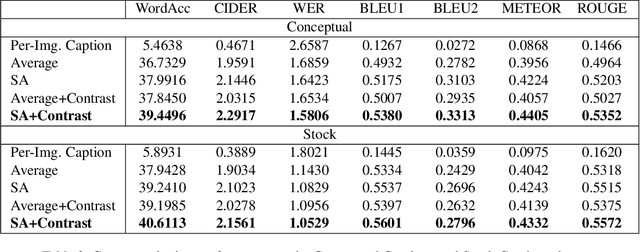
While image captioning has progressed rapidly, existing works focus mainly on describing single images. In this paper, we introduce a new task, context-aware group captioning, which aims to describe a group of target images in the context of another group of related reference images. Context-aware group captioning requires not only summarizing information from both the target and reference image group but also contrasting between them. To solve this problem, we propose a framework combining self-attention mechanism with contrastive feature construction to effectively summarize common information from each image group while capturing discriminative information between them. To build the dataset for this task, we propose to group the images and generate the group captions based on single image captions using scene graphs matching. Our datasets are constructed on top of the public Conceptual Captions dataset and our new Stock Captions dataset. Experiments on the two datasets show the effectiveness of our method on this new task. Related Datasets and code are released at https://lizw14.github.io/project/groupcap .