 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Navigation Skills for Legged Robots with Learned Robot Embeddings
Nov 24, 2020

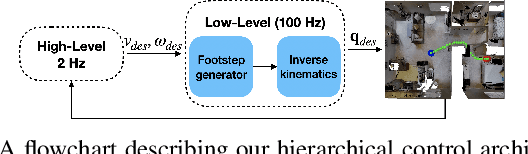
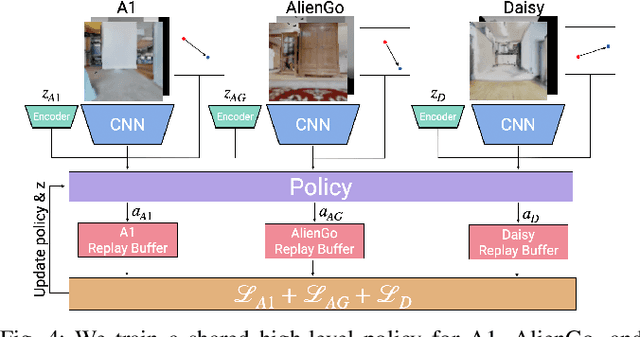
Navigation policies are commonly learned on idealized cylinder agents in simulation, without modelling complex dynamics, like contact dynamics, arising from the interaction between the robot and the environment. Such policies perform poorly when deployed on complex and dynamic robots, such as legged robots. In this work, we learn hierarchical navigation policies that account for the low-level dynamics of legged robots, such as maximum speed, slipping, and achieve good performance at navigating cluttered indoor environments. Once such a policy is learned on one legged robot, it does not directly generalize to a different robot due to dynamical differences, which increases the cost of learning such a policy on new robots. To overcome this challenge, we learn dynamics-aware navigation policies across multiple robots with robot-specific embeddings, which enable generalization to new unseen robots. We train our policies across three legged robots - 2 quadrupeds (A1, AlienGo) and a hexapod (Daisy). At test time, we study the performance of our learned policy on two new legged robots (Laikago, 4-legged Daisy) and show that our learned policy can sample-efficiently generalize to previously unseen robots.
Leveraging Forward Model Prediction Error for Learning Control
Nov 07, 2020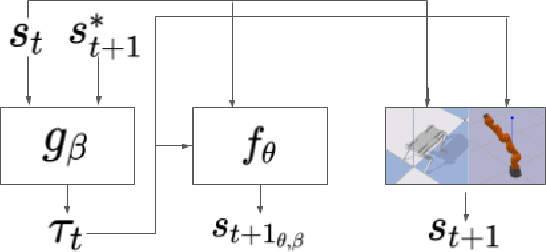
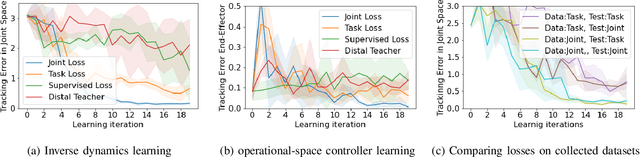
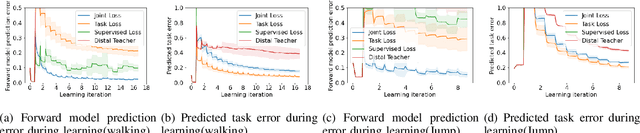

Learning for model based control can be sample-efficient and generalize well, however successfully learning models and controllers that represent the problem at hand can be challenging for complex tasks. Using inaccurate models for learning can lead to sub-optimal solutions, that are unlikely to perform well in practice. In this work, we present a learning approach which iterates between model learning and data collection and leverages forward model prediction error for learning control. We show how using the controller's prediction as input to a forward model can create a differentiable connection between the controller and the model, allowing us to formulate a loss in the state space. This lets us include forward model prediction error during controller learning and we show that this creates a loss objective that significantly improves learning on different motor control tasks. We provide empirical and theoretical results that show the benefits of our method and present evaluations in simulation for learning control on a 7 DoF manipulator and an underactuated 12 DoF quadruped. We show that our approach successfully learns controllers for challenging motor control tasks involving contact switching.
Model-Based Inverse Reinforcement Learning from Visual Demonstrations
Oct 18, 2020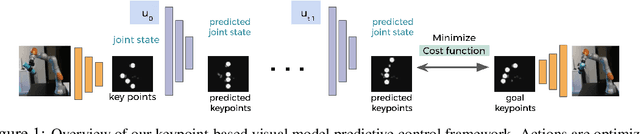
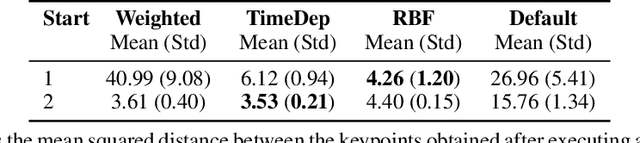
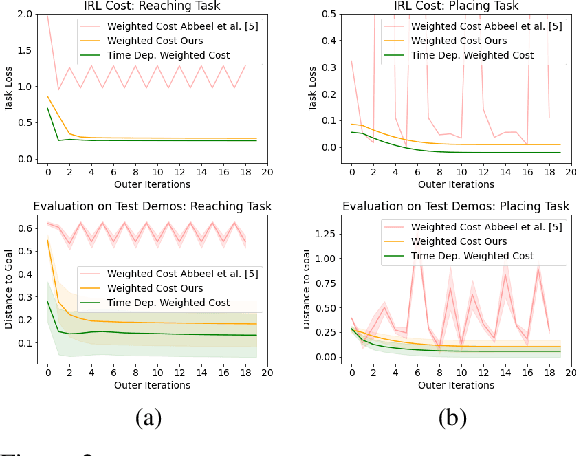

Scaling model-based inverse reinforcement learning (IRL) to real robotic manipulation tasks with unknown dynamics remains an open problem. The key challenges lie in learning good dynamics models, developing algorithms that scale to high-dimensional state-spaces and being able to learn from both visual and proprioceptive demonstrations. In this work, we present a gradient-based inverse reinforcement learning framework that utilizes a pre-trained visual dynamics model to learn cost functions when given only visual human demonstrations. The learned cost functions are then used to reproduce the demonstrated behavior via visual model predictive control. We evaluate our framework on hardware on two basic object manipulation tasks.
Planning in Learned Latent Action Spaces for Generalizable Legged Locomotion
Sep 18, 2020
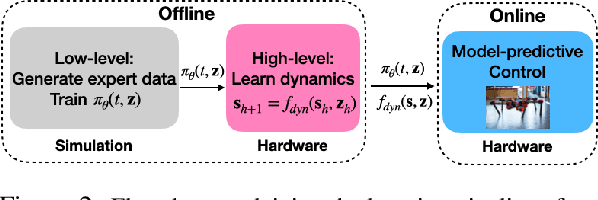
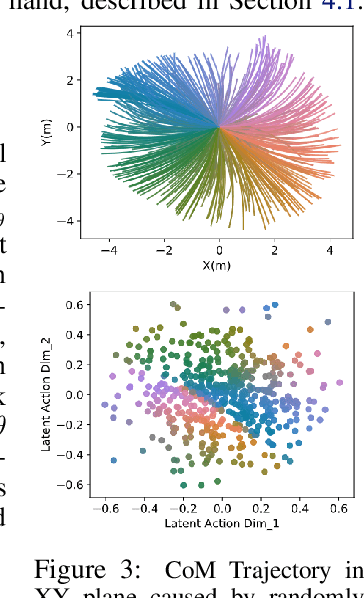

Hierarchical learning has been successful at learning generalizable locomotion skills on walking robots in a sample-efficient manner. However, the low-dimensional "latent" action used to communicate between different layers of the hierarchy is typically user-designed. In this work, we present a fully-learned hierarchical framework, that is capable of jointly learning the low-level controller and the high-level action space. Next, we plan over latent actions in a model-predictive control fashion, using a learned high-level dynamics model. This framework is generalizable to multiple robots, and we present results on a Daisy hexapod simulation, A1 quadruped simulation, and Daisy robot hardware. We compare a range of learned hierarchical approaches, and show that our framework is more reliable, versatile and sample-efficient. In addition to learning approaches, we also compare to an inverse-kinematics (IK) based footstep planner, and show that our fully-learned framework is competitive in performance with IK under normal conditions, and outperforms it in adverse settings. Our hardware experiments show the Daisy hexapod achieving multiple locomotion tasks, such as goal reaching, trajectory and velocity tracking in an unstructured outdoor setting, with only 2000 hardware samples.
Learning State-Dependent Losses for Inverse Dynamics Learning
Mar 12, 2020
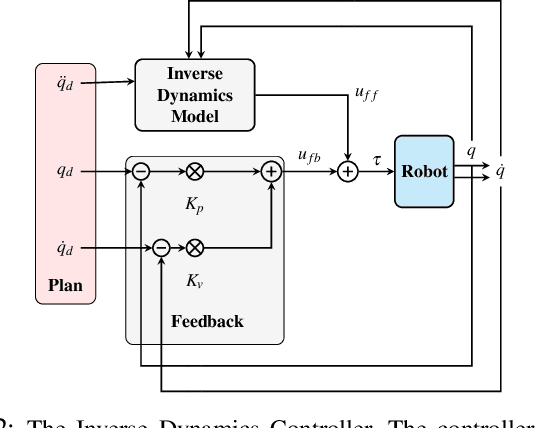

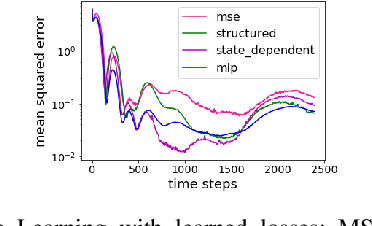
Being able to quickly adapt to changes in dynamics is paramount in model-based control for object manipulation tasks. In order to influence fast adaptation of the inverse dynamics model's parameters, data efficiency is crucial. Given observed data, a key element to how an optimizer updates model parameters is the loss function. In this work, we propose to apply meta-learning to learn structured, state-dependent loss functions during a meta-training phase. We then replace standard losses with our learned losses during online adaptation tasks. We evaluate our proposed approach on inverse dynamics learning tasks, both in simulation and on real hardware data. In both settings, the structured learned losses improve online adaptation speed, when compared to standard, state-independent loss functions.
Encoding Physical Constraints in Differentiable Newton-Euler Algorithm
Feb 19, 2020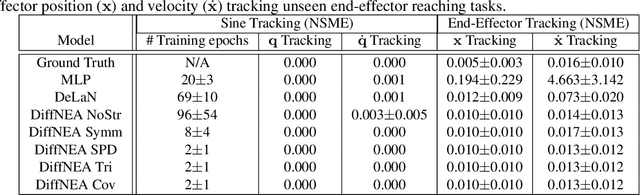
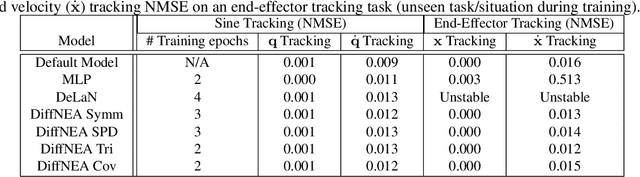
The recursive Newton-Euler Algorithm (RNEA) is a popular technique in robotics for computing the dynamics of robots. The computed dynamics can then be used for torque control with inverse dynamics, or for forward dynamics computations. RNEA can be framed as a differentiable computational graph, enabling the dynamics parameters of the robot to be learned from data via modern auto-differentiation toolboxes. However, the dynamics parameters learned in this manner can be physically implausible. In this work, we incorporate physical constraints in the learning by adding structure to the learned parameters. This results in a framework that can learn physically plausible dynamics via gradient descent, improving the training speed as well as generalization of the learned dynamics models. We evaluate our method on real-time inverse dynamics predictions of a 7 degree of freedom robot arm, both in simulation and on the real robot. Our experiments study a spectrum of structure added to learned dynamics, and compare their performance and generalization.
Re-Examining Linear Embeddings for High-Dimensional Bayesian Optimization
Jan 31, 2020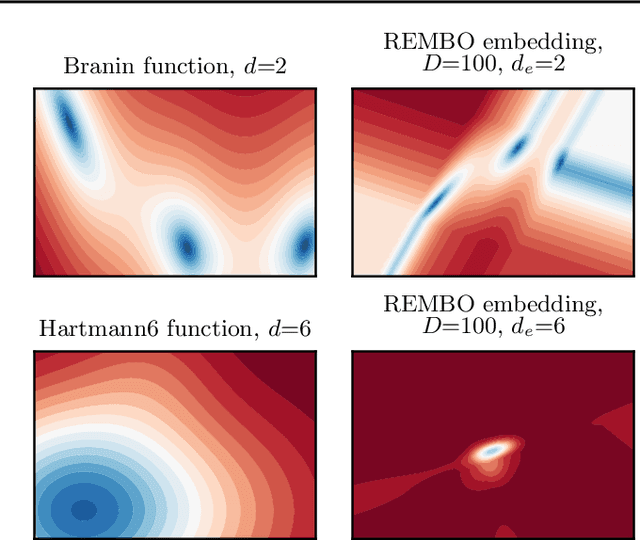
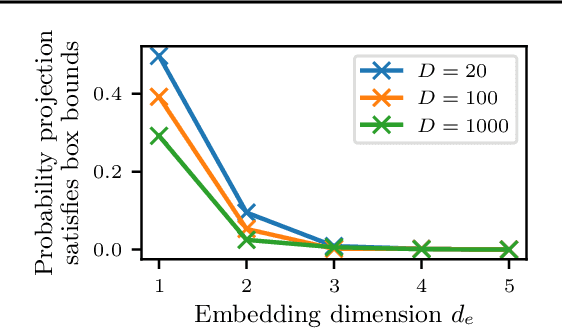
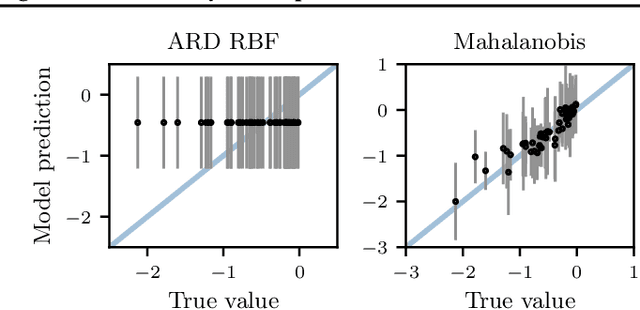
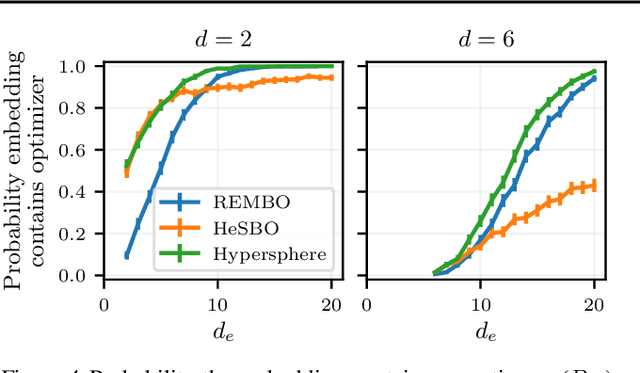
Bayesian optimization (BO) is a popular approach to optimize expensive-to-evaluate black-box functions. A significant challenge in BO is to scale to high-dimensional parameter spaces while retaining sample efficiency. A solution considered in existing literature is to embed the high-dimensional space in a lower-dimensional manifold, often via a random linear embedding. In this paper, we identify several crucial issues and misconceptions about the use of linear embeddings for BO. We study the properties of linear embeddings from the literature and show that some of the design choices in current approaches adversely impact their performance. We show empirically that properly addressing these issues significantly improves the efficacy of linear embeddings for BO on a range of problems, including learning a gait policy for robot locomotion.
Learning Generalizable Locomotion Skills with Hierarchical Reinforcement Learning
Sep 26, 2019
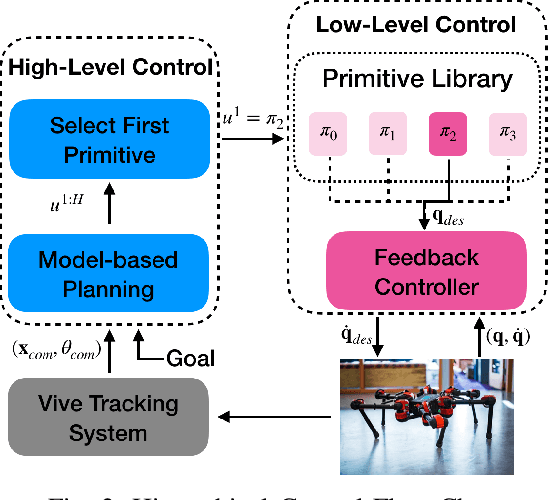
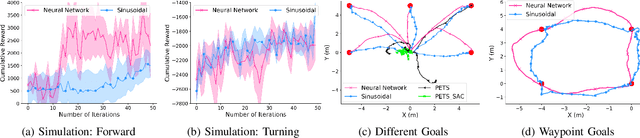
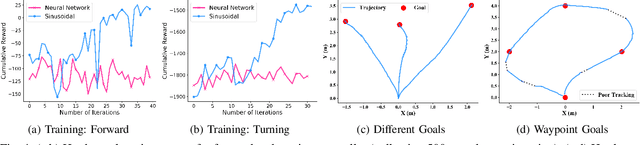
Learning to locomote to arbitrary goals on hardware remains a challenging problem for reinforcement learning. In this paper, we present a hierarchical learning framework that improves sample-efficiency and generalizability of locomotion skills on real-world robots. Our approach divides the problem of goal-oriented locomotion into two sub-problems: learning diverse primitives skills, and using model-based planning to sequence these skills. We parametrize our primitives as cyclic movements, improving sample-efficiency of learning on a 18 degrees of freedom robot. Then, we learn coarse dynamics models over primitive cycles and use them in a model predictive control framework. This allows us to learn to walk to arbitrary goals up to 12m away, after about two hours of training from scratch on hardware. Our results on a Daisy hexapod hardware and simulation demonstrate the efficacy of our approach at reaching distant targets, in different environments and with sensory noise.
Bayesian Optimization in Variational Latent Spaces with Dynamic Compression
Jul 10, 2019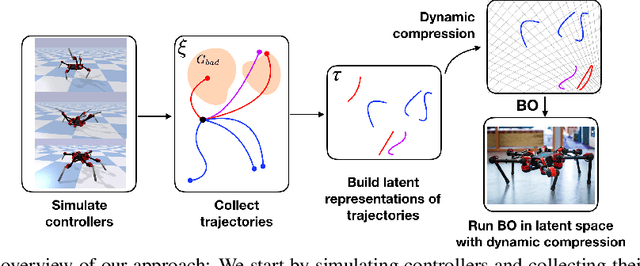

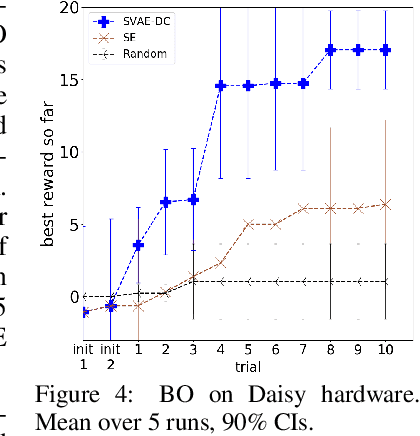
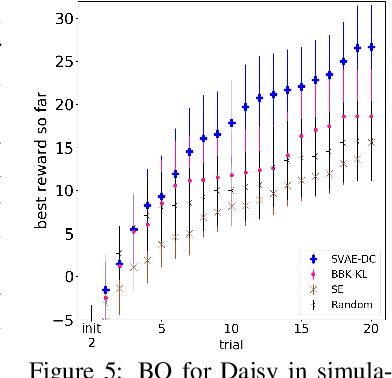
Data-efficiency is crucial for autonomous robots to adapt to new tasks and environments. In this work we focus on robotics problems with a budget of only 10-20 trials. This is a very challenging setting even for data-efficient approaches like Bayesian optimization (BO), especially when optimizing higher-dimensional controllers. Simulated trajectories can be used to construct informed kernels for BO. However, previous work employed supervised ways of extracting low-dimensional features for these. We propose a model and architecture for a sequential variational autoencoder that embeds the space of simulated trajectories into a lower-dimensional space of latent paths in an unsupervised way. We further compress the search space for BO by reducing exploration in parts of the state space that are undesirable, without requiring explicit constraints on controller parameters. We validate our approach with hardware experiments on a Daisy hexapod robot and an ABB Yumi manipulator. We also present simulation experiments with further comparisons to several baselines on Daisy and two manipulators. Our experiments indicate the proposed trajectory-based kernel with dynamic compression can offer ultra data-efficient optimization.
Curious iLQR: Resolving Uncertainty in Model-based RL
Apr 15, 2019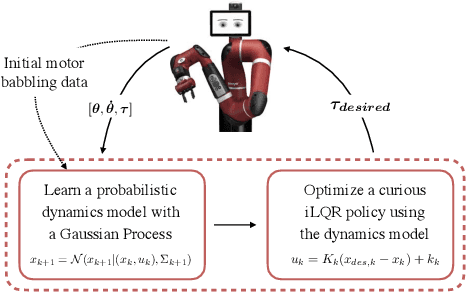
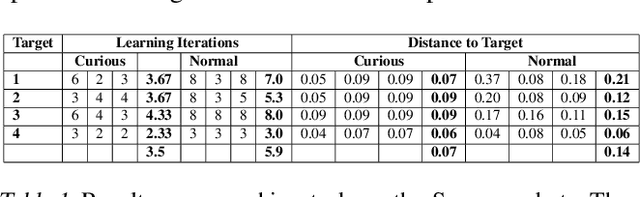
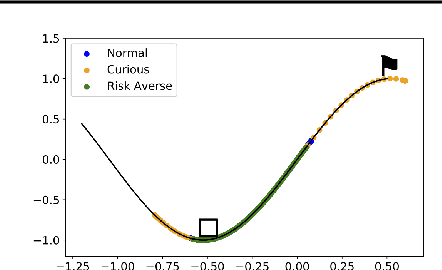
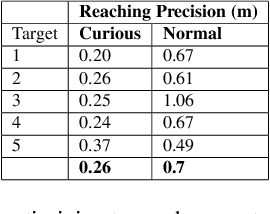
Curiosity as a means to explore during reinforcement learning problems has recently become very popular. However, very little progress has been made in utilizing curiosity for learning control. In this work, we propose a model-based reinforcement learning (MBRL) framework that combines Bayesian modeling of the system dynamics with curious iLQR, a risk-seeking iterative LQR approach. During trajectory optimization the curious iLQR attempts to minimize both the task-dependent cost and the uncertainty in the dynamics model. We scale this approach to perform reaching tasks on 7-DoF manipulators, to perform both simulation and real robot reaching experiments. Our experiments consistently show that MBRL with curious iLQR more easily overcomes bad initial dynamics models and reaches desired joint configurations more reliably and with less system rollouts.