 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIA 2022 Shared Task: Evaluating Cross-lingual Open-Retrieval Question Answering for 16 Diverse Languages
Jul 02, 2022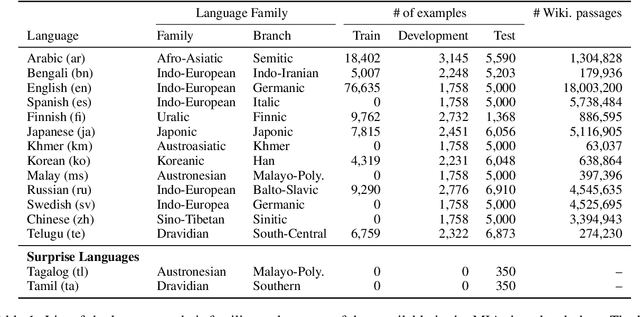
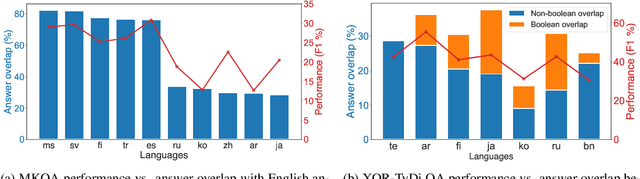
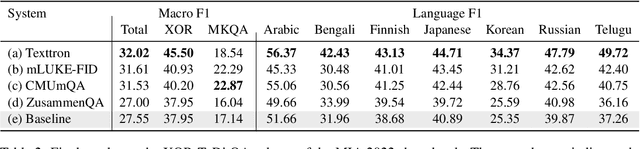
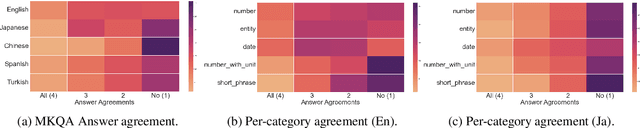
We present the results of the Workshop on Multilingual Information Access (MIA) 2022 Shared Task, evaluating cross-lingual open-retrieval question answering (QA) systems in 16 typologically diverse languages. In this task, we adapted two large-scale cross-lingual open-retrieval QA datasets in 14 typologically diverse languages, and newly annotated open-retrieval QA data in 2 underrepresented languages: Tagalog and Tamil. Four teams submitted their systems. The best system leveraging iteratively mined diverse negative examples and larger pretrained models achieves 32.2 F1, outperforming our baseline by 4.5 points. The second best system uses entity-aware contextualized representations for document retrieval, and achieves significant improvements in Tamil (20.8 F1), whereas most of the other systems yield nearly zero scores.
Attentional Mixtures of Soft Prompt Tuning for Parameter-efficient Multi-task Knowledge Sharing
May 24, 2022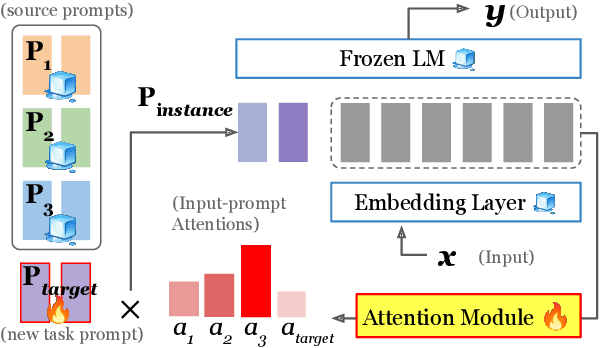

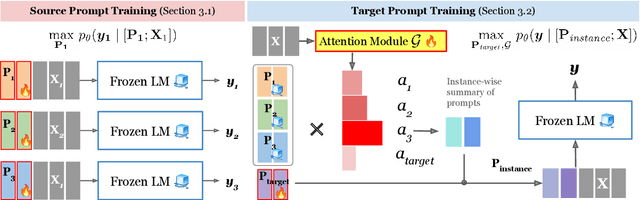
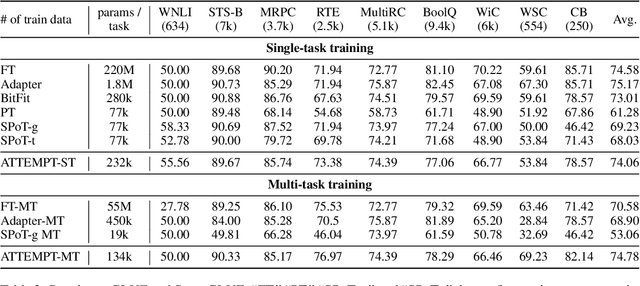
This work introduces ATTEMPT (Attentional Mixture of Prompt Tuning), a new modular, multi-task, and parameter-efficient language model (LM) tuning approach that combines knowledge transferred across different tasks via a mixture of soft prompts while keeping original LM unchanged. ATTEMPT interpolates a set of prompts trained on large-scale source tasks and a newly initialized target task prompt using instance-wise attention computed by a lightweight sub-network trained on multiple target tasks. ATTEMPT is parameter-efficient (e.g., updates 1,600 times fewer parameters than fine-tuning) and enables multi-task learning and flexible extensions; importantly, it is also more interpretable because it demonstrates which source tasks affect the final model decision on target tasks. Experimental results across 17 diverse datasets show that ATTEMPT improves prompt tuning by up to a 22% absolute performance gain and outperforms or matches fully fine-tuned or other parameter-efficient tuning approaches that use over ten times more parameters.
Evidentiality-guided Generation for Knowledge-Intensive NLP Tasks
Dec 16, 2021
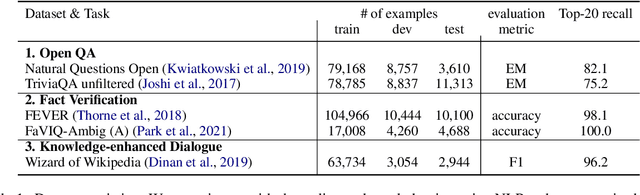
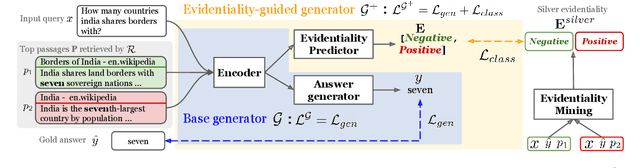
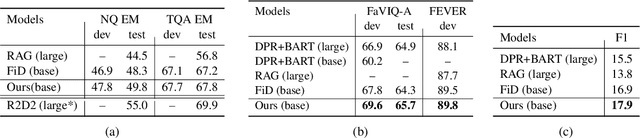
Retrieval-augmented generation models have shown state-of-the-art performance across many knowledge-intensive NLP tasks such as open question answering and fact verification. These models are trained to generate the final output given the retrieved passages, which can be irrelevant to the original query, leading to learning spurious cues or answer memorization. This work introduces a method to incorporate evidentiality of passages -- whether a passage contains correct evidence to support the output -- into training the generator. We introduce a multi-task learning framework to jointly generate the final output and predict the evidentiality of each passage, leveraging a new task-agnostic method to obtain {\it silver} evidentiality labels for supervision. Our experiments on five datasets across three knowledge-intensive tasks show that our new evidentiality-guided generator significantly outperforms its direct counterpart with the same-size model and advances the state of the art on FaVIQ-Ambig. We attribute these improvements to both the auxiliary multi-task learning and silver evidentiality mining techniques.
One Question Answering Model for Many Languages with Cross-lingual Dense Passage Retrieval
Jul 26, 2021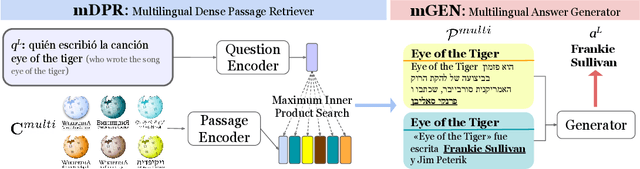
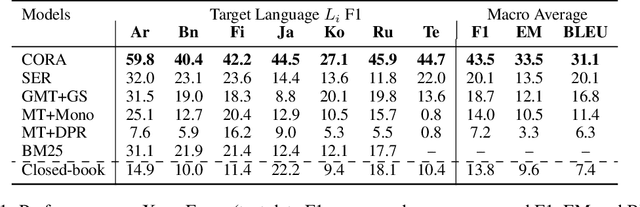
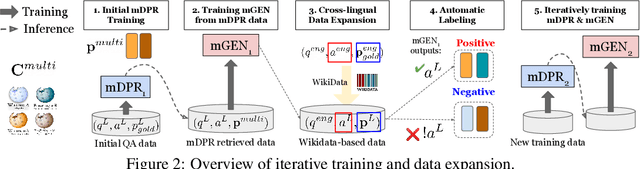
We present CORA, a Cross-lingual Open-Retrieval Answer Generation model that can answer questions across many languages even when language-specific annotated data or knowledge sources are unavailable. We introduce a new dense passage retrieval algorithm that is trained to retrieve documents across languages for a question. Combined with a multilingual autoregressive generation model, CORA answers directly in the target language without any translation or in-language retrieval modules as used in prior work. We propose an iterative training method that automatically extends annotated data available only in high-resource languages to low-resource ones. Our results show that CORA substantially outperforms the previous state of the art on multilingual open question answering benchmarks across 26 languages, 9 of which are unseen during training. Our analyses show the significance of cross-lingual retrieval and generation in many languages, particularly under low-resource settings.
Efficient Passage Retrieval with Hashing for Open-domain Question Answering
Jun 02, 2021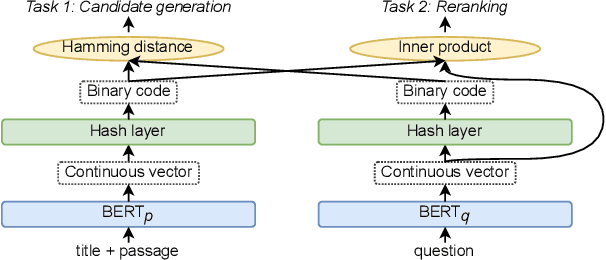
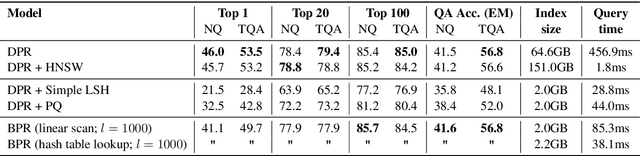
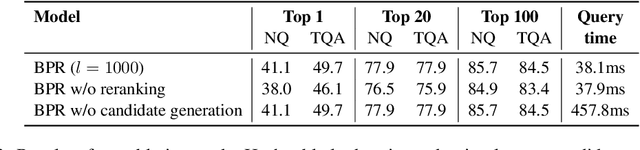

Most state-of-the-art open-domain question answering systems use a neural retrieval model to encode passages into continuous vectors and extract them from a knowledge source. However, such retrieval models often require large memory to run because of the massive size of their passage index. In this paper, we introduce Binary Passage Retriever (BPR), a memory-efficient neural retrieval model that integrates a learning-to-hash technique into the state-of-the-art Dense Passage Retriever (DPR) to represent the passage index using compact binary codes rather than continuous vectors. BPR is trained with a multi-task objective over two tasks: efficient candidate generation based on binary codes and accurate reranking based on continuous vectors. Compared with DPR, BPR substantially reduces the memory cost from 65GB to 2GB without a loss of accuracy on two standard open-domain question answering benchmarks: Natural Questions and TriviaQA. Our code and trained models are available at https://github.com/studio-ousia/bpr.
MultiModalQA: Complex Question Answering over Text, Tables and Images
Apr 13, 2021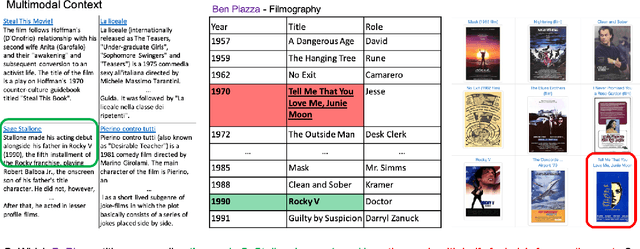
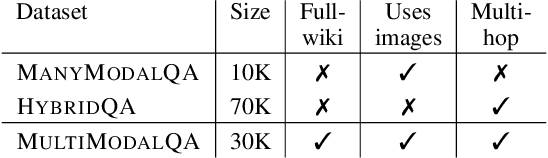

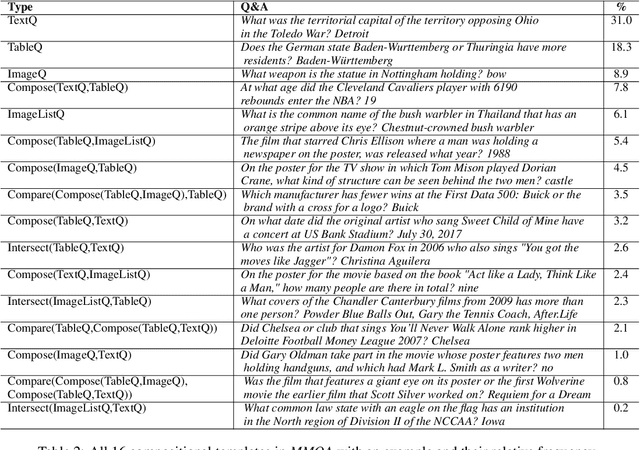
When answering complex questions, people can seamlessly combine information from visual, textual and tabular sources. While interest in models that reason over multiple pieces of evidence has surged in recent years, there has been relatively little work on question answering models that reason across multiple modalities. In this paper, we present MultiModalQA(MMQA): a challenging question answering dataset that requires joint reasoning over text, tables and images. We create MMQA using a new framework for generating complex multi-modal questions at scale, harvesting tables from Wikipedia, and attaching images and text paragraphs using entities that appear in each table. We then define a formal language that allows us to take questions that can be answered from a single modality, and combine them to generate cross-modal questions. Last, crowdsourcing workers take these automatically-generated questions and rephrase them into more fluent language. We create 29,918 questions through this procedure, and empirically demonstrate the necessity of a multi-modal multi-hop approach to solve our task: our multi-hop model, ImplicitDecomp, achieves an average F1of 51.7 over cross-modal questions, substantially outperforming a strong baseline that achieves 38.2 F1, but still lags significantly behind human performance, which is at 90.1 F1
The Aleatoric Uncertainty Estimation Using a Separate Formulation with Virtual Residuals
Nov 03, 2020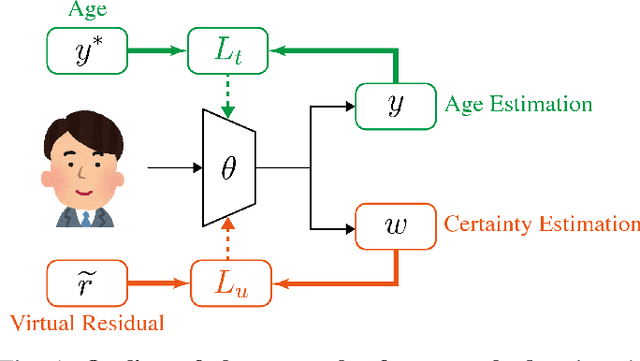
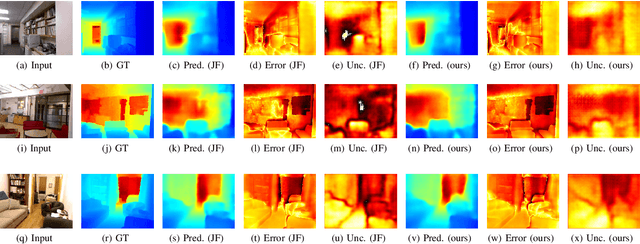
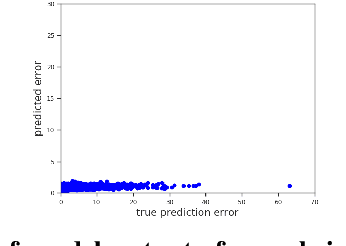
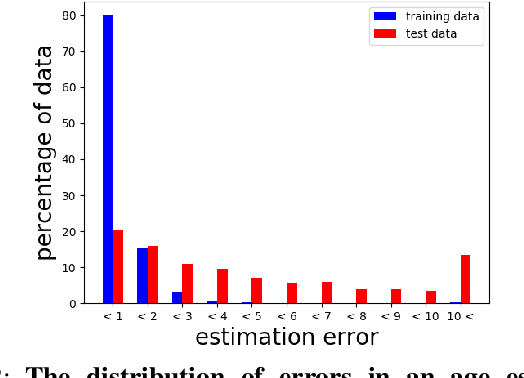
We propose a new optimization framework for aleatoric uncertainty estimation in regression problems. Existing methods can quantify the error in the target estimation, but they tend to underestimate it. To obtain the predictive uncertainty inherent in an observation, we propose a new separable formulation for the estimation of a signal and of its uncertainty, avoiding the effect of overfitting. By decoupling target estimation and uncertainty estimation, we also control the balance between signal estimation and uncertainty estimation. We conduct three types of experiments: regression with simulation data, age estimation, and depth estimation. We demonstrate that the proposed method outperforms a state-of-the-art technique for signal and uncertainty estimation.
XOR QA: Cross-lingual Open-Retrieval Question Answering
Oct 24, 2020
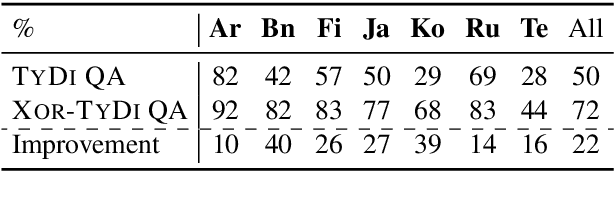
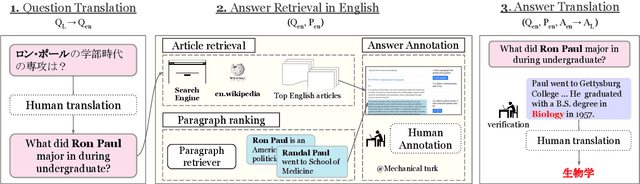
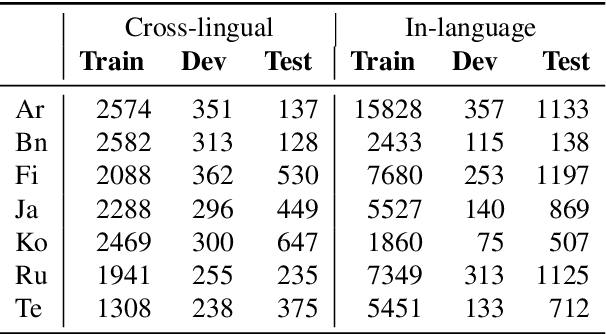
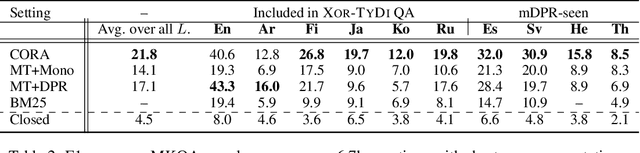
Multilingual question answering tasks typically assume answers exist in the same language as the question. Yet in practice, many languages face both information scarcity---where languages have few reference articles---and information asymmetry---where questions reference concepts from other cultures. This work extends open-retrieval question answering to a cross-lingual setting enabling questions from one language to be answered via answer content from another language. We construct a large-scale dataset built on questions from TyDi QA lacking same-language answers. Our task formulation, called Cross-lingual Open Retrieval Question Answering (XOR QA), includes 40k information-seeking questions from across 7 diverse non-English languages. Based on this dataset, we introduce three new tasks that involve cross-lingual document retrieval using multi-lingual and English resources. We establish baselines with state-of-the-art machine translation systems and cross-lingual pretrained models. Experimental results suggest that XOR QA is a challenging task that will facilitate the development of novel techniques for multilingual question answering. Our data and code are available at https://nlp.cs.washington.edu/xorqa.
Challenges in Information Seeking QA:Unanswerable Questions and Paragraph Retrieval
Oct 22, 2020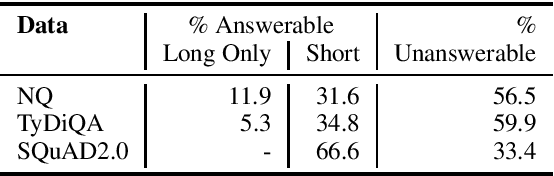
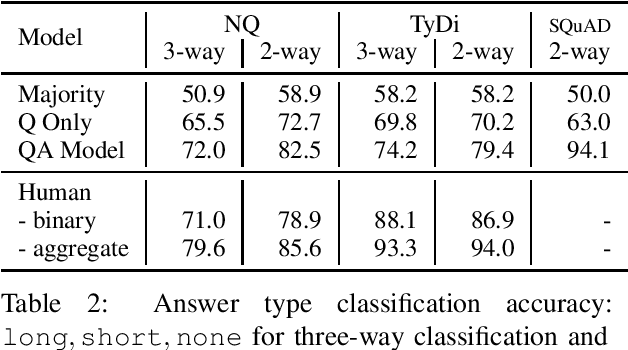
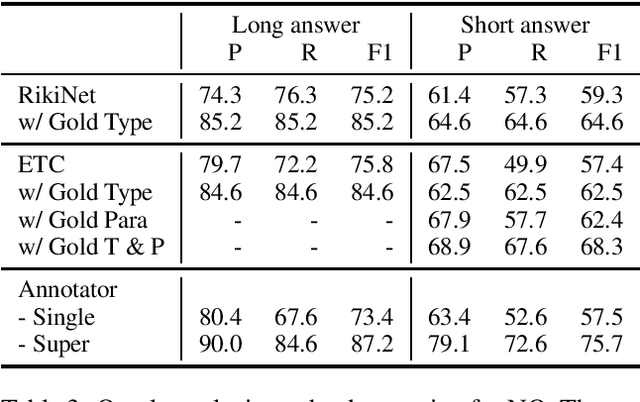
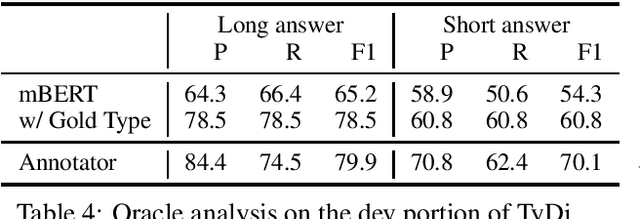
Recent progress in pretrained language model "solved" many reading comprehension benchmark datasets. Yet information-seeking Question Answering (QA) datasets, where questions are written without the evidence document, remain unsolved. We analyze two such datasets (Natural Questions and TyDi QA) to identify remaining headrooms: paragraph selection and answerability classification, i.e. determining whether the paired evidence document contains the answer to the query or not. In other words, given a gold paragraph and knowing whether it contains an answer or not, models easily outperform a single annotator in both datasets. After identifying unanswerability as a bottleneck, we further inspect what makes questions unanswerable. Our study points to avenues for future research, both for dataset creation and model development.
LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
Oct 02, 2020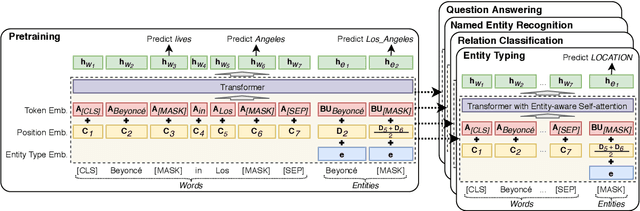
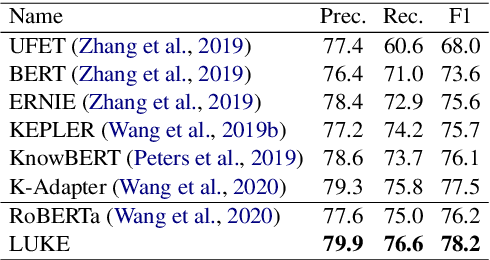
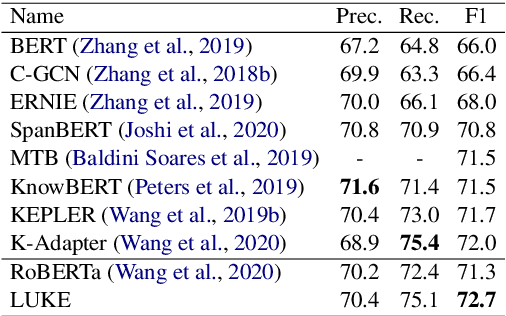
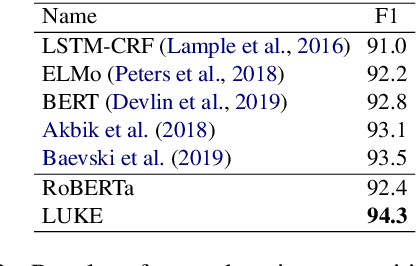
Entity representations are useful in natural language tasks involving entities. In this paper, we propose new pretrained contextualized representations of words and entities based on the bidirectional transformer. The proposed model treats words and entities in a given text as independent tokens, and outputs contextualized representations of them. Our model is trained using a new pretraining task based on the masked language model of BERT. The task involves predicting randomly masked words and entities in a large entity-annotated corpus retrieved from Wikipedia. We also propose an entity-aware self-attention mechanism that is an extension of the self-attention mechanism of the transformer, and considers the types of tokens (words or entities) when computing attention scores. The proposed model achieves impressive empirical performance on a wide range of entity-related tasks. In particular, it obtains state-of-the-art results on five well-known datasets: Open Entity (entity typing), TACRED (relation classification), CoNLL-2003 (named entity recognition), ReCoRD (cloze-style question answering), and SQuAD 1.1 (extractive question answering). Our source code and pretrained representations are available at https://github.com/studio-ousia/luke.