 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Introduction to Electrocatalyst Design using Machine Learning for Renewable Energy Storage
Oct 14, 2020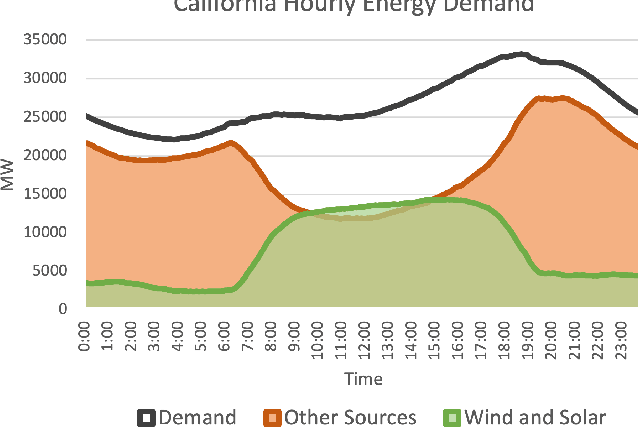
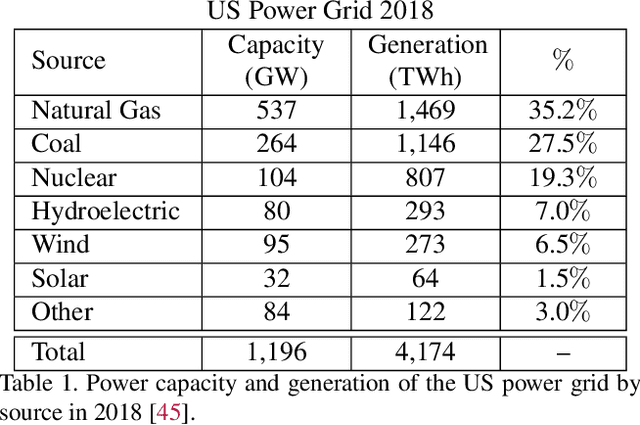
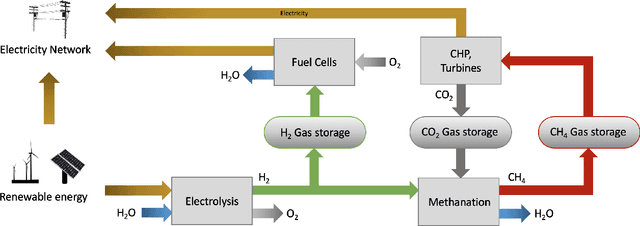
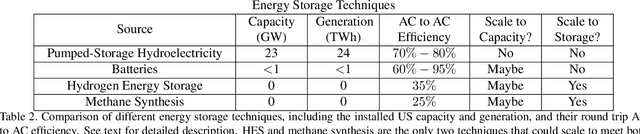
Scalable and cost-effective solutions to renewable energy storage are essential to addressing the world's rising energy needs while reducing climate change. As we increase our reliance on renewable energy sources such as wind and solar, which produce intermittent power, storage is needed to transfer power from times of peak generation to peak demand. This may require the storage of power for hours, days, or months. One solution that offers the potential of scaling to nation-sized grids is the conversion of renewable energy to other fuels, such as hydrogen or methane. To be widely adopted, this process requires cost-effective solutions to running electrochemical reactions. An open challenge is finding low-cost electrocatalysts to drive these reactions at high rates. Through the use of quantum mechanical simulations (density functional theory), new catalyst structures can be tested and evaluated. Unfortunately, the high computational cost of these simulations limits the number of structures that may be tested. The use of machine learning may provide a method to efficiently approximate these calculations, leading to new approaches in finding effective electrocatalysts. In this paper, we provide an introduction to the challenges in finding suitable electrocatalysts, how machine learning may be applied to the problem, and the use of the Open Catalyst Project OC20 dataset for model training.
Auxiliary Tasks Speed Up Learning PointGoal Navigation
Jul 09, 2020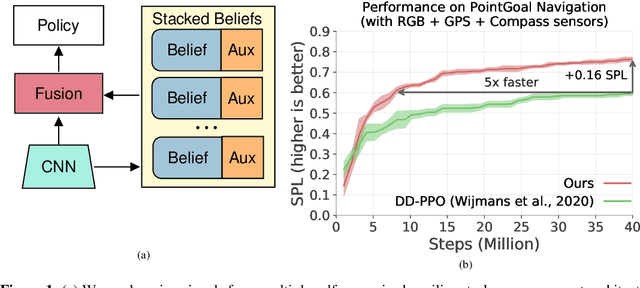

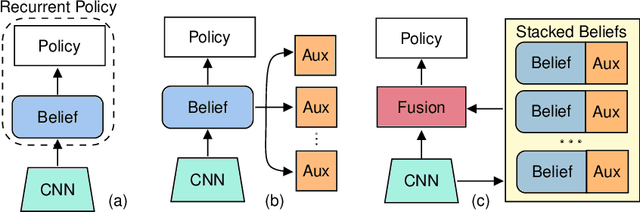
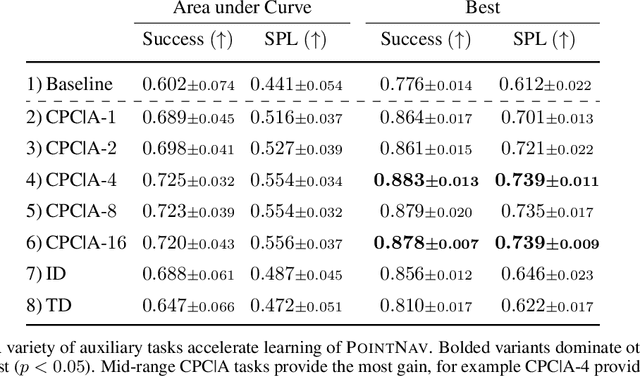
PointGoal Navigation is an embodied task that requires agents to navigate to a specified point in an unseen environment. Wijmans et al. showed that this task is solvable but their method is computationally prohibitive, requiring 2.5 billion frames and 180 GPU-days. In this work, we develop a method to significantly increase sample and time efficiency in learning PointNav using self-supervised auxiliary tasks (e.g. predicting the action taken between two egocentric observations, predicting the distance between two observations from a trajectory,etc.).We find that naively combining multiple auxiliary tasks improves sample efficiency,but only provides marginal gains beyond a point. To overcome this, we use attention to combine representations learnt from individual auxiliary tasks. Our best agent is 5x faster to reach the performance of the previous state-of-the-art, DD-PPO, at 40M frames, and improves on DD-PPO's performance at40M frames by 0.16 SPL. Our code is publicly available at https://github.com/joel99/habitat-pointnav-aux.
Feel The Music: Automatically Generating A Dance For An Input Song
Jun 23, 2020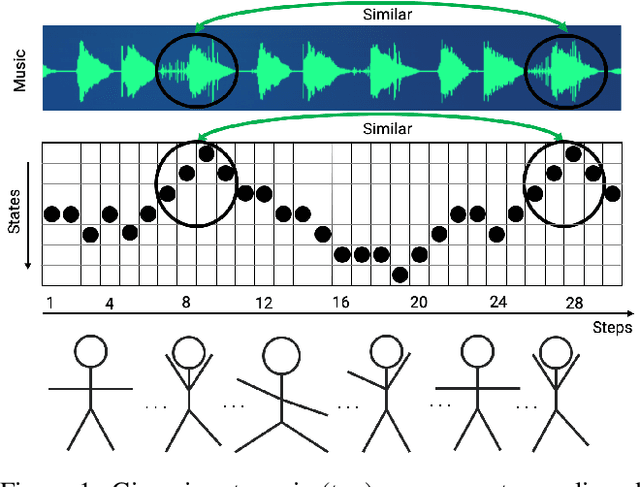
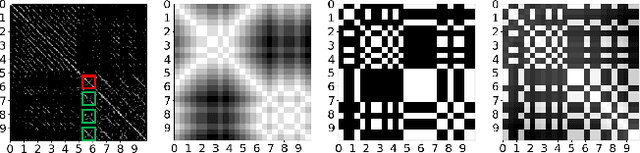
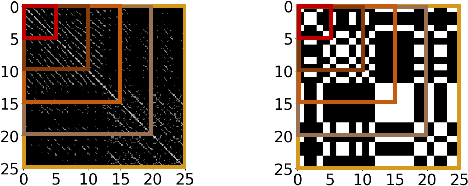
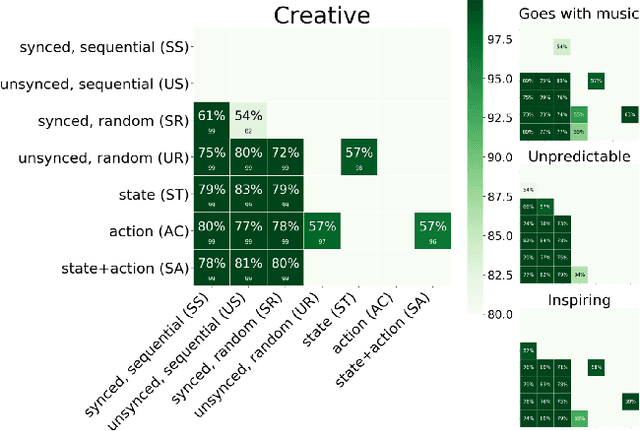
We present a general computational approach that enables a machine to generate a dance for any input music. We encode intuitive, flexible heuristics for what a 'good' dance is: the structure of the dance should align with the structure of the music. This flexibility allows the agent to discover creative dances. Human studies show that participants find our dances to be more creative and inspiring compared to meaningful baselines. We also evaluate how perception of creativity changes based on different presentations of the dance. Our code is available at https://github.com/purvaten/feel-the-music.
Probing Emergent Semantics in Predictive Agents via Question Answering
Jun 01, 2020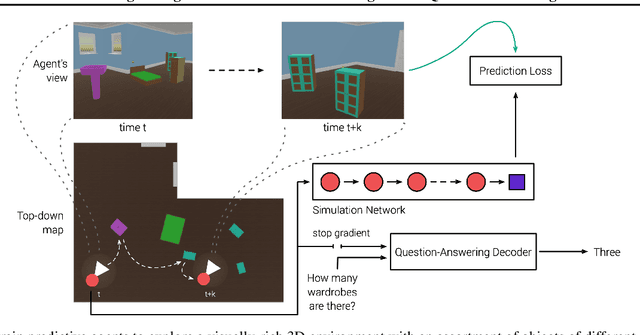

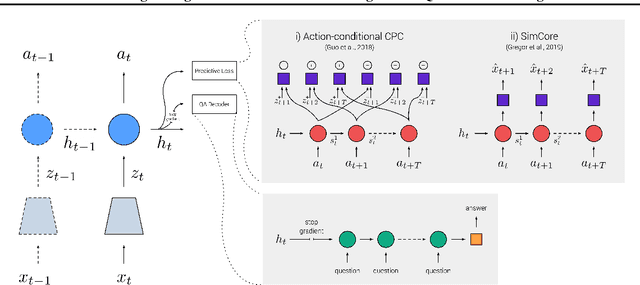
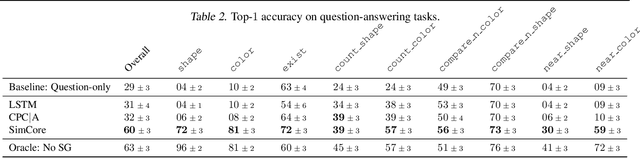
Recent work has shown how predictive modeling can endow agents with rich knowledge of their surroundings, improving their ability to act in complex environments. We propose question-answering as a general paradigm to decode and understand the representations that such agents develop, applying our method to two recent approaches to predictive modeling -action-conditional CPC (Guo et al., 2018) and SimCore (Gregor et al., 2019). After training agents with these predictive objectives in a visually-rich, 3D environment with an assortment of objects, colors, shapes, and spatial configurations, we probe their internal state representations with synthetic (English) questions, without backpropagating gradients from the question-answering decoder into the agent. The performance of different agents when probed this way reveals that they learn to encode factual, and seemingly compositional, information about objects, properties and spatial relations from their physical environment. Our approach is intuitive, i.e. humans can easily interpret responses of the model as opposed to inspecting continuous vectors, and model-agnostic, i.e. applicable to any modeling approach. By revealing the implicit knowledge of objects, quantities, properties and relations acquired by agents as they learn, question-conditional agent probing can stimulate the design and development of stronger predictive learning objectives.
Large-scale Pretraining for Visual Dialog: A Simple State-of-the-Art Baseline
Dec 05, 2019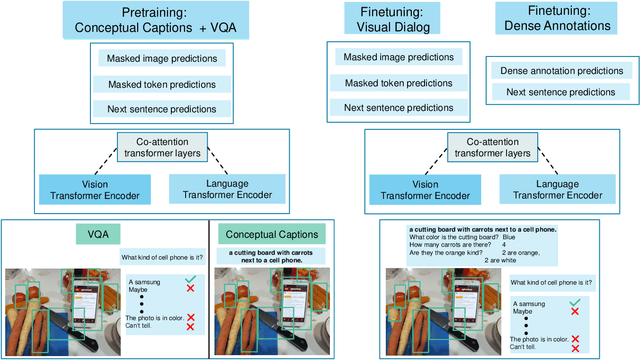

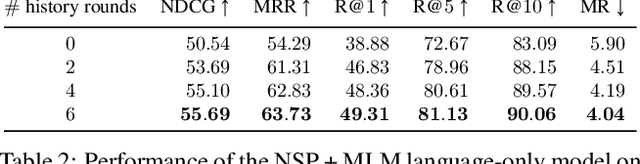
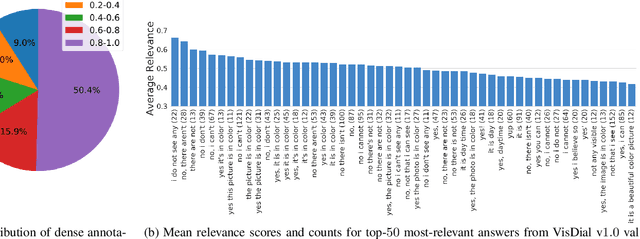
Prior work in visual dialog has focused on training deep neural models on the VisDial dataset in isolation, which has led to great progress, but is limiting and wasteful. In this work, following recent trends in representation learning for language, we introduce an approach to leverage pretraining on related large-scale vision-language datasets before transferring to visual dialog. Specifically, we adapt the recently proposed ViLBERT (Lu et al., 2019) model for multi-turn visually-grounded conversation sequences. Our model is pretrained on the Conceptual Captions and Visual Question Answering datasets, and finetuned on VisDial with a VisDial-specific input representation and the masked language modeling and next sentence prediction objectives (as in BERT). Our best single model achieves state-of-the-art on Visual Dialog, outperforming prior published work (including model ensembles) by more than 1% absolute on NDCG and MRR. Next, we carefully analyse our model and find that additional finetuning using 'dense' annotations i.e. relevance scores for all 100 answer options corresponding to each question on a subset of the training set, leads to even higher NDCG -- more than 10% over our base model -- but hurts MRR -- more than 17% below our base model! This highlights a stark trade-off between the two primary metrics for this task -- NDCG and MRR. We find that this is because dense annotations in the dataset do not correlate well with the original ground-truth answers to questions, often rewarding the model for generic responses (e.g. "can't tell").
Improving Generative Visual Dialog by Answering Diverse Questions
Oct 03, 2019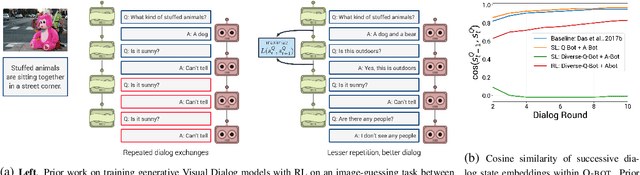

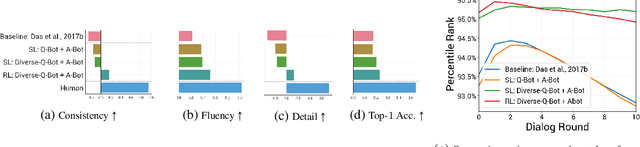

Prior work on training generative Visual Dialog models with reinforcement learning(Das et al.) has explored a Qbot-Abot image-guessing game and shown that this 'self-talk' approach can lead to improved performance at the downstream dialog-conditioned image-guessing task. However, this improvement saturates and starts degrading after a few rounds of interaction, and does not lead to a better Visual Dialog model. We find that this is due in part to repeated interactions between Qbot and Abot during self-talk, which are not informative with respect to the image. To improve this, we devise a simple auxiliary objective that incentivizes Qbot to ask diverse questions, thus reducing repetitions and in turn enabling Abot to explore a larger state space during RL ie. be exposed to more visual concepts to talk about, and varied questions to answer. We evaluate our approach via a host of automatic metrics and human studies, and demonstrate that it leads to better dialog, ie. dialog that is more diverse (ie. less repetitive), consistent (ie. has fewer conflicting exchanges), fluent (ie. more human-like),and detailed, while still being comparably image-relevant as prior work and ablations.
Unsupervised Discovery of Decision States for Transfer in Reinforcement Learning
Aug 15, 2019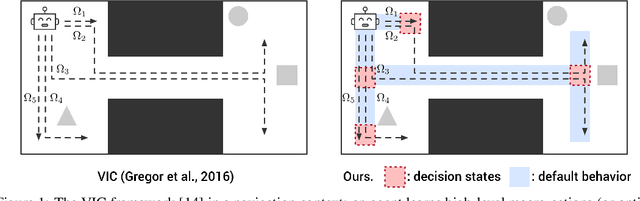
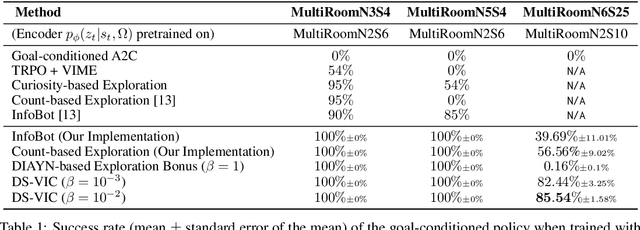
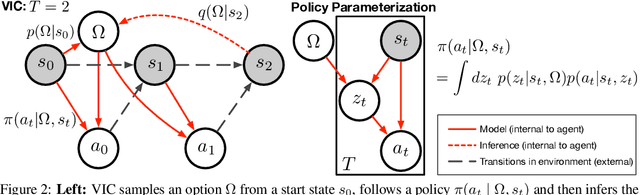
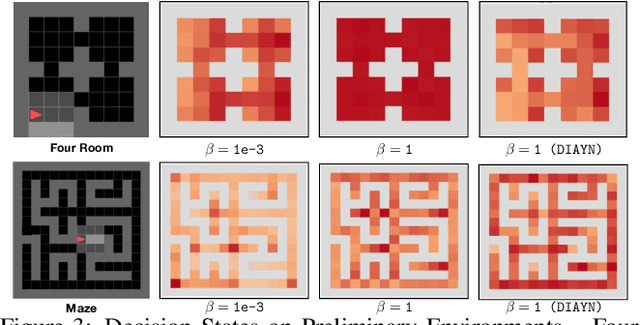
We present a hierarchical reinforcement learning (HRL) or options framework for identifying decision states. Informally speaking, these are states considered important by the agent's policy e.g. , for navigation, decision states would be crossroads or doors where an agent needs to make strategic decisions. While previous work (most notably Goyal et. al., 2019) discovers decision states in a task/goal specific (or 'supervised') manner, we do so in a goal-independent (or 'unsupervised') manner, i.e. entirely without any goal or extrinsic rewards. Our approach combines two hitherto disparate ideas - 1) \emph{intrinsic control} (Gregor et. al., 2016, Eysenbach et. al., 2018): learning a set of options that allow an agent to reliably reach a diverse set of states, and 2) \emph{information bottleneck} (Tishby et. al., 2000): penalizing mutual information between the option $\Omega$ and the states $s_t$ visited in the trajectory. The former encourages an agent to reliably explore the environment; the latter allows identification of decision states as the ones with high mutual information $I(\Omega; a_t | s_t)$ despite the bottleneck. Our results demonstrate that 1) our model learns interpretable decision states in an unsupervised manner, and 2) these learned decision states transfer to goal-driven tasks in new environments, effectively guide exploration, and improve performance.
Embodied Question Answering in Photorealistic Environments with Point Cloud Perception
Apr 06, 2019
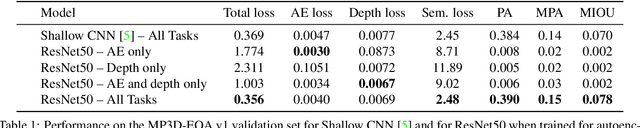
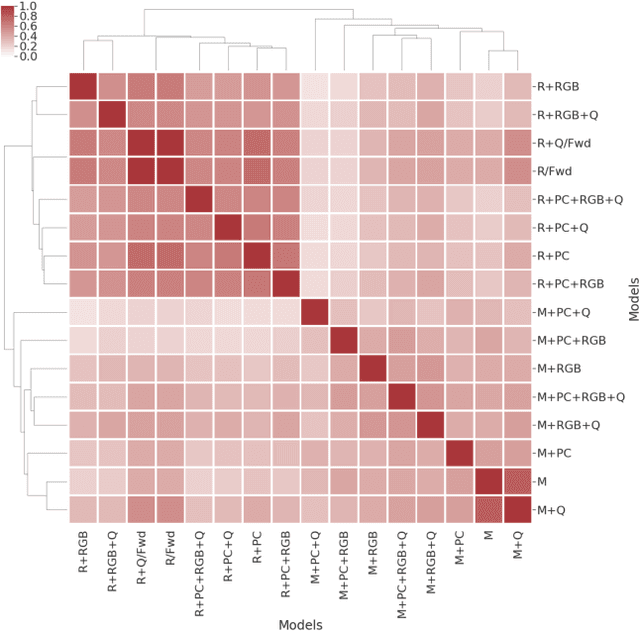
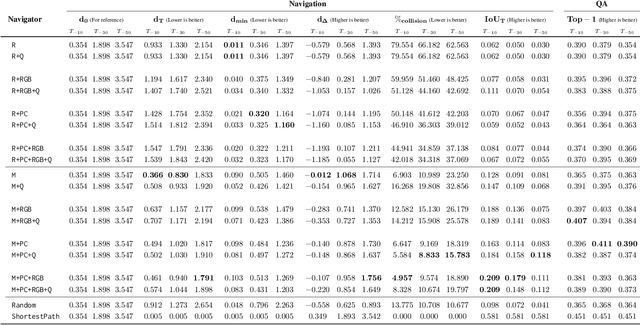
To help bridge the gap between internet vision-style problems and the goal of vision for embodied perception we instantiate a large-scale navigation task -- Embodied Question Answering [1] in photo-realistic environments (Matterport 3D). We thoroughly study navigation policies that utilize 3D point clouds, RGB images, or their combination. Our analysis of these models reveals several key findings. We find that two seemingly naive navigation baselines, forward-only and random, are strong navigators and challenging to outperform, due to the specific choice of the evaluation setting presented by [1]. We find a novel loss-weighting scheme we call Inflection Weighting to be important when training recurrent models for navigation with behavior cloning and are able to out perform the baselines with this technique. We find that point clouds provide a richer signal than RGB images for learning obstacle avoidance, motivating the use (and continued study) of 3D deep learning models for embodied navigation.
Audio-Visual Scene-Aware Dialog
Jan 25, 2019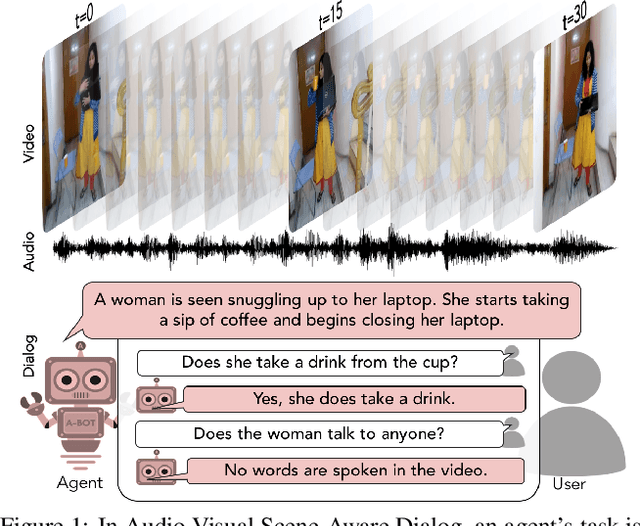
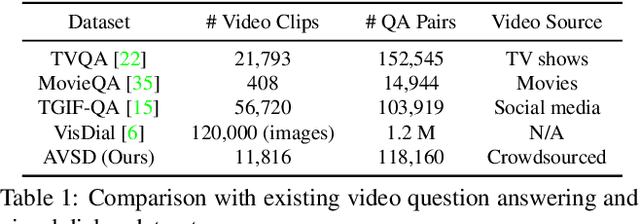


We introduce the task of scene-aware dialog. Given a follow-up question in an ongoing dialog about a video, our goal is to generate a complete and natural response to a question given (a) an input video, and (b) the history of previous turns in the dialog. To succeed, agents must ground the semantics in the video and leverage contextual cues from the history of the dialog to answer the question. To benchmark this task, we introduce the Audio Visual Scene-Aware Dialog (AVSD) dataset. For each of more than 11,000 videos of human actions for the Charades dataset. Our dataset contains a dialog about the video, plus a final summary of the video by one of the dialog participants. We train several baseline systems for this task and evaluate the performance of the trained models using several qualitative and quantitative metrics. Our results indicate that the models must comprehend all the available inputs (video, audio, question and dialog history) to perform well on this dataset.
Response to "Visual Dialogue without Vision or Dialogue"
Jan 16, 2019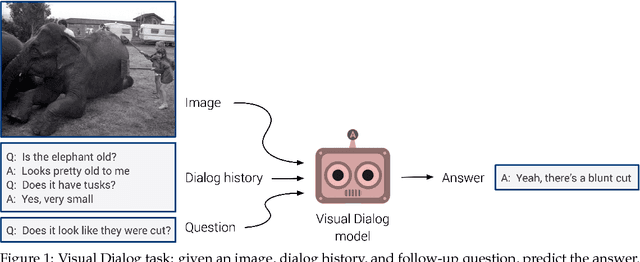
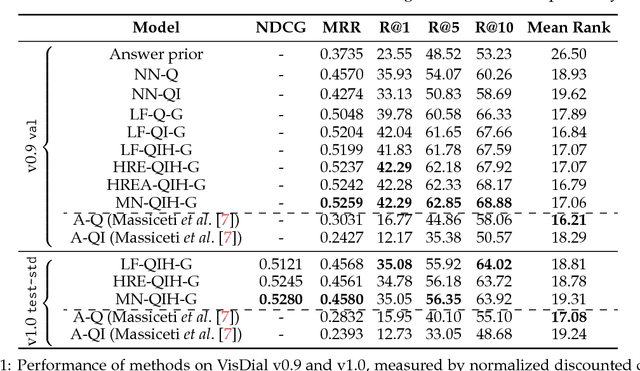
In a recent workshop paper, Massiceti et al. presented a baseline model and subsequent critique of Visual Dialog (Das et al., CVPR 2017) that raises what we believe to be unfounded concerns about the dataset and evaluation. This article intends to rebut the critique and clarify potential confusions for practitioners and future participants in the Visual Dialog challenge.