 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounce and Learn: Modeling Scene Dynamics with Real-World Bounces
Apr 15, 2019
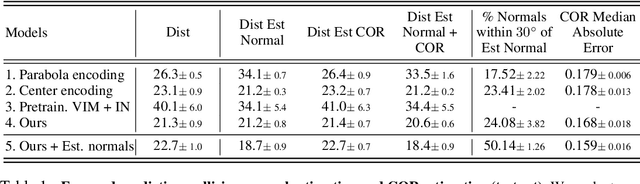
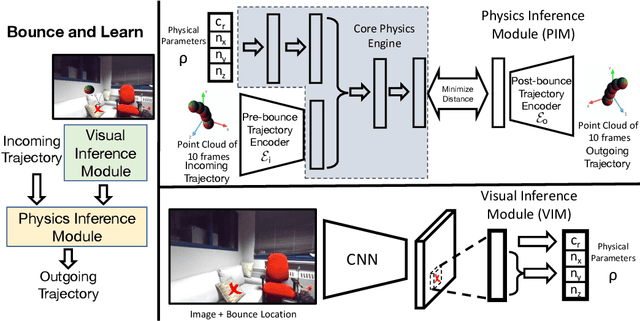
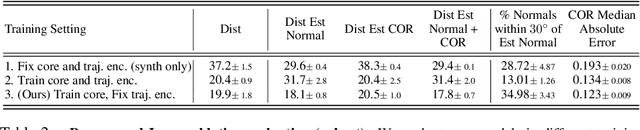
We introduce an approach to model surface properties governing bounces in everyday scenes. Our model learns end-to-end, starting from sensor inputs, to predict post-bounce trajectories and infer two underlying physical properties that govern bouncing - restitution and effective collision normals. Our model, Bounce and Learn, comprises two modules -- a Physics Inference Module (PIM) and a Visual Inference Module (VIM). VIM learns to infer physical parameters for locations in a scene given a single still image, while PIM learns to model physical interactions for the prediction task given physical parameters and observed pre-collision 3D trajectories. To achieve our results, we introduce the Bounce Dataset comprising 5K RGB-D videos of bouncing trajectories of a foam ball to probe surfaces of varying shapes and materials in everyday scenes including homes and offices. Our proposed model learns from our collected dataset of real-world bounces and is bootstrapped with additional information from simple physics simulations. We show on our newly collected dataset that our model out-performs baselines, including trajectory fitting with Newtonian physics, in predicting post-bounce trajectories and inferring physical properties of a scene.
Learning Exploration Policies for Navigation
Mar 05, 2019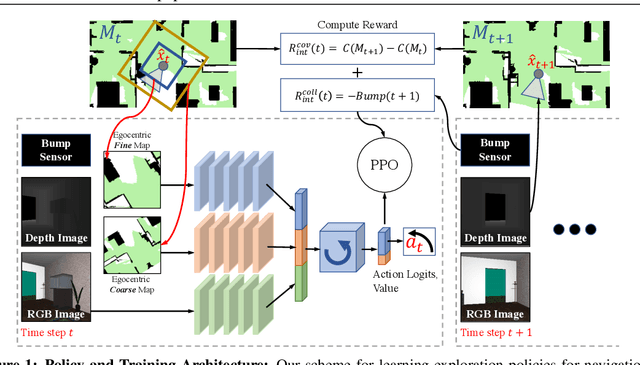
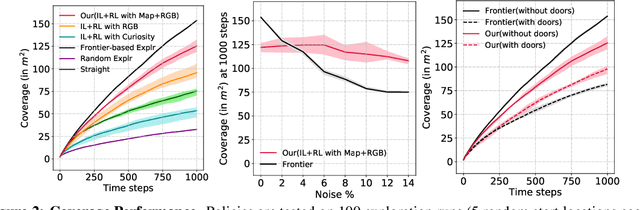
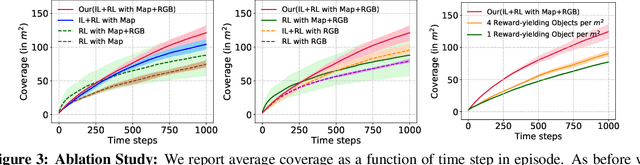
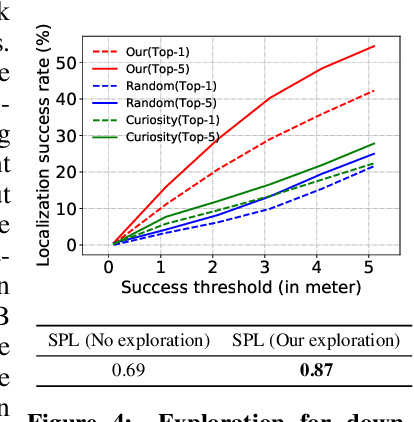
Numerous past works have tackled the problem of task-driven navigation. But, how to effectively explore a new environment to enable a variety of down-stream tasks has received much less attention. In this work, we study how agents can autonomously explore realistic and complex 3D environments without the context of task-rewards. We propose a learning-based approach and investigate different policy architectures, reward functions, and training paradigms. We find that the use of policies with spatial memory that are bootstrapped with imitation learning and finally finetuned with coverage rewards derived purely from on-board sensors can be effective at exploring novel environments. We show that our learned exploration policies can explore better than classical approaches based on geometry alone and generic learning-based exploration techniques. Finally, we also show how such task-agnostic exploration can be used for down-stream tasks. Code and Videos are available at: https://sites.google.com/view/exploration-for-nav.
Hardware Conditioned Policies for Multi-Robot Transfer Learning
Jan 13, 2019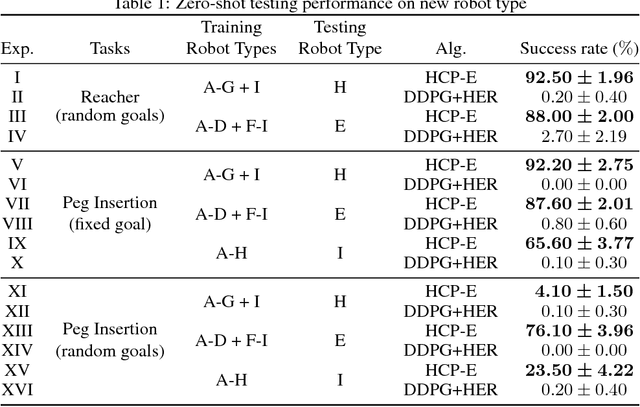
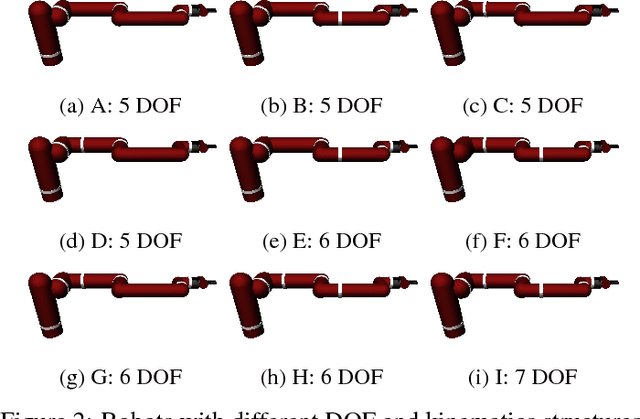
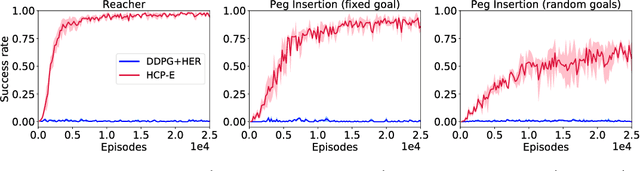
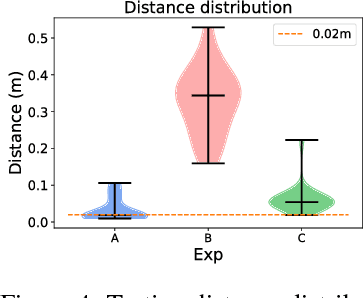
Deep reinforcement learning could be used to learn dexterous robotic policies but it is challenging to transfer them to new robots with vastly different hardware properties. It is also prohibitively expensive to learn a new policy from scratch for each robot hardware due to the high sample complexity of modern state-of-the-art algorithms. We propose a novel approach called \textit{Hardware Conditioned Policies} where we train a universal policy conditioned on a vector representation of robot hardware. We considered robots in simulation with varied dynamics, kinematic structure, kinematic lengths and degrees-of-freedom. First, we use the kinematic structure directly as the hardware encoding and show great zero-shot transfer to completely novel robots not seen during training. For robots with lower zero-shot success rate, we also demonstrate that fine-tuning the policy network is significantly more sample-efficient than training a model from scratch. In tasks where knowing the agent dynamics is important for success, we learn an embedding for robot hardware and show that policies conditioned on the encoding of hardware tend to generalize and transfer well. The code and videos are available on the project webpage: https://sites.google.com/view/robot-transfer-hcp.
Multiple Interactions Made Easy (MIME): Large Scale Demonstrations Data for Imitation
Oct 16, 2018
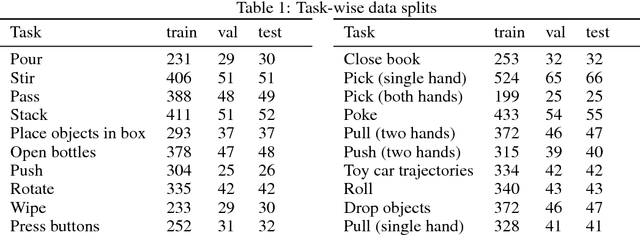

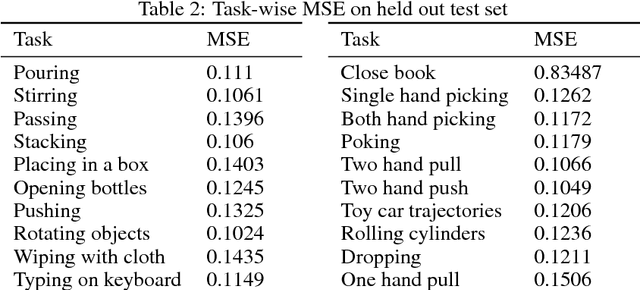
In recent years, we have seen an emergence of data-driven approaches in robotics. However, most existing efforts and datasets are either in simulation or focus on a single task in isolation such as grasping, pushing or poking. In order to make progress and capture the space of manipulation, we would need to collect a large-scale dataset of diverse tasks such as pouring, opening bottles, stacking objects etc. But how does one collect such a dataset? In this paper, we present the largest available robotic-demonstration dataset (MIME) that contains 8260 human-robot demonstrations over 20 different robotic tasks (https://sites.google.com/view/mimedataset). These tasks range from the simple task of pushing objects to the difficult task of stacking household objects. Our dataset consists of videos of human demonstrations and kinesthetic trajectories of robot demonstrations. We also propose to use this dataset for the task of mapping 3rd person video features to robot trajectories. Furthermore, we present two different approaches using this dataset and evaluate the predicted robot trajectories against ground-truth trajectories. We hope our dataset inspires research in multiple areas including visual imitation, trajectory prediction, and multi-task robotic learning.
Visual Semantic Navigation using Scene Priors
Oct 15, 2018
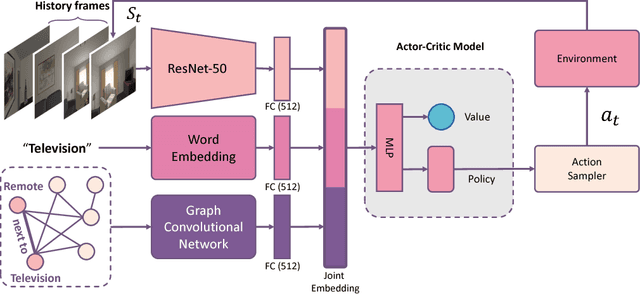
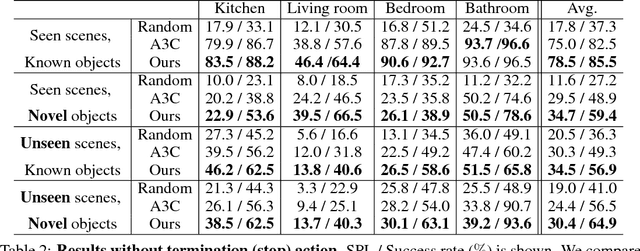
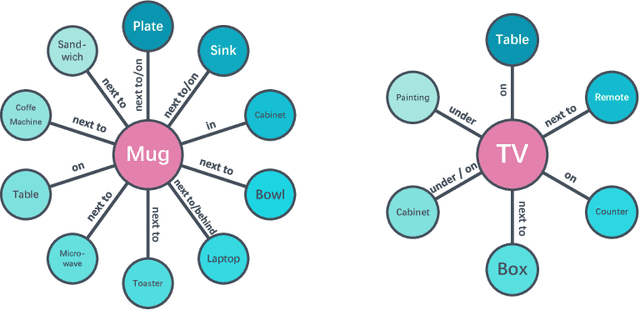
How do humans navigate to target objects in novel scenes? Do we use the semantic/functional priors we have built over years to efficiently search and navigate? For example, to search for mugs, we search cabinets near the coffee machine and for fruits we try the fridge. In this work, we focus on incorporating semantic priors in the task of semantic navigation. We propose to use Graph Convolutional Networks for incorporating the prior knowledge into a deep reinforcement learning framework. The agent uses the features from the knowledge graph to predict the actions. For evaluation, we use the AI2-THOR framework. Our experiments show how semantic knowledge improves performance significantly. More importantly, we show improvement in generalization to unseen scenes and/or objects. The supplementary video can be accessed at the following link: https://youtu.be/otKjuO805dE .
BOLD5000: A public fMRI dataset of 5000 images
Sep 05, 2018
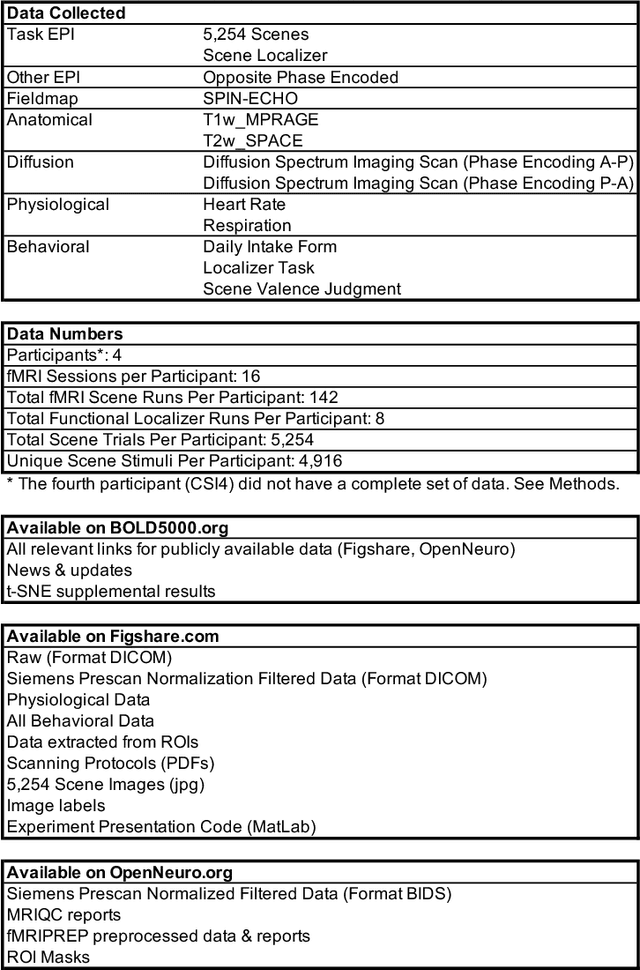
Vision science, particularly machine vision, has been revolutionized by introducing large-scale image datasets and statistical learning approaches. Yet, human neuroimaging studies of visual perception still rely on small numbers of images (around 100) due to time-constrained experimental procedures. To apply statistical learning approaches that integrate neuroscience, the number of images used in neuroimaging must be significantly increased. We present BOLD5000, a human functional MRI (fMRI) study that includes almost 5,000 distinct images depicting real-world scenes. Beyond dramatically increasing image dataset size relative to prior fMRI studies, BOLD5000 also accounts for image diversity, overlapping with standard computer vision datasets by incorporating images from the Scene UNderstanding (SUN), Common Objects in Context (COCO), and ImageNet datasets. The scale and diversity of these image datasets, combined with a slow event-related fMRI design, enable fine-grained exploration into the neural representation of a wide range of visual features, categories, and semantics. Concurrently, BOLD5000 brings us closer to realizing Marr's dream of a singular vision science - the intertwined study of biological and computer vision.
Interpretable Intuitive Physics Model
Aug 29, 2018

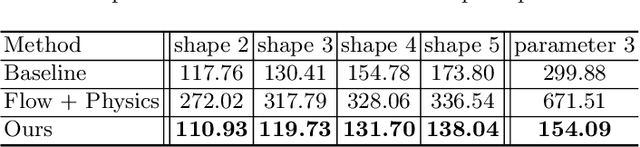
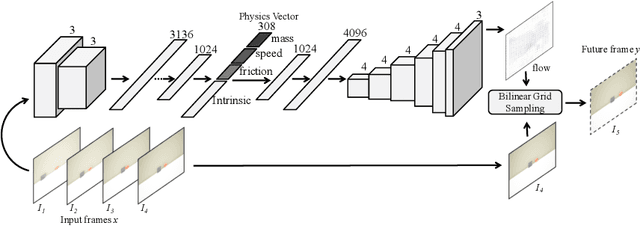
Humans have a remarkable ability to use physical commonsense and predict the effect of collisions. But do they understand the underlying factors? Can they predict if the underlying factors have changed? Interestingly, in most cases humans can predict the effects of similar collisions with different conditions such as changes in mass, friction, etc. It is postulated this is primarily because we learn to model physics with meaningful latent variables. This does not imply we can estimate the precise values of these meaningful variables (estimate exact values of mass or friction). Inspired by this observation, we propose an interpretable intuitive physics model where specific dimensions in the bottleneck layers correspond to different physical properties. In order to demonstrate that our system models these underlying physical properties, we train our model on collisions of different shapes (cube, cone, cylinder, spheres etc.) and test on collisions of unseen combinations of shapes. Furthermore, we demonstrate our model generalizes well even when similar scenes are simulated with different underlying properties.
Robot Learning in Homes: Improving Generalization and Reducing Dataset Bias
Jul 18, 2018
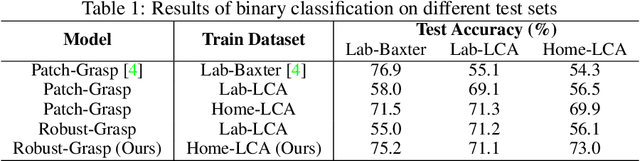
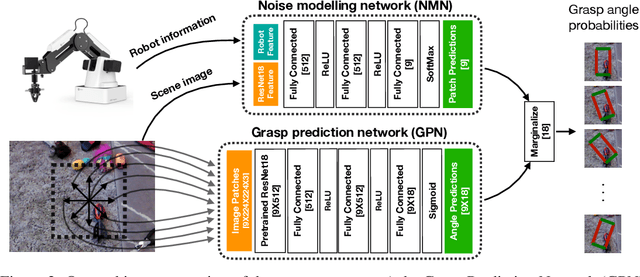
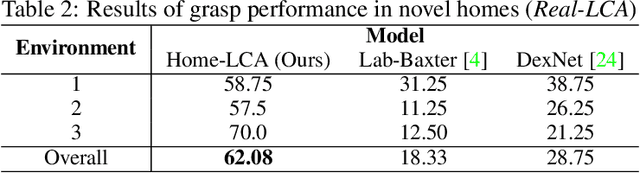
Data-driven approaches to solving robotic tasks have gained a lot of traction in recent years. However, most existing policies are trained on large-scale datasets collected in curated lab settings. If we aim to deploy these models in unstructured visual environments like people's homes, they will be unable to cope with the mismatch in data distribution. In such light, we present the first systematic effort in collecting a large dataset for robotic grasping in homes. First, to scale and parallelize data collection, we built a low cost mobile manipulator assembled for under 3K USD. Second, data collected using low cost robots suffer from noisy labels due to imperfect execution and calibration errors. To handle this, we develop a framework which factors out the noise as a latent variable. Our model is trained on 28K grasps collected in several houses under an array of different environmental conditions. We evaluate our models by physically executing grasps on a collection of novel objects in multiple unseen homes. The models trained with our home dataset showed a marked improvement of 43.7% over a baseline model trained with data collected in lab. Our architecture which explicitly models the latent noise in the dataset also performed 10% better than one that did not factor out the noise. We hope this effort inspires the robotics community to look outside the lab and embrace learning based approaches to handle inaccurate cheap robots.
Learning 6-DOF Grasping Interaction via Deep Geometry-aware 3D Representations
Jun 15, 2018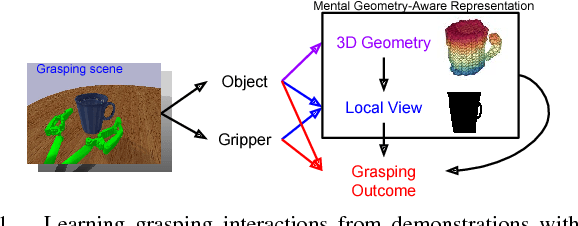
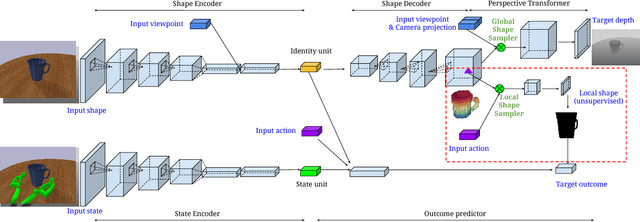
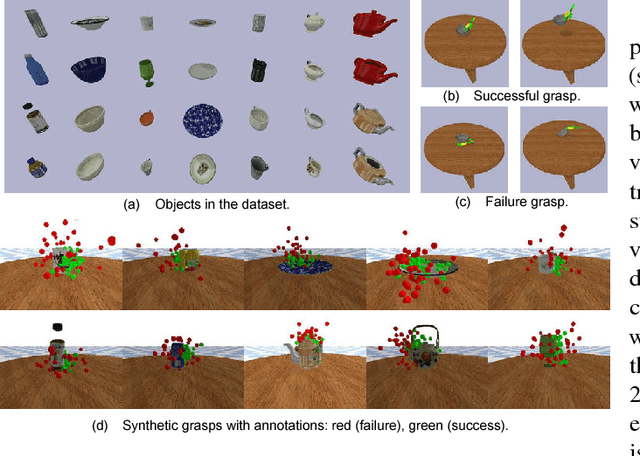
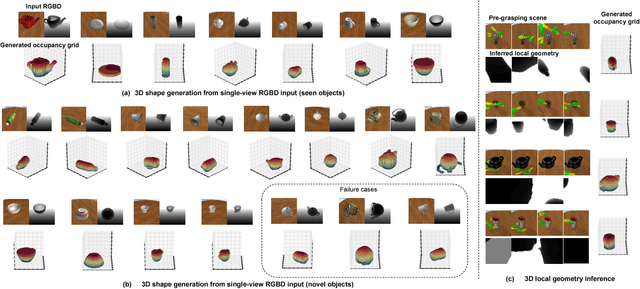
This paper focuses on the problem of learning 6-DOF grasping with a parallel jaw gripper in simulation. We propose the notion of a geometry-aware representation in grasping based on the assumption that knowledge of 3D geometry is at the heart of interaction. Our key idea is constraining and regularizing grasping interaction learning through 3D geometry prediction. Specifically, we formulate the learning of deep geometry-aware grasping model in two steps: First, we learn to build mental geometry-aware representation by reconstructing the scene (i.e., 3D occupancy grid) from RGBD input via generative 3D shape modeling. Second, we learn to predict grasping outcome with its internal geometry-aware representation. The learned outcome prediction model is used to sequentially propose grasping solutions via analysis-by-synthesis optimization. Our contributions are fourfold: (1) To best of our knowledge, we are presenting for the first time a method to learn a 6-DOF grasping net from RGBD input; (2) We build a grasping dataset from demonstrations in virtual reality with rich sensory and interaction annotations. This dataset includes 101 everyday objects spread across 7 categories, additionally, we propose a data augmentation strategy for effective learning; (3) We demonstrate that the learned geometry-aware representation leads to about 10 percent relative performance improvement over the baseline CNN on grasping objects from our dataset. (4) We further demonstrate that the model generalizes to novel viewpoints and object instances.
Videos as Space-Time Region Graphs
Jun 05, 2018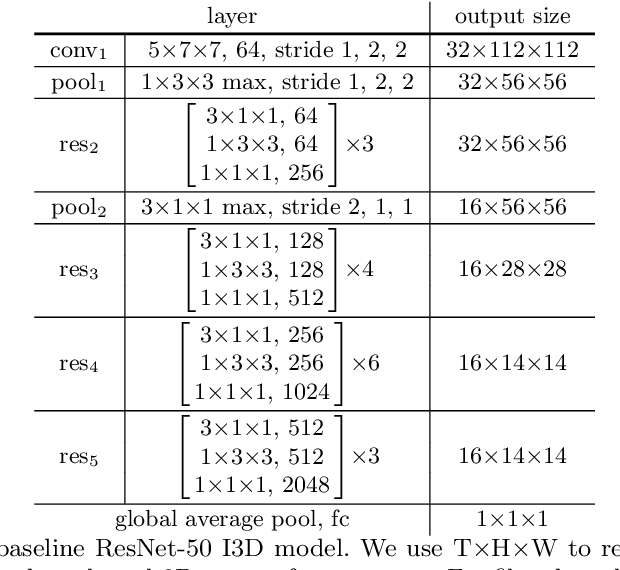
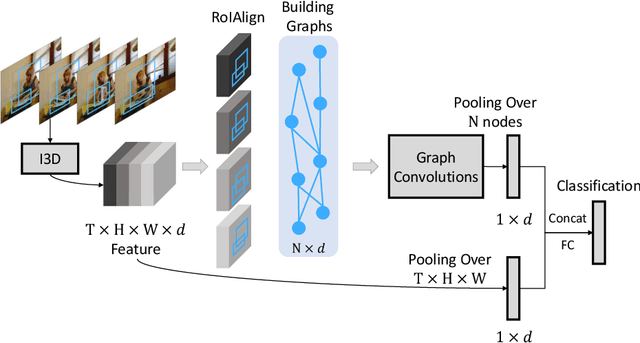


How do humans recognize the action "opening a book" ? We argue that there are two important cues: modeling temporal shape dynamics and modeling functional relationships between humans and objects. In this paper, we propose to represent videos as space-time region graphs which capture these two important cues. Our graph nodes are defined by the object region proposals from different frames in a long range video. These nodes are connected by two types of relations: (i) similarity relations capturing the long range dependencies between correlated objects and (ii) spatial-temporal relations capturing the interactions between nearby objects. We perform reasoning on this graph representation via Graph Convolutional Networks. We achieve state-of-the-art results on both Charades and Something-Something datasets. Especially for Charades, we obtain a huge 4.4% gain when our model is applied in complex environments.