 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Interactions Made Easy (MIME): Large Scale Demonstrations Data for Imitation
Paper and Code
Oct 16, 2018
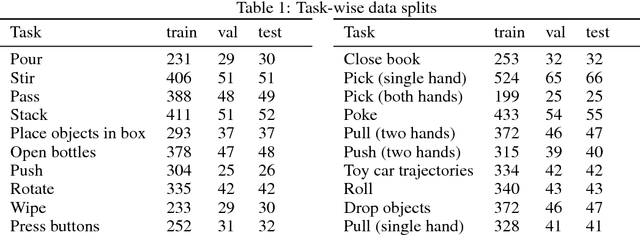

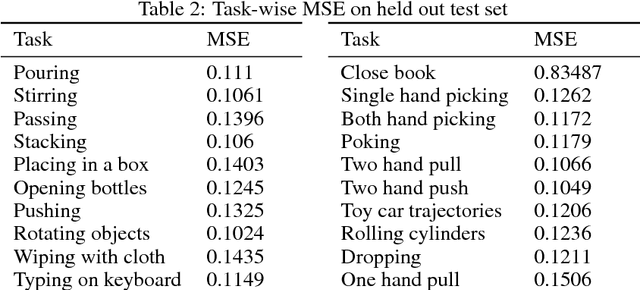
In recent years, we have seen an emergence of data-driven approaches in robotics. However, most existing efforts and datasets are either in simulation or focus on a single task in isolation such as grasping, pushing or poking. In order to make progress and capture the space of manipulation, we would need to collect a large-scale dataset of diverse tasks such as pouring, opening bottles, stacking objects etc. But how does one collect such a dataset? In this paper, we present the largest available robotic-demonstration dataset (MIME) that contains 8260 human-robot demonstrations over 20 different robotic tasks (https://sites.google.com/view/mimedataset). These tasks range from the simple task of pushing objects to the difficult task of stacking household objects. Our dataset consists of videos of human demonstrations and kinesthetic trajectories of robot demonstrations. We also propose to use this dataset for the task of mapping 3rd person video features to robot trajectories. Furthermore, we present two different approaches using this dataset and evaluate the predicted robot trajectories against ground-truth trajectories. We hope our dataset inspires research in multiple areas including visual imitation, trajectory prediction, and multi-task robotic learning.