 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ZR-2021VG: Zero-Resource Speech Challenge, Visually-Grounded Language Modelling track, 2021 edition
Jul 14, 2021
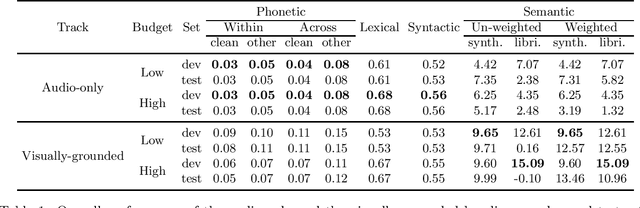
We present the visually-grounded language modelling track that was introduced in the Zero-Resource Speech challenge, 2021 edition, 2nd round. We motivate the new track and discuss participation rules in detail. We also present the two baseline systems that were developed for this track.
Stacked Acoustic-and-Textual Encoding: Integrating the Pre-trained Models into Speech Translation Encoders
May 12, 2021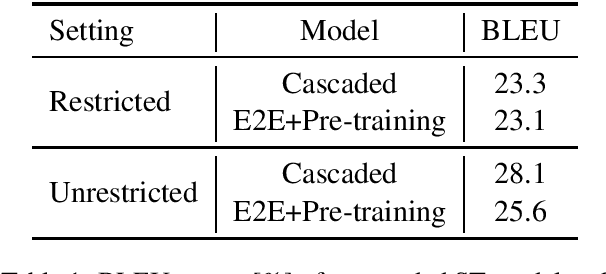
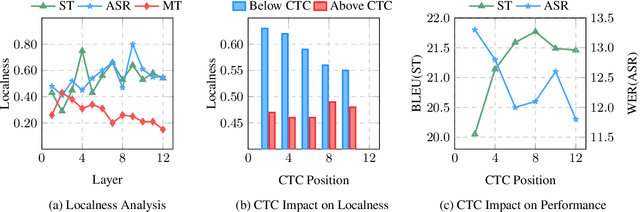
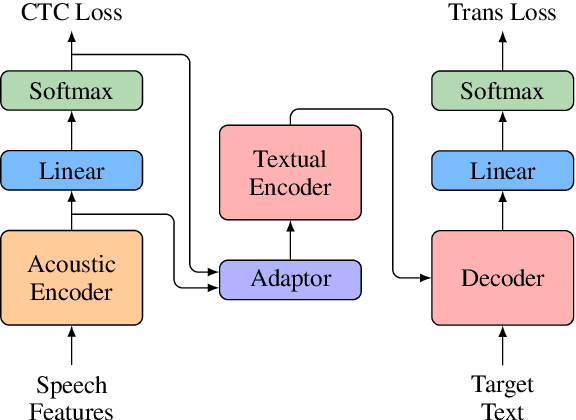
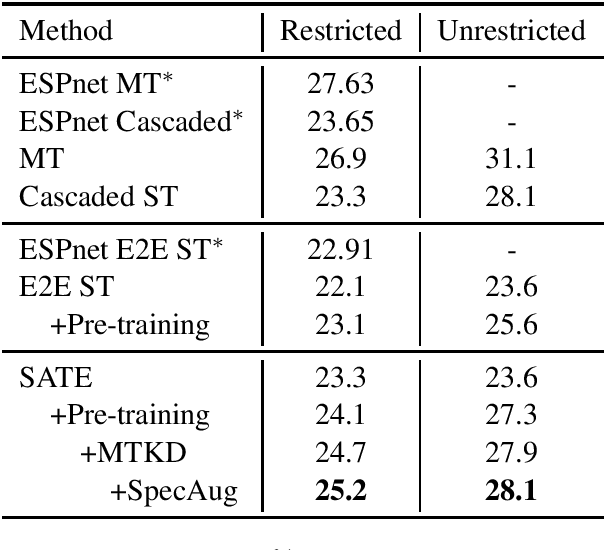
Encoder pre-training is promising in end-to-end Speech Translation (ST), given the fact that speech-to-translation data is scarce. But ST encoders are not simple instances of Automatic Speech Recognition (ASR) or Machine Translation (MT) encoders. For example, we find ASR encoders lack the global context representation, which is necessary for translation, whereas MT encoders are not designed to deal with long but locally attentive acoustic sequences. In this work, we propose a Stacked Acoustic-and-Textual Encoding (SATE) method for speech translation. Our encoder begins with processing the acoustic sequence as usual, but later behaves more like an MT encoder for a global representation of the input sequence. In this way, it is straightforward to incorporate the pre-trained models into the system. Also, we develop an adaptor module to alleviate the representation inconsistency between the pre-trained ASR encoder and MT encoder, and a multi-teacher knowledge distillation method to preserve the pre-training knowledge. Experimental results on the LibriSpeech En-Fr and MuST-C En-De show that our method achieves the state-of-the-art performance of 18.3 and 25.2 BLEU points. To our knowledge, we are the first to develop an end-to-end ST system that achieves comparable or even better BLEU performance than the cascaded ST counterpart when large-scale ASR and MT data is available.
Gender Bias in Word Embeddings: A Comprehensive Analysis of Frequency, Syntax, and Semantics
Jun 07, 2022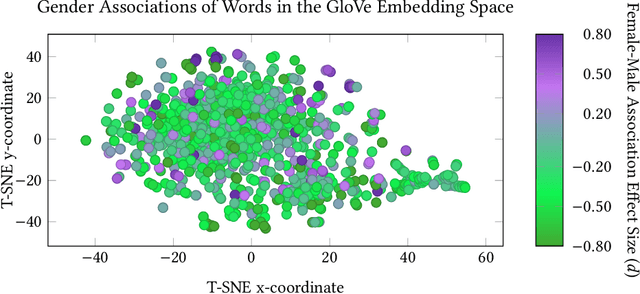
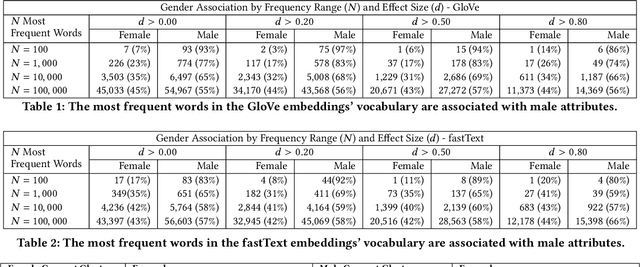
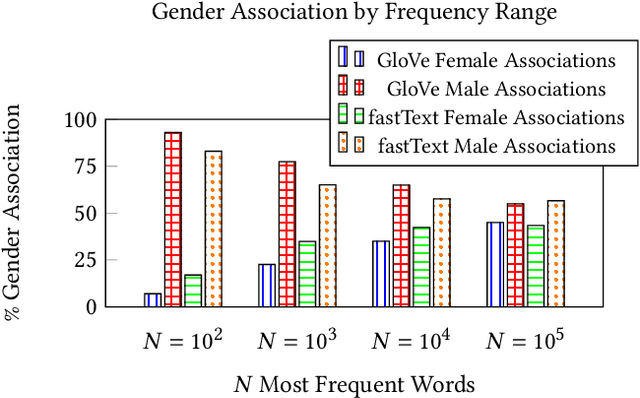
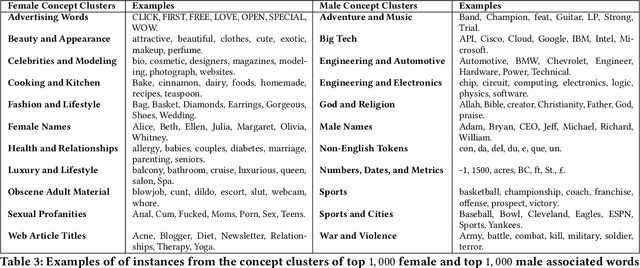
The statistical regularities in language corpora encode well-known social biases into word embeddings. Here, we focus on gender to provide a comprehensive analysis of group-based biases in widely-used static English word embeddings trained on internet corpora (GloVe 2014, fastText 2017). Using the Single-Category Word Embedding Association Test, we demonstrate the widespread prevalence of gender biases that also show differences in: (1) frequencies of words associated with men versus women; (b) part-of-speech tags in gender-associated words; (c) semantic categories in gender-associated words; and (d) valence, arousal, and dominance in gender-associated words. First, in terms of word frequency: we find that, of the 1,000 most frequent words in the vocabulary, 77% are more associated with men than women, providing direct evidence of a masculine default in the everyday language of the English-speaking world. Second, turning to parts-of-speech: the top male-associated words are typically verbs (e.g., fight, overpower) while the top female-associated words are typically adjectives and adverbs (e.g., giving, emotionally). Gender biases in embeddings also permeate parts-of-speech. Third, for semantic categories: bottom-up, cluster analyses of the top 1,000 words associated with each gender. The top male-associated concepts include roles and domains of big tech, engineering, religion, sports, and violence; in contrast, the top female-associated concepts are less focused on roles, including, instead, female-specific slurs and sexual content, as well as appearance and kitchen terms. Fourth, using human ratings of word valence, arousal, and dominance from a ~20,000 word lexicon, we find that male-associated words are higher on arousal and dominance, while female-associated words are higher on valence.
MFFCN: Multi-layer Feature Fusion Convolution Network for Audio-visual Speech Enhancement
Feb 04, 2021
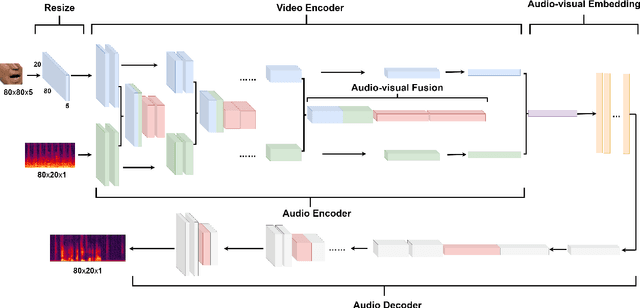
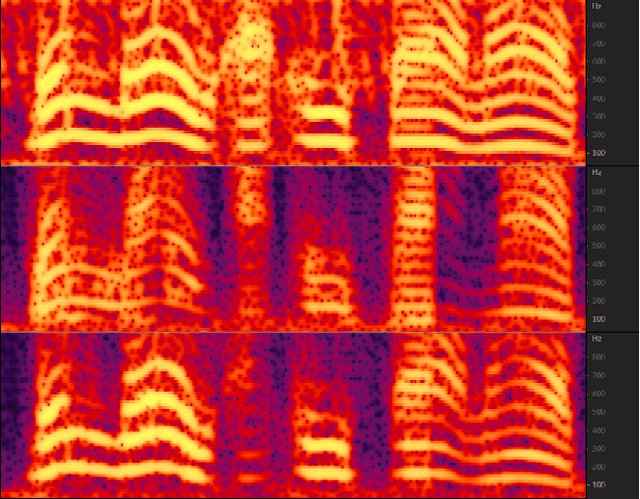
The purpose of speech enhancement is to extract target speech signal from a mixture of sounds generated from several sources. Speech enhancement can potentially benefit from the visual information from the target speaker, such as lip move-ment and facial expressions, because the visual aspect of speech isessentially unaffected by acoustic environment. In order to fuse audio and visual information, an audio-visual fusion strategy is proposed, which goes beyond simple feature concatenation and learns to automatically align the two modalities, leading to more powerful representation which increase intelligibility in noisy conditions. The proposed model fuses audio-visual featureslayer by layer, and feed these audio-visual features to each corresponding decoding layer. Experiment results show relative improvement from 6% to 24% on test sets over the audio modalityalone, depending on audio noise level. Moreover, there is a significant increase of PESQ from 1.21 to 2.06 in our -15 dB SNR experiment.
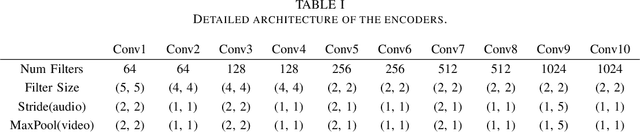
Machine Learning based COVID-19 Detection from Smartphone Recordings: Cough, Breath and Speech
Apr 12, 2021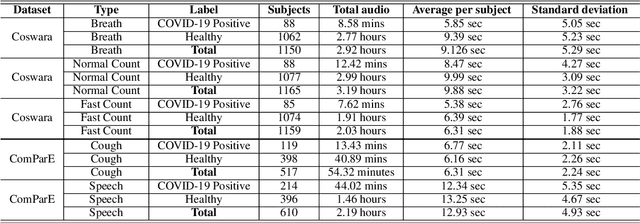
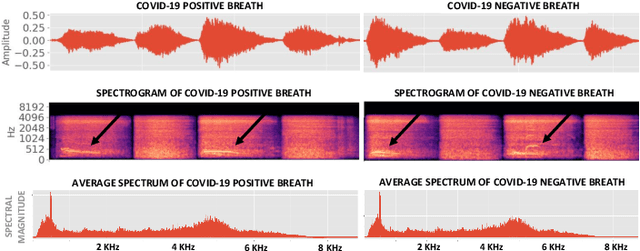
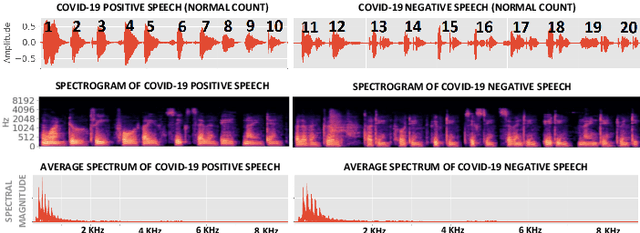
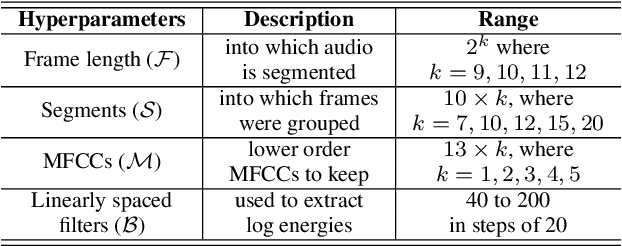
We present an experimental investigation into the automatic detection of COVID-19 from smartphone recordings of coughs, breaths and speech. This type of screening is attractive because it is non-contact, does not require specialist medical expertise or laboratory facilities and can easily be deployed on inexpensive consumer hardware. We base our experiments on two datasets, Coswara and ComParE, containing recordings of coughing, breathing and speech from subjects around the globe. We have considered seven machine learning classifiers and all of them are trained and evaluated using leave-p-out cross-validation. For the Coswara data, the highest AUC of 0.92 was achieved using a Resnet50 architecture on breaths. For the ComParE data, the highest AUC of 0.93 was achieved using a k-nearest neighbours (KNN) classifier on cough recordings after selecting the best 12 features using sequential forward selection (SFS) and the highest AUC of 0.91 was also achieved on speech by a multilayer perceptron (MLP) when using SFS to select the best 23 features. We conclude that among all vocal audio, coughs carry the strongest COVID-19 signature followed by breath and speech. Although these signatures are not perceivable by human ear, machine learning based COVID-19 detection is possible from vocal audio recorded via smartphone.
FlexLip: A Controllable Text-to-Lip System
Jun 07, 2022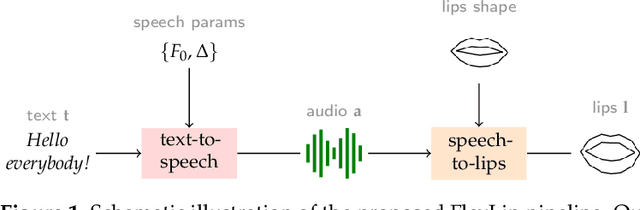
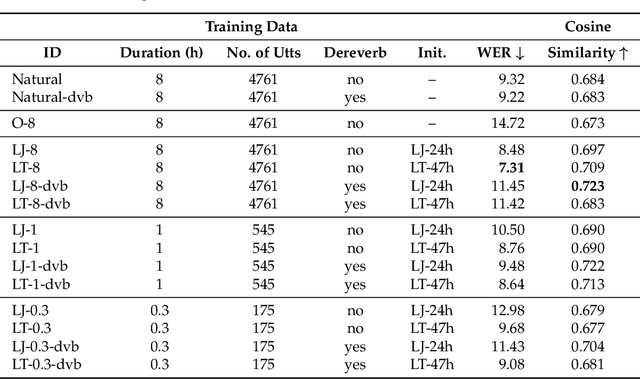


The task of converting text input into video content is becoming an important topic for synthetic media generation. Several methods have been proposed with some of them reaching close-to-natural performances in constrained tasks. In this paper, we tackle a subissue of the text-to-video generation problem, by converting the text into lip landmarks. However, we do this using a modular, controllable system architecture and evaluate each of its individual components. Our system, entitled FlexLip, is split into two separate modules: text-to-speech and speech-to-lip, both having underlying controllable deep neural network architectures. This modularity enables the easy replacement of each of its components, while also ensuring the fast adaptation to new speaker identities by disentangling or projecting the input features. We show that by using as little as 20 min of data for the audio generation component, and as little as 5 min for the speech-to-lip component, the objective measures of the generated lip landmarks are comparable with those obtained when using a larger set of training samples. We also introduce a series of objective evaluation measures over the complete flow of our system by taking into consideration several aspects of the data and system configuration. These aspects pertain to the quality and amount of training data, the use of pretrained models, and the data contained therein, as well as the identity of the target speaker; with regard to the latter, we show that we can perform zero-shot lip adaptation to an unseen identity by simply updating the shape of the lips in our model.
* 16 pages, 4 tables, 4 figures
Measuring the Impact of Individual Domain Factors in Self-Supervised Pre-Training
Mar 02, 2022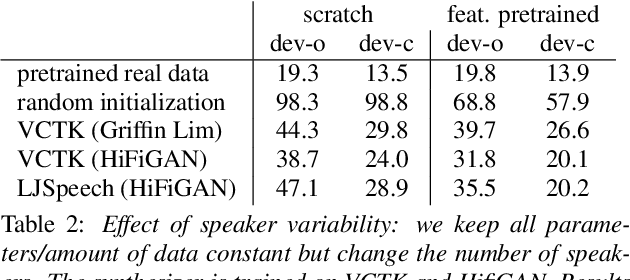
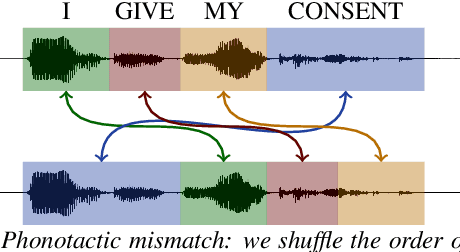
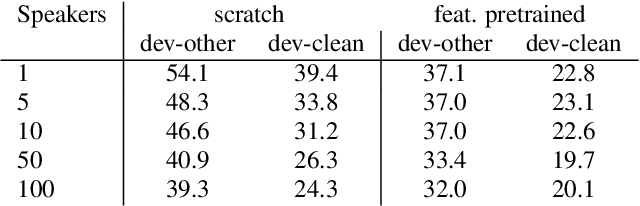

Human speech data comprises a rich set of domain factors such as accent, syntactic and semantic variety, or acoustic environment. Previous work explores the effect of domain mismatch in automatic speech recognition between pre-training and fine-tuning as a whole but does not dissect the contribution of individual factors. In this paper, we present a controlled study to better understand the effect of such factors on the performance of pre-trained representations. To do so, we pre-train models either on modified natural speech or synthesized audio, with a single domain factor modified, and then measure performance on automatic speech recognition after fine tuning. Results show that phonetic domain factors play an important role during pre-training while grammatical and syntactic factors are far less important. To our knowledge, this is the first study to better understand the domain characteristics in self-supervised pre-training for speech.
Consistent Training and Decoding For End-to-end Speech Recognition Using Lattice-free MMI
Dec 05, 2021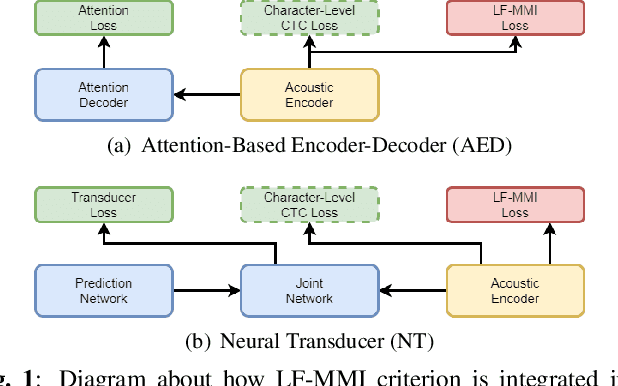
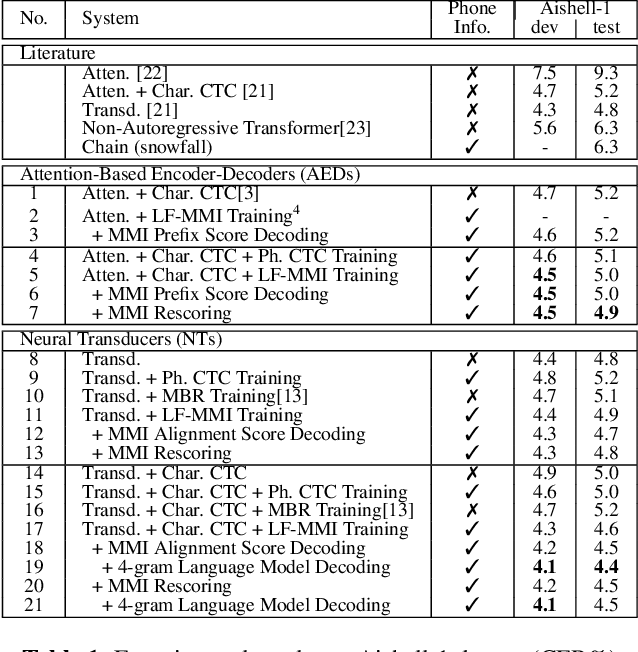
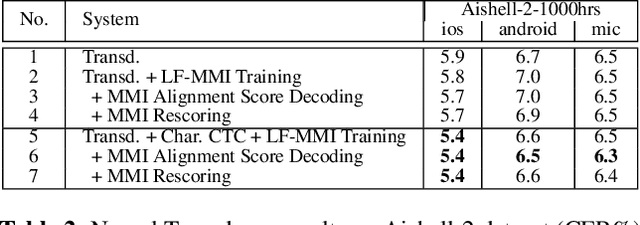
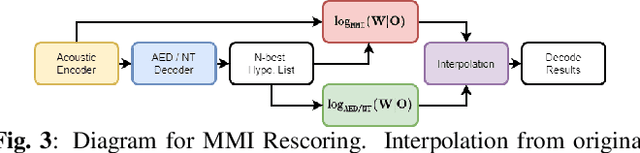
Recently, End-to-End (E2E) frameworks have achieved remarkable results on various Automatic Speech Recognition (ASR) tasks. However, Lattice-Free Maximum Mutual Information (LF-MMI), as one of the discriminative training criteria that show superior performance in hybrid ASR systems, is rarely adopted in E2E ASR frameworks. In this work, we propose a novel approach to integrate LF-MMI criterion into E2E ASR frameworks in both training and decoding stages. The proposed approach shows its effectiveness on two of the most widely used E2E frameworks including Attention-Based Encoder-Decoders (AEDs) and Neural Transducers (NTs). Experiments suggest that the introduction of the LF-MMI criterion consistently leads to significant performance improvements on various datasets and different E2E ASR frameworks. The best of our models achieves competitive CER of 4.1\% / 4.4\% on Aishell-1 dev/test set; we also achieve significant error reduction on Aishell-2 and Librispeech datasets over strong baselines.
Model Blending for Text Classification
Aug 05, 2022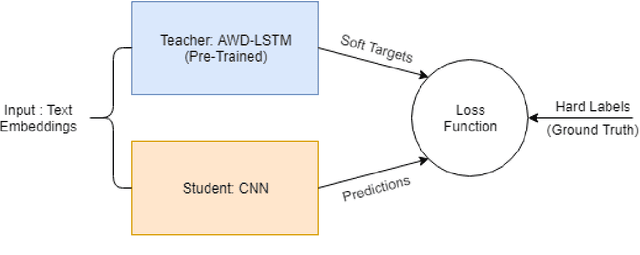
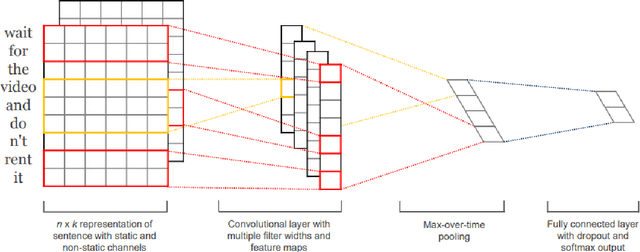
Deep neural networks (DNNs) have proven successful in a wide variety of applications such as speech recognition and synthesis, computer vision, machine translation, and game playing, to name but a few. However, existing deep neural network models are computationally expensive and memory intensive, hindering their deployment in devices with low memory resources or in applications with strict latency requirements. Therefore, a natural thought is to perform model compression and acceleration in deep networks without significantly decreasing the model performance, which is what we call reducing the complexity. In the following work, we try reducing the complexity of state of the art LSTM models for natural language tasks such as text classification, by distilling their knowledge to CNN based models, thus reducing the inference time(or latency) during testing.
Speaking-Rate-Controllable HiFi-GAN Using Feature Interpolation
Apr 22, 2022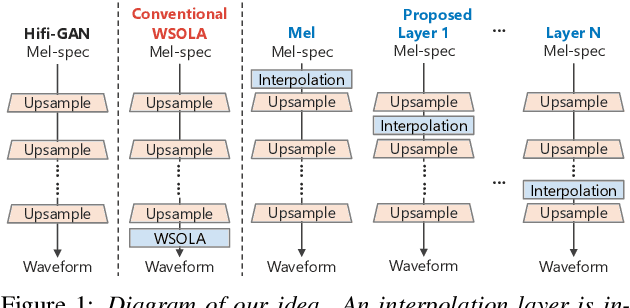

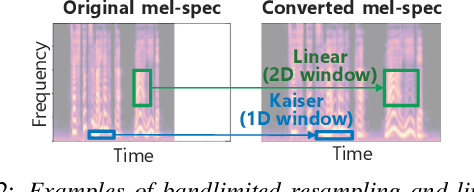
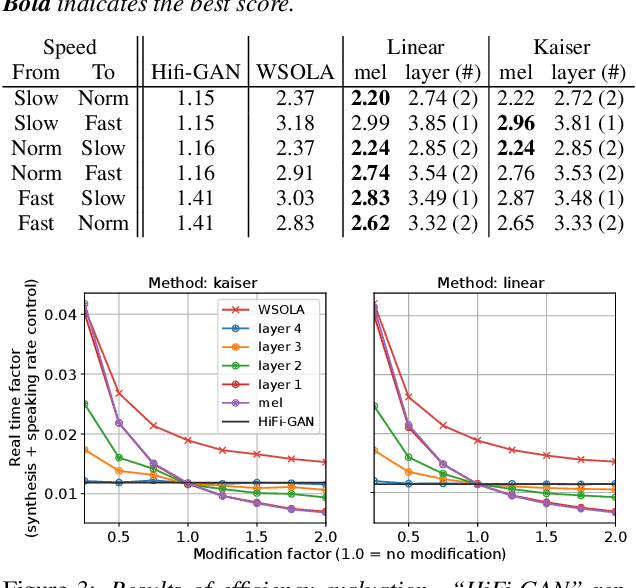
This paper presents a speaking-rate-controllable HiFi-GAN neural vocoder. Original HiFi-GAN is a high-fidelity, computationally efficient, and tiny-footprint neural vocoder. We attempt to incorporate a speaking rate control function into HiFi-GAN for improving the accessibility of synthetic speech. The proposed method inserts a differentiable interpolation layer into the HiFi-GAN architecture. A signal resampling method and an image scaling method are implemented in the proposed method to warp the mel-spectrograms or hidden features of the neural vocoder. We also design and open-source a Japanese speech corpus containing three kinds of speaking rates to evaluate the proposed speaking rate control method. Experimental results of comprehensive objective and subjective evaluations demonstrate that 1) the proposed method outperforms a baseline time-scale modification algorithm in speech naturalness, 2) warping mel-spectrograms by image scaling obtained the best performance among all proposed methods, and 3) the proposed speaking rate control method can be incorporated into HiFi-GAN without losing computational efficiency.