 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Analysis for Quality of Multilingual Synthesized Speech
Sep 05, 2025While supervised quality predictors for synthesized speech have demonstrated strong correlations with human ratings, their requirement for in-domain labeled training data hinders their generalization ability to new domains. Unsupervised approaches based on pretrained self-supervised learning (SSL) based models and automatic speech recognition (ASR) models are a promising alternative; however, little is known about how these models encode information about speech quality. Towards the goal of better understanding how different aspects of speech quality are encoded in a multilingual setting, we present a layer-wise analysis of multilingual pretrained speech models based on reference modeling. We find that features extracted from early SSL layers show correlations with human ratings of synthesized speech, and later layers of ASR models can predict quality of non-neural systems as well as intelligibility. We also demonstrate the importance of using well-matched reference data.
Speaking-Rate-Controllable HiFi-GAN Using Feature Interpolation
Apr 22, 2022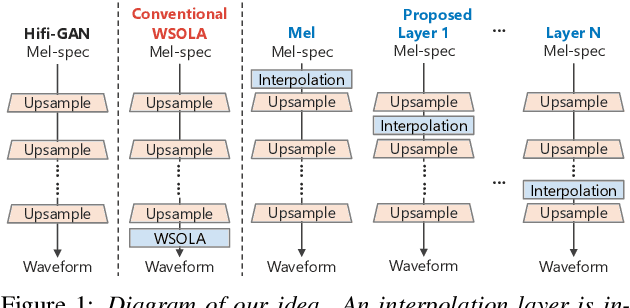

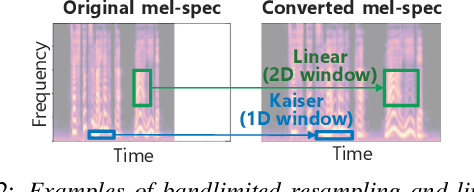
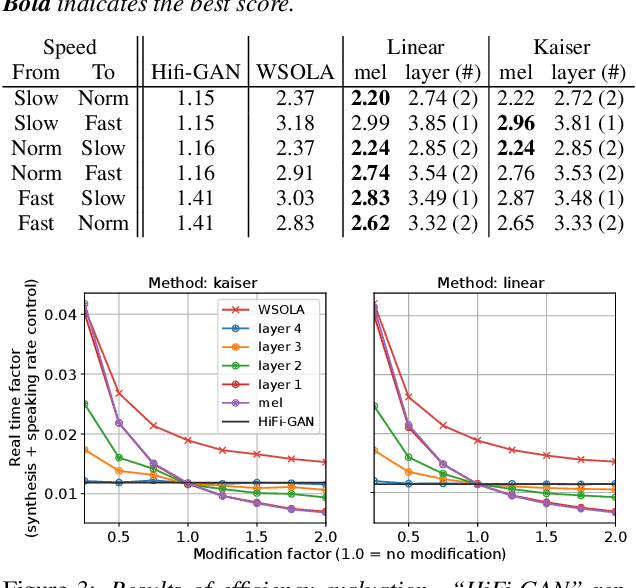
This paper presents a speaking-rate-controllable HiFi-GAN neural vocoder. Original HiFi-GAN is a high-fidelity, computationally efficient, and tiny-footprint neural vocoder. We attempt to incorporate a speaking rate control function into HiFi-GAN for improving the accessibility of synthetic speech. The proposed method inserts a differentiable interpolation layer into the HiFi-GAN architecture. A signal resampling method and an image scaling method are implemented in the proposed method to warp the mel-spectrograms or hidden features of the neural vocoder. We also design and open-source a Japanese speech corpus containing three kinds of speaking rates to evaluate the proposed speaking rate control method. Experimental results of comprehensive objective and subjective evaluations demonstrate that 1) the proposed method outperforms a baseline time-scale modification algorithm in speech naturalness, 2) warping mel-spectrograms by image scaling obtained the best performance among all proposed methods, and 3) the proposed speaking rate control method can be incorporated into HiFi-GAN without losing computational efficiency.